K-近邻与交叉验证
1 选取超参数的正确方法是:将原始训练集分为训练集和验证集,我们在验证集上尝试不同的超参数,最后保留表现最好的那个。
2 如果训练数据量不够,使用交叉验证法,它能帮助我们在选取最优超参数的时候减少噪音。
3 一旦找到最优的超参数,就让算法以该参数在测试集跑且只跑一次,并根据测试结果评价算法。
4 最近邻分类器能够在CIFAR-10上得到将近40%的准确率。该算法简单易实现,但需要存储所有训练数据,并且在测试时过于消耗计算能力。
5 最后,我们知道了仅仅使用L1和L2范数来进行像素比较是不够的,图像更多的是按照背景和颜色被分类,而不是语义主体本身。
1 预处理你的数据:对你数据中的特征进行归一化(normalize),让其具有零平均值(zero mean)和单位方差(unit variance)。
2 如果数据是高维数据,考虑使用降维方法。如PCA。
3 将数据随机分入训练集和验证集。按照一般规律,70%-90%数据作为训练集。
4 在验证集上调优,尝试足够多的K值,尝试L1和L2两种范数计算方式。
超参数(曼哈顿距离与欧氏距离):

损失函数:
任何一个算法都会有一个损失函数。
我们希望损失为零,为什么呢?损失越多说明我们错的越多,损失为零说明我们没做错啊。o(* ̄︶ ̄*)o

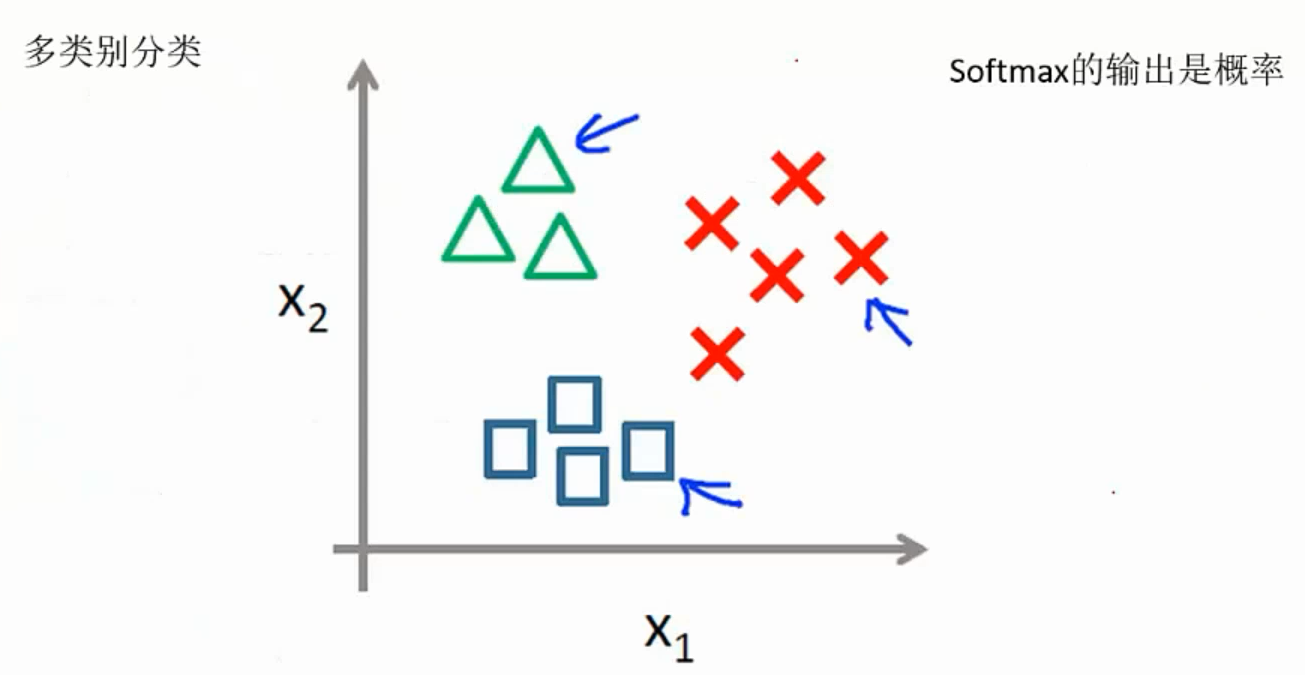
Softmax分类器:
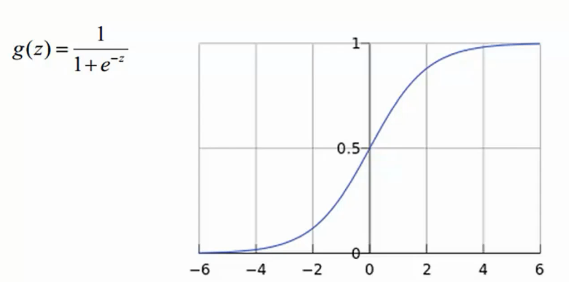
Sigmoid函数:

softmax实例:
