国外精读!title(17):Exploiting saliency for object segmentation from image level labels(利用图像级签的显著性进行目标分割)---CVPR2017
abstract:近年来语义标注任务有了显着的改进。然而,最先进的方法依赖于大规模的像素级注释。本文研究了从当前对象类的图像级注释训练像素级语义标签网络的问题。已经表明,可以从图像级标签获得指示显著性对象区域的高质量种子。没有额外的信息,获取对象的全部范围是由于共现导致的内在不适合的问题。我们建议使用显著性模型作为附加信息,并在此利用有关对象范围和图像统计的先验知识。我们展示了如何将两种信息源进行组合,以恢复完全监督的性能的80% - 这是在像素级语义标签的弱监督训练中的新技术。
introduction:作者认为必须探索额外的信息来补充图像级标注的监督 - 特别是对于克服该任务固有的模糊性。在这项工作中,作何提出利用不可知类的显著性信息作为新成分来完成特定类别像素标注的训练工作。
作者将像素级标注的目标分割问题分解为两个独立的任务模块:1 寻找目标位置;2 寻找目标的延展范围,这项任务可以等同于寻找一张图片的背景区域。
本文提出的pipeline中,无任何一点使用精确的逐像素注释。
注:文中将“对感兴趣目标类别的高置信度”称作“object seeds”;
seeds---区分感兴趣对象的区域。
related work:本文实验基于广受欢迎的deeplab网络架构。
本文通过图像级标注信息和显著性掩模去训练一个语义标注网络,最后在测试阶段生成一个针对对象类别的像素级标注信息。
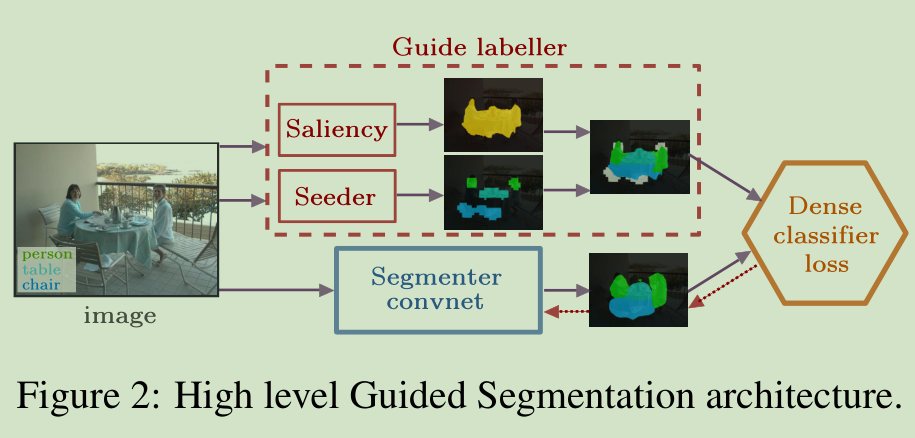
如图2 本文通过一个由两个模型组成的系统去做图像级标注信息的语义分割实验。称之为“Guided Segmentation ”architecture。
该结构解释如下:
给出一幅图和图像级标注信息, “guide labeller”模型会结合来自“seeder”线索和显著性子模型,进而生成一个粗糙的分割掩模,曰“guided”。然后,将上一步生成的引导掩模,即guided mask作为监督信息,可以训练出一个称为“segmenter convnet”的网络结构。在这整个结构中,segmentation convnet的训练是全监督的,并且使用逐像素softmax交叉熵损失函数。
总结:本文和STC那篇工作相比,不同之处在于:1 后者使用课程式学习,首先用简单的图像,训练分割网络,然后再用更复杂的图像。 本文不不要这样做,依然达到了更好的结果。2 后者使用手工制作的类不可知的显著性方法,而本文的显著性检测方法是基于深度学习的(因而提供了更好的线索)。 3 后者的训练过程使用从网络爬取的感兴趣的类别约40k张的额外图像; 本文不使用这种特定类别的外部数据。 4 本文报告了显着更好的结果,更好地证明了显著性作为指导弱监督语义对象标注附加信息的潜力。