第四章 数值计算(numerical calculation)和第五章 机器学习基础下去自己看。
一、深度前馈网络(Deep Feedfarward Network,DFN)概要:
DFN:深度前馈网络,或前馈神经网络(FFN)/多层感知机(MLP)
目标:近似模拟某函数f y=f(x;θ)
学习参数θ的值,得到最佳的函数近似。
注:并非完美模拟大脑,只是实现统计泛化,函数近似机。源于大脑,但远远比不上大脑
结构: f(x)=f(3)(f(2)(f(1)(x)))
前馈(feedforward):信息一直往下流动,一路向前,不回头。例如:CNN
反馈(feedbackward):前馈的扩展,增加反馈连接,走一段,回头看看。例如:RCNN
线性模型:
优点:简单快速,线性回归和逻辑回归(广义线性回归)
局限性:受限于线性函数,无法表示任意变量间的相互作用
非线性模型(扩展):
套上一层皮:非线性变换
如何选择非线性变换?映射φ
(1)找通用函数:高维,过拟合。
只要函数维度足够高,总能拟合训练集,然而,测试集泛化不佳
非通用函数基于局部光滑原则
(2)人工设计函数:主流,极度依赖专家+领域,难以迁移
(3)自动学习函数:两全其美
同时学习函数参数+权重参数
唯一放弃凸性的方法,利大于弊
通用:只需要一个广泛的函数族,不用太精确
可控:专家知识辅助泛化,只需要找函数族φ(x;θ)
训练一个前馈网络需要做什么?
设计决策同线性模型
优化模型
代价函数
输出单元
网络结构该如何设计?
多少层,连接如何设置,每层多少个单元
如何高效地计算梯度?
反向传播
补充:线性变换
什么是线性变换?
仿射变换:线性变换+平移
具体:缩放、旋转、错切、翻转等
参考:《如何通俗讲解仿射变换》
什么是非线性变换?
参考第二章分享笔记或3Blue 1 Brown的《线性代数本质》
书面定义:加法+数乘——抽象
形象理解:
只需满足两点要求:原点不变,直线还是直线(不能扭曲)
二、如何解决异或问题
XOR函数(“异或”逻辑):两个二进制的运算
注:这道题绝不简单,曾引发AI的第一个寒冬
异或门是神经网络的命门!
解决:非线性变换+BP
人:
简单规则:if。。。else。。。
找规律:x+y=1,怎么自动学习
机器:
确定性、自动化、泛化能力
其他。
线性方法:f(x,w,b)=xTw+b
回归问题
均方误差
结果:任意点都输出0.5,失败。(w=0,以及b=0.5)
为什么会这样?
线性模型中各变量的参数固定
不能通过一个变量改变另外一个变量
结论:
线性模型无法解决异或问题。
那么,怎么办?——空间变换
低维线性不可分,高维线性可分(SVM)
非线性变换实现空间变换
两层神经网络可以无限逼近任意连续函数
网络结构:
两个输入,一个隐含层,一个输出
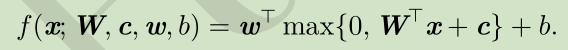
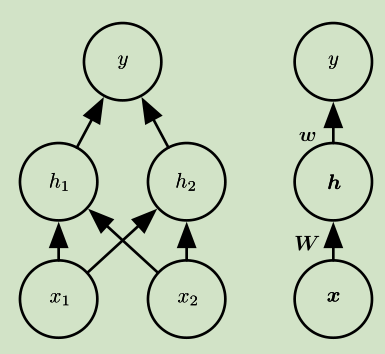
激活函数:
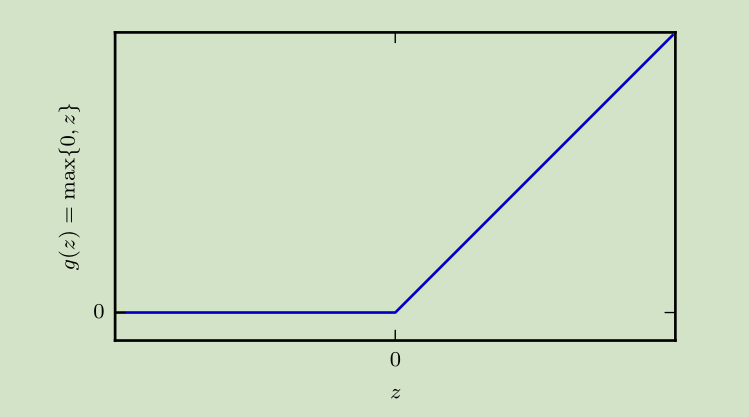
ReLU(整流线性单元)
一个解:
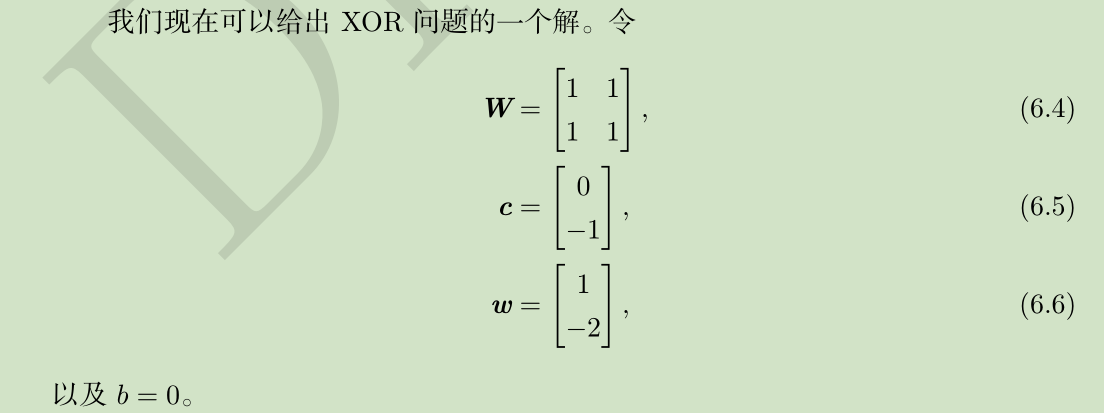
补充:
ReLUc长的是挺简单,可某个点有点膈应,可导吗?——不可导
那为什么还用它?——计算友好,特殊点特殊处理(给0或1),仿生
可导,可微,连续?
连续:有定义、光滑(极限存在)、无间断点。
可微和可导近似等效(多元情形不适用)
可积允许间断点
可导必连续,必可积。反之不可行。
见证奇迹的时刻(睁大眼睛看):
步骤:
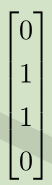
X--->XW--->XW+c--->ReLU--->*w
空间变换:正方形--->直线--->分段直线(线性可分)
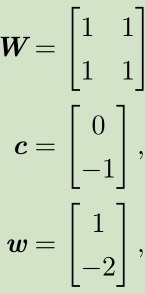 --->
--->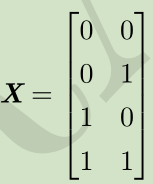 --->
--->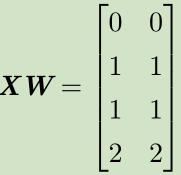 --->
--->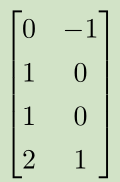 --->
--->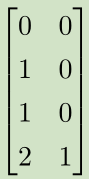 --->
--->
回想一下:
线性模型无法解决异或问题
低维线性不可分,高维线性可分
多个低级分类器组合成复杂分类器
《A friendly intruduction to Deep Learning and Neural Networks》
形象感知:
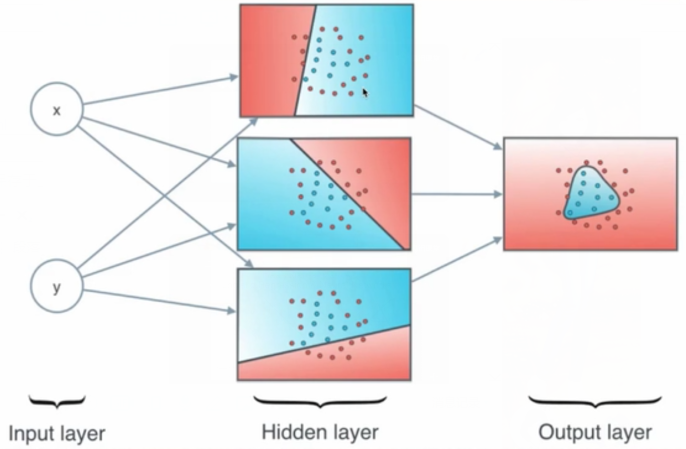
线性边界到非线性边界。
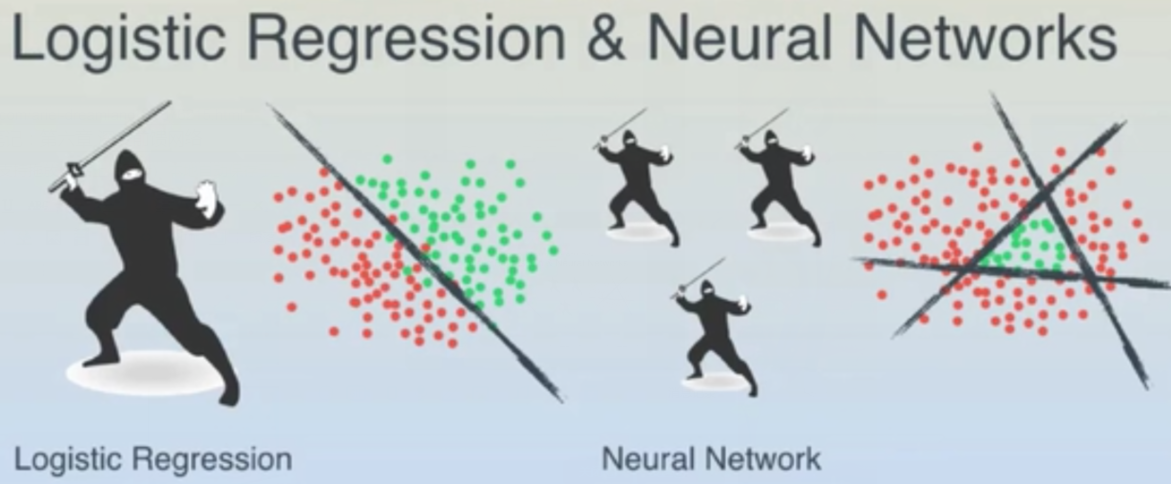
补充:直观感受异或分类
问题:人工求解--->自动训练?
理论证明:两层神经网络可以无限逼近任意连续函数
层数越深,表示能力越强
Google playground(可以下去自己搜索体验一下):
理想--->现实(近似最优解)
三、基于梯度的学习
虽然异或是AI命门,但还只是小儿科
实际情况,训练样本和参数都是数十亿级别
怎么办?——梯度下降
目前为止,神经网络和线性模型都用梯度下降
但最大的区别是:神经网络的非线性导致代价函数非凸,无法收敛到全局最优。
注:凸优化从任何一个初始值触发均能收敛到全局最优
如何计算梯度?
梯度下降升级版+BP算法
梯度下降:
当前位置最陡峭的方向可能最快(局部)
实际问题,高维空间如何收敛?(见第八章讲解)
设计要点:
优化算法:梯度下降
代价函数:交叉熵(负最大似然)

代价函数的梯度必须足够大,并有足够的预测能力,所以不要用sigmoid
贯穿神经网络设计的一个反复出现的主题是代价函数的梯度必须足够的大和具有足够的预测性,来为学习算法提供一个好的指引(见原书page111下)。
代价函数是一个泛函(函数到实数的映射)
如何对泛函求解?变分法


输出单元:线性单元,sigmoid单元,softmax单元等,等多细节请认真看书。
梯度下降对比(好好看书)。
四、反向传播
怎么更新网络权重?传统方法:固定其他变量,只计算一个
反向传播(back propagation):代价函数信息向后流动,以便计算梯度,甚至任意函数的导数
反向传播仅用于计算梯度,并非多层网络的学习方法!
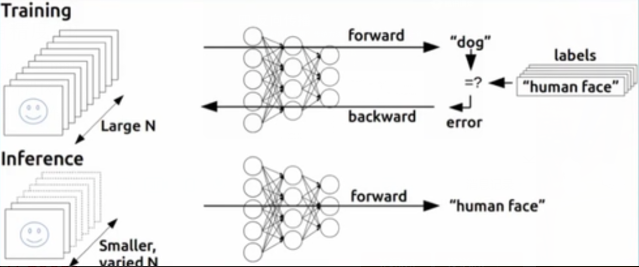
为什么要理解反向传播?TensorFlow工具不是现成的吗?

不要只会用工具,否则神经网络永远都是黑盒!不要在应用网络的时候,出了问题,都不知道怎么调试,学习任何技术,都要了解原理,不要只会使用工具,让自己也变成了单纯的工具。
计算图:
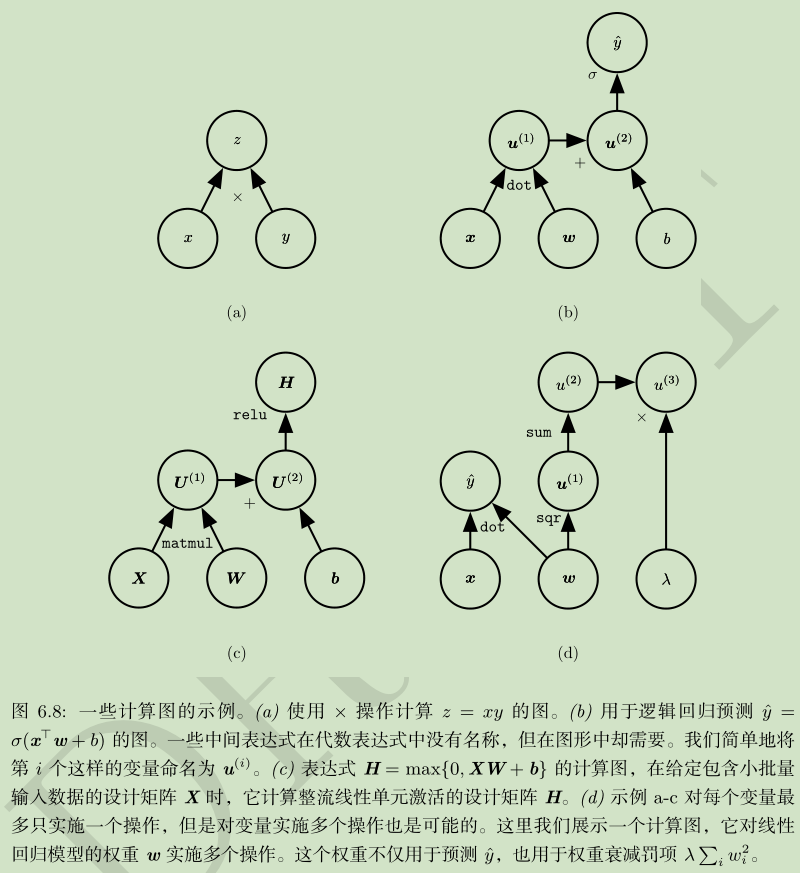
链式求导:
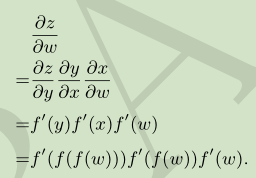
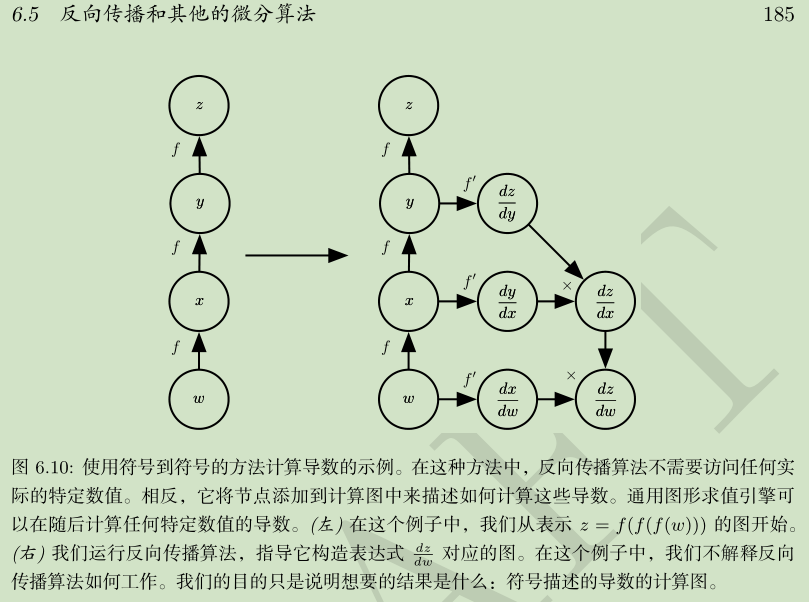
要点:
链式求导:导数=倍率
计算图
符号求导
损失函数
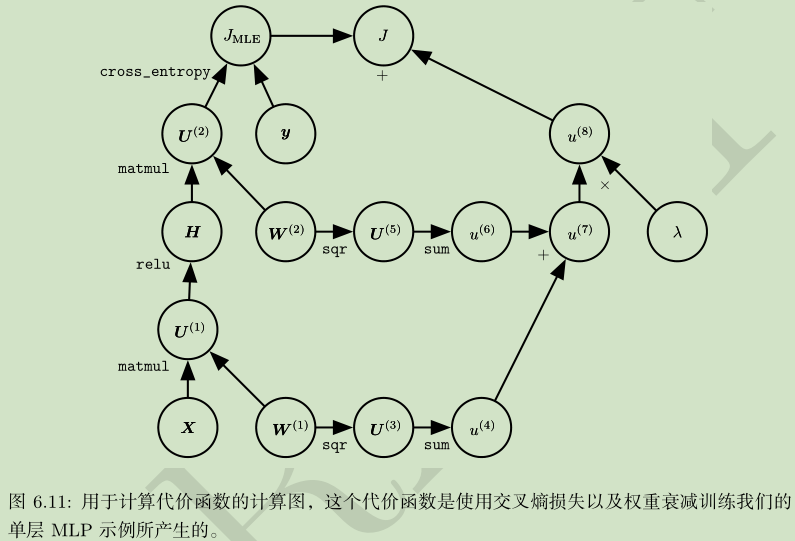
五、隐藏单元
如何选择隐藏单元的类型?
ReLU必定是极好的!
隐藏单元的选择建议
Relu及其扩展:绝对值整流,泄露整流,参数整流
Logistic sigmoid及双曲正切:易饱和,不宜做隐含层单元
径向基(RBF):radical basis function,大部分饱和到零,难以优化
softplus:ReLU的平滑版,实际效果不如ReLU好
硬双曲正切:hard tanh
其他
六、架构设计
有多少个单元,怎么连接?
神经网络大多是链式架构(俄罗斯套娃)
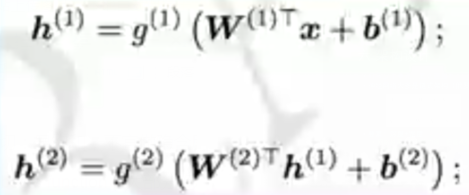

要素:深度+宽度
网络越深,泛化能力越强,但越难优化
深度和宽度折中
理想的架构需要不断实验
能自动学习网络深度吗?——可以,见书中“通用近似定理”?辩证去看
分段线性网络(ReLU或maxout)可表示区域数量跟深度成指数关系
网络越深,泛化越好。
七、总结
自1980年以来,前馈网络核心思想并无多大变化,仍然是梯度下降和反向传播
1986-2015,网络性能出现重大提升,原因是:
大量的数据降低网络泛化难度
硬件和软件能力的提升
部分算法上的进步:交叉熵替换均方差,ReLU的出现
80年代就有ReLU,但是被sigmoid替代,直到2009年才开始变天,原因:
网络非常小,sigmoid表现较好
迷信:必须避免不可导的激活函数
ReLU比隐含层权重还要重要,是系统性能提升的唯一因素
ReLU具备生物神经元的特性:阈值以下不活跃,阈值以上开始活跃,且活跃程度成正比
2006-2012,人们普遍不看好前馈网络,而今前馈网络表现非常好,进一步发展出变分自动编码器和生产对抗网络(GAN)
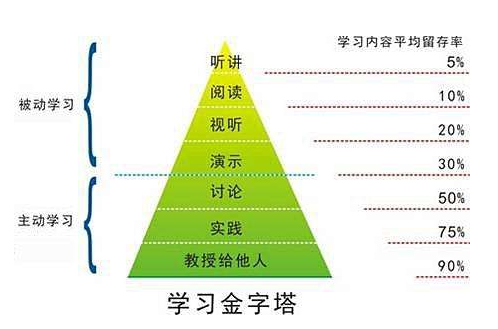
附:学习金字塔,给有心人