一、Kafka概述
离线部分:
Hadoop->离线计算(hdfs / mapreduce) yarn
zookeeper->分布式协调(动物管理员)
hive->数据仓库(离线计算 / sql)easy coding
flume->数据采集
sqoop->数据迁移mysql->hdfs/hive hdfs/hive->mysql
Azkaban->任务调度工具
hbase->数据库(nosql)列式存储 读写速度
实时:
kafka
storm
官网:
http://kafka.apache.org/
ApacheKafka®是一个分布式流媒体平台
流媒体平台有三个关键功能:
发布和订阅记录流,类似于消息队列或企业消息传递系统。
以容错的持久方式存储记录流。
记录发生时处理流。
Kafka通常用于两大类应用:
构建可在系统或应用程序之间可靠获取数据的实时流数据管道
构建转换或响应数据流的实时流应用程序
二、kafka是什么?
在流计算中,kafka主要功能是用来缓存数据,storm可以通过消费kafka中的数据进行流计算。
是一套开源的消息系统,由scala写成。支持javaAPI的。
kafka最初由LinkedIn公司开发,2011年开源。
2012年从Apache毕业。
是一个分布式消息队列,kafka读消息保存采用Topic进行归类。
角色
发送消息:Producer(生产者)
接收消息:Consumer(消费者)
三、为什么要用消息队列
1)解耦
为了避免出现问题
2)拓展性
可增加处理过程
3)灵活
面对访问量剧增,不会因为超负荷请求而完全瘫痪。
4)可恢复
一部分组件失效,不会影响整个系统。可以进行恢复。
5)缓冲
控制数据流经过系统的速度。
6)顺序保证
对消息进行有序处理。
7)异步通信
akka,消息队列提供了异步处理的机制。允许用户把消息放到队列 , 不立刻处理。
四、kafka架构设计
kafka依赖zookeeper,用zk保存元数据信息。
搭建kafka集群要先搭建zookeeper集群。
zk在kafka中的作用?
保存kafka集群节点状态信息和消费者当前消费信息。
Kafka介绍
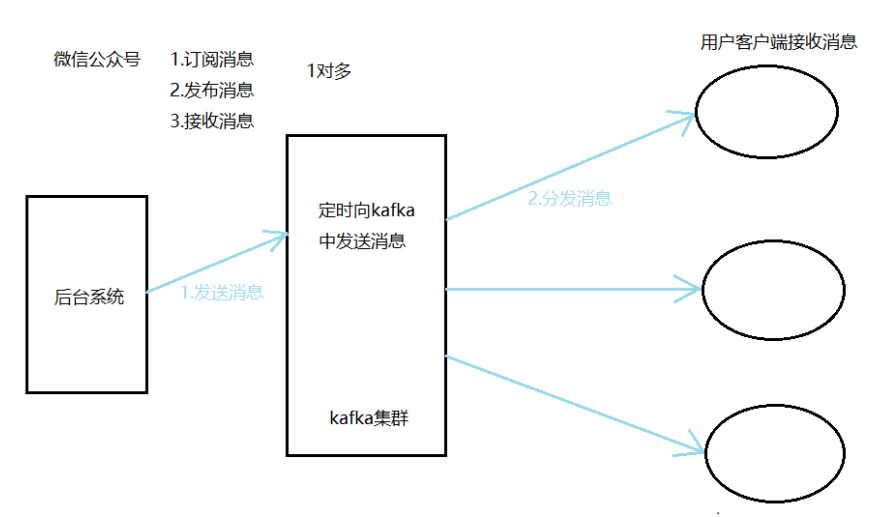
Kafka架构

五、kafka集群安装部署
1)官网下载安装包
2)上传安装包
把安装包 kafka_2.11-2.0.0.tgz 放置在/root下
3)解压安装包
cd /root
tar -zxvf kafka_2.11-2.0.0.tgz -C hd
4)重命名
cd hd
mv kafka_2.11-2.0.0/ kafka
5)修改配置文件
cd /root/hd/kafka
mkdir logs
cd config
vi server.properties
broker.id=0 #每台机器的id不同即可
delete.topic.enable=true #是否允许删除主题
log.dirs=/root/hd/kafka/logs #运行日志保存位置
zookeeper.connect=hd09-1:2181,hd09-2:2181,hd09-3:2181
6)配置环境变量
vi /etc/profile
最下面添加
#kafka_home
export KAFKA_HOME=/root/hd/kafka
export PATH=$PATH:$KAFKA_HOME/bin
生效环境变量
source /etc/profile
7)分发到其他节点
cd /root/hd
scp -r kafka/ hd09-2:$PWD
scp -r kafka/ hd09-3:$PWD
8)修改其他节点/root/hd/kafka/config/server.properties
broker.id=1 #hd09-2
broker.id=2 #hd09-3
9)启动集群
cd /root/hd/kafka
bin/kafka-server-start.sh config/server.properties &
10)关闭
cd /root/hd/kafka
bin/kafka-server-stop.sh
六、Kafka命令行操作
1)查看当前集群中已存在的主题topic
bin/kafka-topics.sh --zookeeper hd09-1:2181 --list
2)创建topic
bin/kafka-topics.sh --zookeeper hd09-1:2181 --create --replication-factor 3 --partitions 1 --topic study
--zookeeper 连接zk集群
--create 创建
--replication-factor 副本
--partitions 分区
--topic 主题名
3)删除主题
bin/kafka-topics.sh --zookeeper hd09-1:2181 --delete --topic study
4)发送消息
生产者启动:
bin/kafka-console-producer.sh --broker-list hd09-1:9092 --topic study
消费者启动:
bin/kafka-console-consumer.sh --bootstrap-server hd09-1:9092 --topic study --from-beginning
5)查看主题详细信息
bin/kafka-topics.sh --zookeeper hd09-1:2181 --describe --topic study
七、Kafka简单API
1、Producer1类---kafka生产者API 接口回调
package com.css.kafka.kafka_producer;
import java.util.Properties;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
/**
* kafka生产者API
*/
public class Producer1 {
public static void main(String[] args) {
//1.配置生产者属性(指定多个参数)
Properties prop = new Properties();
//参数配置
//kafka节点的地址
prop.put("bootstrap.servers", "192.168.146.132:9092");
//发送消息是否等待应答
prop.put("acks", "all");
//配置发送消息失败重试
prop.put("retries", "0");
//配置批量处理消息大小
prop.put("batch.size", "10241");
//配置批量处理数据延迟
prop.put("linger.ms", "5");
//配置内存缓冲大小
prop.put("buffer.memory", "12341235");
//配置在发送前必须序列化
prop.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
prop.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
//2.实例化producer
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(prop);
//3.发送消息
for (int i = 0; i < 99; i++) {
producer.send(new ProducerRecord<String, String>("test", "helloworld" + i));
}
//4.释放资源
producer.close();
}
}
2、Producer2类---kafka生产者API 接口回调
package com.css.kafka.kafka_producer;
import java.util.Properties;
import org.apache.kafka.clients.producer.Callback;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
/**
* kafka生产者API 接口回调
*/
public class Producer2 {
public static void main(String[] args) {
//1.配置生产者属性(指定多个参数)
Properties prop = new Properties();
//参数配置
//kafka节点的地址
prop.put("bootstrap.servers", "192.168.146.132:9092");
//发送消息是否等待应答
prop.put("acks", "all");
//配置发送消息失败重试
prop.put("retries", "0");
//配置批量处理消息大小
prop.put("batch.size", "10241");
//配置批量处理数据延迟
prop.put("linger.ms", "5");
//配置内存缓冲大小
prop.put("buffer.memory", "12341235");
//配置在发送前必须序列化
prop.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
prop.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
//自定义分区
prop.put("partitioner.class", "com.css.kafka.kafka_producer.Partition1");
//2.实例化producer
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(prop);
//3.发送消息
for (int i = 0; i < 99; i++) {
producer.send(new ProducerRecord<String, String>("yuandan", "nice" + i), new Callback() {
public void onCompletion(RecordMetadata metadata, Exception exception) {
//如果metadata不为null 拿到当前的数据偏移量与分区
if(metadata != null) {
System.out.println(metadata.topic() + "----" + metadata.offset() + "----" + metadata.partition());
}
}
});
}
//4.关闭资源
producer.close();
}
}
3、Partition1类---设置自定义分区
package com.css.kafka.kafka_producer;
import java.util.Map;
import org.apache.kafka.clients.producer.Partitioner;
import org.apache.kafka.common.Cluster;
/**
* 设置自定义分区
*/
public class Partition1 implements Partitioner{
//设置
public void configure(Map<String, ?> configs) {
}
//分区逻辑
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
return 1;
}
//释放资源
public void close() {
}
}
4、Consumer1类---消费者API
package com.css.kafka.kafka_consumer;
import java.util.Arrays;
import java.util.Properties;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
/**
* 消费者类
*/
public class Consumer1 {
public static void main(String[] args) {
//1.配置消费者属性
Properties prop = new Properties();
//2.配置属性
//指定服务器地址
prop.put("bootstrap.servers", "192.168.146.133:9092");
//配置消费者组
prop.put("group.id", "g1");
//配置是否自动确认offset
prop.put("enable.auto.commit", "true");
//序列化
prop.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
prop.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
//2.实例消费者
final KafkaConsumer<String,String> consumer = new KafkaConsumer<String, String>(prop);
//4.释放资源 线程安全
Runtime.getRuntime().addShutdownHook(new Thread(new Runnable() {
public void run() {
if (consumer != null) {
consumer.close();
}
}
}));
//订阅消息主题
consumer.subscribe(Arrays.asList("test"));
//3.拉消息 推push 拉poll
while (true) {
ConsumerRecords<String, String> records = consumer.poll(1000);
//遍历消息
for (ConsumerRecord<String, String> record : records) {
System.out.println(record.topic() + "-----" + record.value());
}
}
}
}
5、Producer3类---kafka生产者API-带拦截器
package com.css.kafka.interceptor;
import java.util.ArrayList;
import java.util.Properties;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
/**
* kafka生产者API 带拦截器
*/
public class Producer3 {
public static void main(String[] args) {
//1.配置生产者属性(指定多个参数)
Properties prop = new Properties();
//参数配置
//kafka节点的地址
prop.put("bootstrap.servers", "192.168.146.132:9092");
//发送消息是否等待应答
prop.put("acks", "all");
//配置发送消息失败重试
prop.put("retries", "0");
//配置批量处理消息大小
prop.put("batch.size", "10241");
//配置批量处理数据延迟
prop.put("linger.ms", "5");
//配置内存缓冲大小
prop.put("buffer.memory", "12341235");
//配置在发送前必须序列化
prop.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
prop.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
//拦截器
ArrayList<String> inList = new ArrayList<String>();
inList.add("com.css.kafka.interceptor.TimeInterceptor");
prop.put(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG, inList);
//2.实例化producer
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(prop);
//3.发送消息
for (int i = 0; i < 99; i++) {
producer.send(new ProducerRecord<String, String>("test", "helloworld" + i));
}
//4.释放资源
producer.close();
}
}
6、TimeInterceptor类---拦截器类
package com.css.kafka.interceptor;
import java.util.Map;
import org.apache.kafka.clients.producer.ProducerInterceptor;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
/**
* 拦截器类
*/
public class TimeInterceptor implements ProducerInterceptor<String, String>{
//配置信息
public void configure(Map<String, ?> configs) {
}
//业务逻辑
public ProducerRecord<String, String> onSend(ProducerRecord<String, String> record) {
return new ProducerRecord<String, String>(
record.topic(),
record.partition(),
record.key(),
System.currentTimeMillis() + "-" + record.value());
}
//发送失败调用
public void onAcknowledgement(RecordMetadata metadata, Exception exception) {
}
//关闭资源
public void close() {
}
}
7、kafka的maven依赖
<!-- https://mvnrepository.com/artifact/org.apache.kafka/kafka-clients -->
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.0.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.kafka/kafka-streams -->
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-streams</artifactId>
<version>2.0.0</version>
</dependency>