本人硕士研究生研究课题:弱监督学习框架下的全卷积神经网络图像语义分割
2018年1月16日,学院开题答辩,定下了这个题目。
今天是2018年6月10日。到现在,包括中间的寒假,五个月过去了,看一下当下的状况,并无任何进展,当然说的是课题方面。因为答辩之后贪玩的暂时解放心理,因为各种其他事情需要兼顾(我觉得这可能是借口吧),因为意志不坚,自从定完题目,好像再也没有深入研究下去,而是搁置一旁,去做其他学业上的事情了(这就牵涉到思维方式、科研与学习方法的问题)。
心无旁骛是如此的重要,温水煮青蛙所导致的危险后果是如此的明显,“生于忧患,死于安乐”。
距秋招还有不到三个月,这三个月给自己立个flag,必须一定要心无旁骛,以研究课题为中心,该好好做点事情了,研三毕业的师兄说,一定要注意时间节点,什么时候该完成什么,一定要去完成,错过那个时间点,新的别的事情会让你失措,能力是通过在一定时间节点上的卓有成效彰显出来的,否则就是一个不会自我管理的失败者。惰性作为人性中能轻易毁掉一个人的弱点之一,及时意识到,时常问自己,当下在做的事是不是最重要的,及时跳出舒适区,避免陷入温水青蛙的境地。现在就是最早的时候,三个月,无问西东,但求无愧我心。自律+坚定+灵活应对(不钻牛角尖)!
今天再次回顾了一下“语义分割中的弱监督学习”,参见https://blog.csdn.net/XWUkefr2tnh4/article/details/78734093。我的目的就是使用弱监督学习方法解决图像语义分割问题。算法,网络,所用技术,比如AE(Adversarial erasing)、PSL(prohibitive segmentation learning)等等,可以自己看看链接内容,最后关注到了作者说未来会集中于两个方面的研究:
1)同时的弱监督物体检测和语义分割,这两个任务可能会相互促进;
2) 半监督的物体检测和语义分割。
虽然现在的弱监督方法取得了一定的成绩,但是和全监督方法还有一定的差距。作者希望通过结合更多弱监督的标注样本和现有的少量的标注样本通过半监督的方式训练出性能更好的语义分割模型。
另外学习了程明明老师的“面向弱监督的图像理解”,参见https://blog.csdn.net/xwukefr2tnh4/article/details/78955546。
先来看一段诗:
若言琴上有琴声,放在匣中何不鸣?
若言声在指头上,何不于君指上听?
苏轼的《琴诗》暗示了全局认知对于场景理解的重要性。而在图像理解领域,相较于基于精细标注数据的全监督学习,弱监督学习本质上是一种试图从全局出发来理解场景的方式,也更接近于人类对世界的认知机制。
程明明老师对截至18年初所做的工作做了一些梳理:
在low level vision层面,做了一些基于attention mechanism(注意力机制)的工作,以及边缘检测和区域分割工作来对图像进行预处理和category-independent的图像分析,注意力机制可以帮助我们准确快速地定位图像的区域,而不需要进行人工分割。
在light weighted semantic parsing方面,一方面将介绍语义分割,另一方面介绍它和interaction的结合。
最后,为大家介绍它们在图像及视觉领域的应用,比如进行editing(编辑)、Synthesis(合成)、web images(网络图片)方面的工作。
视觉注意力机制在图像认知中起到了非常重要的作用。对于机器而言,传统方法采用滑动窗口机制来检测图像中的每一个位置可能是什么样的物体,而人类观察图像并不是基于滑动窗口的机制对上百万个图像窗口进行搜索和检测,往往是借助很强的注意力来定位可能的物体区域,只是判断少量潜在物体区域的具体类别信息,这能够帮助我们进行快速有效地识别,并摆脱对大数据的依赖。
注意力机制有几个重要的分支:
其一为fixation prediction,旨在预测出图像中的注视点,这个注视点有可能是bottom-up与任务无关的,还有可能是top-down与当前任务相关的;
其二为salient object detection(显著性物体检测);
其三为objectness proposals,它是基于窗口的度量方法,通过预测图像中的每个窗口有多大可能性含有物体,有助于后期做物体检测。

首先介绍基于全局对比的显著性区域检测工作。我们通过对图像预分割,根据图像区域和其他所有区域的对比度(RC:region contrast)来计算显著性物体的区域。将在后面介绍如何用它来进行弱监督的学习。

刚才的工作无论是选择特征还是特征组合都是基于人手工的方法来做的。我们提出了基于学习的方式进行显著性物体检测,对每个区域提取特征,基于机器学习的方式自动选择特征的组合,这样能得到更好的分割结果。这个工作也取得了非深度学习方法中最好的结果。
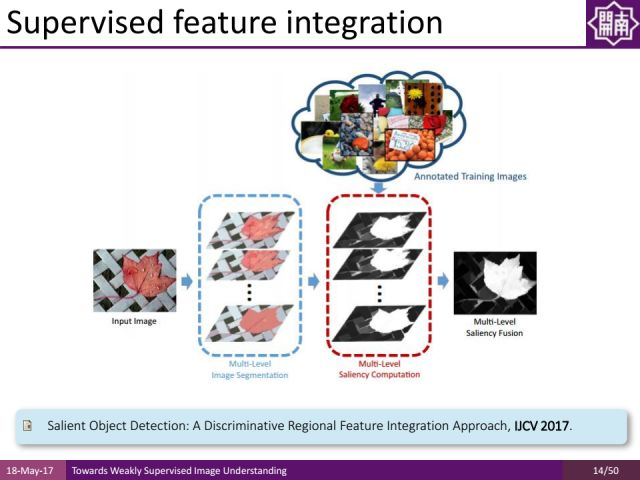
除了对特征的组合进行学习,去年CVPR上有一个工作通过深度方法对特征本身也进行学习,来得到显著性物体的区域。通过把不同层次的深度特征结合起来,通过一些short connections(短连接)的形式,能得到非常好的显著性物体检测结果。

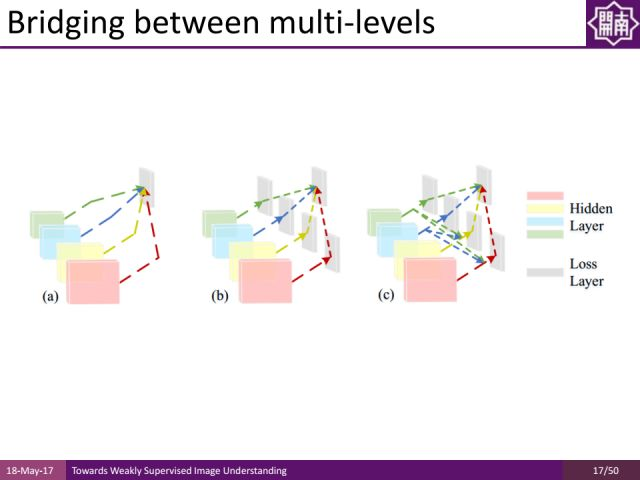
采用多层次的信息融合方式,如下图中间所示,它是一种深度神经网络架构。对于程老师团队提出的方法,越高层的卷积运算,可以得到更大尺度的信息。把不同尺度信息通过short-connection层连接起来,同时通过side output做指导,能够得到更好的显著性物体检测的结果。
近几年,显著性物体检测取得了很大的进步。在很多公开数据集上,显著性物体检测的结果已接近实用,比如在MSRA-B和ECSSD数据集上precision和recall都已达到了90%以上的结果,同时missing error都已下降到零点零几的水平。由此启发我们是否能将它用于弱监督学习中去,从显著性物体检测的结果来学习知识。
物体是由闭合轮廓围成的区域并有其重心,程老师在2014年的一个工作中据此设计了一种根据图像梯度估计图像中区域可能含有物体的可能性的方法。该方法和传统的方法效果基本接近,但是其速度要快出1000倍。


除了注意力机制,边缘检测也是对弱监督学习非常有帮助的。
下面是程老师团队发表在CVPR2017的边缘检测方面的工作。他们发现在不同的卷积层都有不同的有用信息,与其从池化层的前一层中拿出来做整合,不如提出所有卷积层的信息充分利用。

传统上,在几次卷积运算之后再做池化,中间层的特征只利用池化前的最后一层。新的工作把不同层的信息叠加起来,通过concat的方式来得到更加丰富的特征表达,通过这样的特征表达来训练边缘检测的结果。
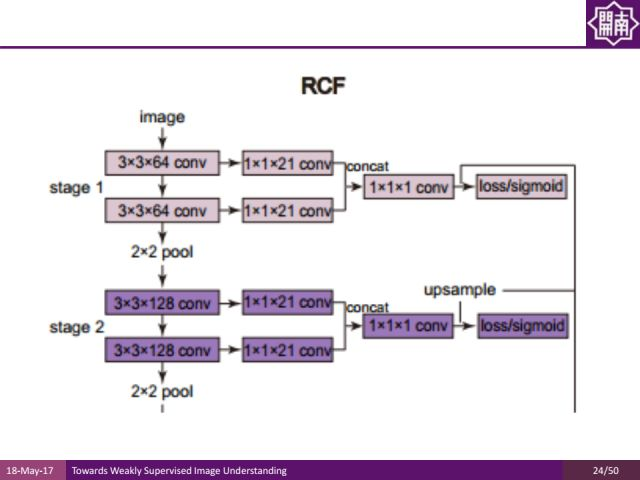
值得一提的是,这样的方法也达到了非常好的效果。比如在pascal voc数据集上,该方法是国际上首个能够实时运算,并且结果的F measure值已经超过当时在伯克利segmentation dataset上的人类平均的标注质量的方法。

此外,在low level vision里面,还有分割问题。通过对图像分组得到很多区域,期望每一个region里面只含有一个物体类别,作为比较强的约束信息可以帮助我们更好地理解图像内容。
这里边一个例子就是,我们(指程明明老师团队,下同)曾经用显著性物体检测的结果帮助我们initialize图像的区域,然后通过iteratively run GrabCut的方法分割出图像中的重要物体区域。这些分割信息加上keyword 信息本身可以帮助我们生成一些高质量的pixel-accurcy label(像素层面的图像标签),来更好地做语义分割。

除了做语义分割之外,我们直接用图像处理的方式(比如显著性物体检测、分割等)进行处理,我们对Internet image做object segmentation和显著性物体检测,借助一些关键字在分割里面做retrievel,得到这些retreival信息后,top ranking里面的retrieval results信息很多都是我们需要的物体类别,通过物体类别自动获取的example 包括它的分割信息去学习一些apperance model学习一些更加重要的知识,通过这些知识来更新我们对显著性物体的理解。
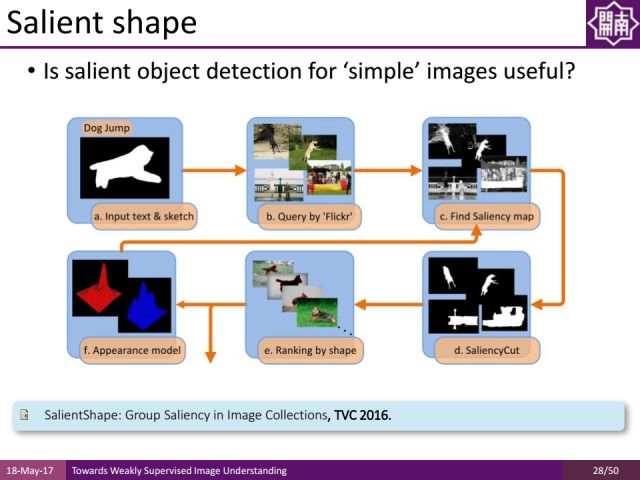
还有一个分割的工作是对图像做over segmentation,就是把图像分成很多块,我们希望每个块都不要跨越多个物体,因为同一个块通常只属于其中一个物体,哪怕区域里面有一些噪声,通过平均抑制噪声让分割信息更好,之前常用的over segmentation方法是efficient graph based image segmentation,其缺点是比较慢,因此我们在ECCV2016提出了一种基于GPU的方法对图像预处理而得到superpixel(超像素),然后对超像素提取特征并通过SVM(支持向量机)去学习一些特征组合,再对特征组合进行融合来得到非常好的结果。
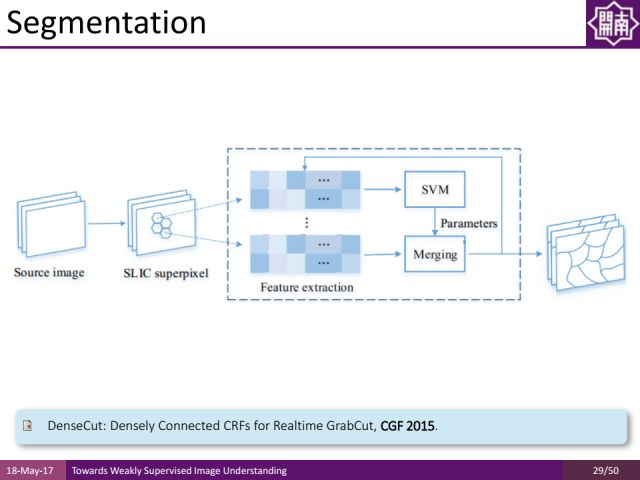
在伯克利的数据集上我们的方法取得了非常好的结果,速度上每秒能处理几十上百张图像,F measure值也不错,可以作为low-level领域的一个很好的工具去更好地约束弱监督学习的方式。
之前介绍的low level vision领域的注意力机制、边缘检测、图像分割相关工作结果都和图像的object category(物体类别)无关,因此这些信息就可以直接地运用到图像中去,帮助我们约束一个问题。比如图像里只含有一个物体,训练集里哪怕没有语义分割信息只有关键字信息,也会帮助我们去做语义分割。

这里介绍一个工作(STC:A Simple to Complex Framework for Weakly-supervised Semantic Segmentation)。文章开头提到过的,详见https://blog.csdn.net/XWUkefr2tnh4/article/details/78734093,通过显著性物体检测的结果,自动地生成语义分割的标签。通过low-level vision得到的约束能够帮助我们在弱监督的语义分割的学习中,减少对人工标注的依赖。
该方法本质上是对同一个结构的网络利用不同的监督信息训练了三次。
-
利用简单图片的显著图作为监督信息。由于简单图片往往只包含了一类物体,我们基于显著图可以获取每一个像素有多大的概率属于前景物体或者背景。我们利用显著图作为监督信息并采用multi-label cross-entropy loss训练出一个initial DCNN(I-DCNN),使得该网络具备一定语义分割能力。
-
我们利用I-DCNN对训练样本做预测,同时又根据image-level label剔除一些噪声,由此可得到针对简单图片的segmentation mask,进而基于预测出来的segmentation mask,按照全监督的卷积神经网络通用的损失函数去训练一个Enhanced DCNN(E-DCNN),进一步提升网络的语义分割能力。
-
引入更多的复杂图片,结合E-DCNN和其image-level label,预测segmentation mask,进而用它们作为监督信息重新训练一个更好的Powerful DCNN(P-DCNN)。
总结起来,这个网络的语义分割能力会通过这三步的训练方式一步步提升。STC框架如下图:

还有之前的上一工作,通过bottom-up的方式进行分割,发表在CVPR2017上,它使用一种top-down的方式。比如针对一个分类任务,可以通过attention network找到哪个区域属于哪类别,通过迭代使用top-down的注意力机制,更好地实现语义分割。
除了语义分割之外,通过light weighted semantic parsing,还可以支持一些interaction、图像编辑等等的工作。由于本人目前只集中注意力关注图像语义分割方法,有兴趣的小伙伴请仔细读完原链接后面部分的内容,再次附上链接https://blog.csdn.net/xwukefr2tnh4/article/details/78955546。