一、并发编程模型AKKA
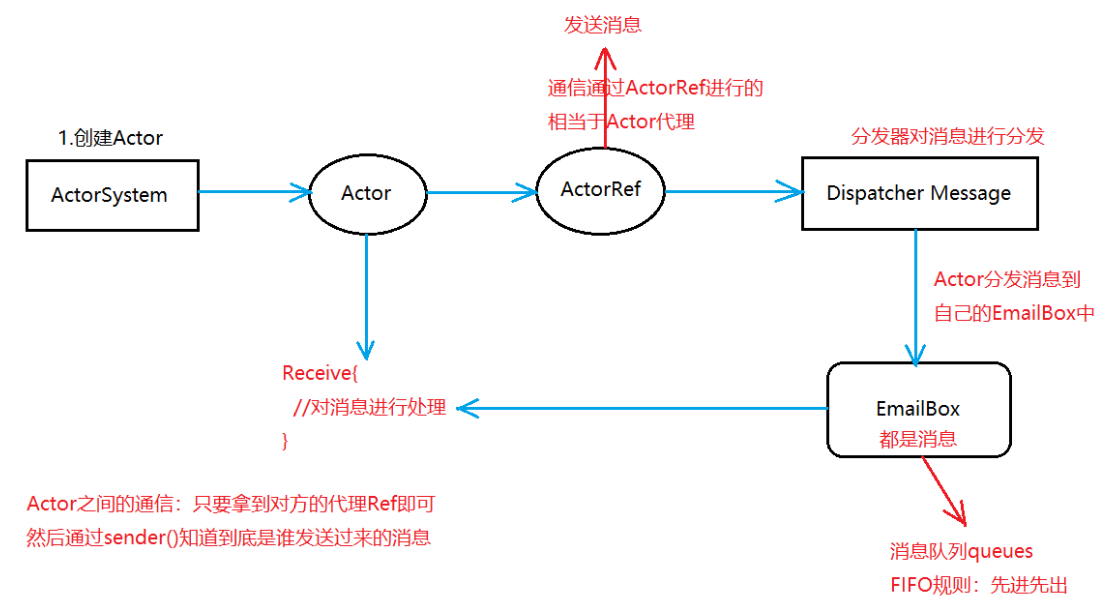
Spark使用底层通信框架AKKA 分布式 master worker hadoop使用的是rpc 1)akka简介 写并发程序很难,AKKA解决spark这个问题。 akka构建在JVM平台上,是一种高并发、分布式、并且容错的应用工具包 akka用scala语言编写同时提供了scala和java的开发接口 akka可以开发一些高并发程序。 2)Akka的Actor模型 akka处理并发的方法基于actor模型 在基于actor的系统中,所有事物都是actor。 actor作为一个并发模型设计和架构的,面向对象不是。 actor与actor之间只能通过消息通信。 Akka特点: (1)对并发模型进行了更高的抽象 (2)异步、非阻塞、高性能的事件驱动编程模型 (3)轻量级事件处理(1G内存可以容纳百万级别的Actor) 同步:阻塞(发消息 一直等待消息) 异步:不阻塞(发消息 不等待 该干嘛干嘛) actor简化了并发编程,提高了程序性能。
1、Actor模型

2、Actor工作机制
二、AKKA编程
1、需求 我发消息,自己收
object CallMe { //1.创建ActorSystem 用ActorSystem创建Actor private val acFactory = ActorSystem("AcFactory") //2.Actor发送消息通过ActorRef private val callRef = acFactory.actorOf(Props[CallMe],"CallMe") def main(args: Array[String]): Unit = { //3.发送消息 callRef ! "你吃饭了吗" callRef ! "很高兴见到你" callRef ! "stop" } } class CallMe extends Actor{ //Receive用户接收消息并且处理消息 override def receive: Receive = { case "你吃饭了吗" => println("吃的鸡腿") case "很高兴见到你" => println("我也是") case "stop" => { //关闭代理ActorRef context.stop(self) //关闭ActorSystem context.system.terminate() } } }
结果:

2.需求 一个Actor发送消息,另外一个Actor接收消息
(1)TomActor
import akka.actor.Actor class TomActor extends Actor{ override def receive: Receive = { case "你好,我是John" => { println("你好,我是Tom") } case "我爱Tom" => { println("Tom也爱John") } } }
(2)JohnActor
import akka.actor.{Actor, ActorRef} class JohnActor(val h:ActorRef) extends Actor{ override def receive: Receive = { case "你好,我是John" => { //John发送消息给TomActor h ! "我爱Tom" } } }
(3)QqDriver
import akka.actor.{ActorSystem, Props} object QqDriver { //1.创建ActorSystem 用ActorSystem创建Actor private val qqFactory = ActorSystem("QqFactory") //2.Actor发送消息通过ActorRef private val hRef = qqFactory.actorOf(Props[TomActor],"Tom") //John需要接受Tom发送的消息 private val dRef = qqFactory.actorOf(Props(new JohnActor(hRef)),"John") def main(args: Array[String]): Unit = { //1.Tom自己给自己发送消息 //hRef ! "我爱Tom" //2John给Tom发送消息 dRef ! "你好,我是John" } }
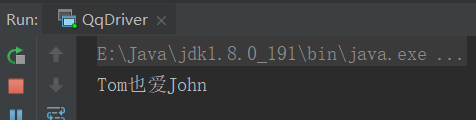
(4)结果
3、maven依赖pom文件
<!-- 定义版本常量 -->
<properties>
<encoding>UTF-8</encoding>
<scala.version>2.11.8</scala.version>
<scala.compat.version>2.11</scala.compat.version>
<akka.version>2.4.17</akka.version>
</properties>
<dependencies>
<!-- 添加scala包的依赖 -->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<!-- 添加akka包的actor依赖 -->
<dependency>
<groupId>com.typesafe.akka</groupId>
<artifactId>akka-actor_${scala.compat.version}</artifactId>
<version>${akka.version}</version>
</dependency>
<!-- 多进程之间的Actor通信设置 -->
<dependency>
<groupId>com.typesafe.akka</groupId>
<artifactId>akka-remote_${scala.compat.version}</artifactId>
<version>${akka.version}</version>
</dependency>
</dependencies>
<!-- 指定使用插件-->
<build>
<!-- 指定源码包和测试包的位置信息 -->
<sourceDirectory>src/main/scala</sourceDirectory>
<testSourceDirectory>src/test/scala</testSourceDirectory>
<plugins>
<!-- 指定编译scala的插件 -->
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.2</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
<configuration>
<args>
<arg>-dependencyfile</arg>
<arg>${project.build.directory}/.scala_dependencies</arg>
</args>
</configuration>
</execution>
</executions>
</plugin>
<!-- maven打包使用的插件 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.4.3</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<transformers>
<transformer implementation="org.apache.maven.plugins.shade.resource.AppendingTransformer">
<resource>reference.conf</resource>
</transformer>
<!-- 指定main方法 -->
<transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>com.itstaredu.spark.SparkWorker</mainClass>
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>