UC Berkeley的Deepak Pathak 使用了一个具有图像级别标记的训练数据来做弱监督学习。训练数据中只给出图像中包含某种物体,但是没有其位置信息和所包含的像素信息。该文章的方法将image tags转化为对CNN输出的label分布的限制条件,因此称为 Constrained convolutional neural network (CCNN)。

该方法把训练过程看作是有线性限制条件的最优化过程:
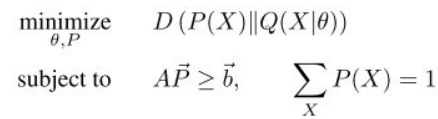
其中是一个隐含的类别分布,
是CNN预测的类别分布。目标函数是KL-divergence最小化。其中的线性限制条件来自于训练数据上的标记,例如一幅图像中前景类别像素个数期望值的上界或者下界(物体大小)、某个类别的像素个数在某图像中为0,或者至少为1等。该目标函数可以转化为为一个loss function,然后通过SGD进行训练。

实验中发现单纯使用Image tags作为限制条件得到的分割结果还比较差,在PASCAL VOC 2012 test数据集上得到的mIoU为35.6%,加上物体大小的限制条件后能达到45.1%, 如果再使用bounding box做限制,可以达到54%。FCN-8s可以达到62.2%,可见弱监督学习要取得好的结果还是比较难。