初步了解Linux系统
和学习Windows一样(虽然Windows也学的不好),Linux的学习过程也是一个循序渐进的过程,不可能一上来连shell是什么都不知道就开始学习shell编程(当然经过之后的学习我现在已经大致了解什么叫做shell了)。
那么什么是Linux呢?Linux其实和Windows一样,就是一个操作系统,在下图可以看到:
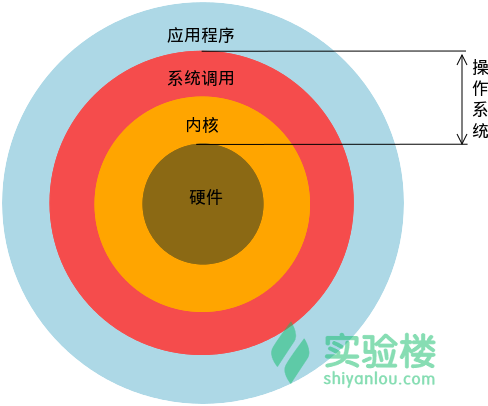
Linux做为一个操作系统在整个计算机系统中的角色,主要为系统调用和内核两层。而在Linux整个操作系统上包含了很多的应用程序,Linux则对每个应用程序提供系统调用接口,这样我们的Linux内核就可以让这些应用程序在操作系统上运行。接下来我们要学习开始学习的部分均是应用程序这部分,毕竟要先了解这些外层的应用程序的用法才能更好的了解和掌握内层的事物嘛。
Linux作为世界上最大最好的开源计算机系统,其发展历史非常的坎坷却精彩,这里就不过多的介绍了,感兴趣可以参看wiki/linux#history。
安装Linux及熟悉基本使用
鉴于学校的网速堪忧,实验楼中的Linux环境实在是很难用(不过可能网好也好用不到哪去,毕竟是在网页模拟的桌面环境)。正好老师也让我们自己安装一个Linux的虚拟机,至于是哪个发行版不限。这里我考虑使用比较新的mint系统,同时为了让自己能够强制性使用Linux系统,我安装了双系统,这样的话,除非是文字编辑工作,其他的一切工作和学习均在Linux环境下完成。
安装mint
mint系统是基于Ubuntu进行优化的系统,对于新手来说非常友好。首先打开mint的官网,由于mint-cinnamon版本对高分屏支持不够,我们选择mint-xfce或mint-mate发行版。下载ISO镜像并制作启动盘。具体的安装步骤就不在此处详细说明了,可以参照网上众大神们的帖子进行安装,当然,记住首先要分出一个空磁盘区,不然Windows很容易被搞崩溃。
对mint进行简单设置
按照“实验楼”的教程,apt命令的讲解被安排在较靠后的章节。但是对于我们急需正常使用的新手来说,这个命令在初期使用过程中可谓是频率最高的命令没有之一。
root权限
对于第一次使用linux的新手来说,权限(对于文件的权限细节会在本博客稍后的地方说明)可能是最大的问题,为什么会有这个问题呢?这是因为对于一台刚装好的linux,它内部的一切设置都需要用户自己去调整,而不像Windows那么便捷。对于拥有最大的权限root用户来说,是拥有可以创建和摧毁一切的权利的。大家可以开始疑问了,那我们直接使用root用户不就好了。作为root用户,是集大权于一身,新手用户往往会在不知情的情况下删除了某个重要文件,严重的甚至导致系统崩溃,这便是不推荐使用root用户的原因了。所以为了赋予普通用户root权限,聪明的linux大神设计出了sudo命令。因此,在安装完系统之后,我们要做的第一件事就是为普通用户赋予root权限。首先我们要了解这个命令的配置文件,是处于/etc目录下的sudoers文件,这个文件至关重要,使用cat命令输出之后发现文件中有这么一行说明# This file MUST be edited with the 'visudo' command as root.,也就是说这个文件本身是禁止任何用户(包括root用户)进行写操作的,只可使用visudo命令来进行编辑。在查阅man visudo之后得知,使用visudo命令时,系统会自动创建一个temp文件用于临时存储,当用户保存文档时,系统会自动检查文档的语法问题,若无语法错误则保存至sudoers文件,否则不予保存。了解了sudoers文件之后我们对其进行更改,方法很简单:
- 在文件中的
# Allow members of group sudo to execute any command中的提示行下面加上username ALL=(ALL:ALL) NOPASSWD: ALL即可,应当注意的是区分大小写&不要漏掉空格。
这样一来普通用户的root权限就赋予成功了,之后的使用过程除非遇到紧急情况,不然都应使用普通用户。
认识apt & dpkg
很多人都说Linux安装软件很方便,只要你会使用命令就好了。确实如此,Linux的每个发行版都拥有大量的镜像源,而这些镜像源大多放置在世界各处的镜像站上,即软件镜像服务器。比较出名的如享有“中国官方镜像站”的中国科技大学镜像站,清华镜像站。回归正题:
APT全称是Advance Packaging Tool(高级包装工具),是Debian及其派生发行版的软件包管理器,APT可以自动下载,配置,安装二进制或者源代码格式的软件包,因此简化了Unix系统上管理软件的过程。APT最早被设计成dpkg的前端,用来处理deb格式的软件包。现在经过APT-RPM组织修改,APT已经可以安装在支持RPM的系统管理RPM包。这个包管理器包含以 apt- 开头的多个工具,如 apt-get apt-cache apt-cdrom 等,在Debian系列的发行版中使用。
DPKG全称是”Debian Package“这个机制最早是由Debian Linux社群所开发出来的,透过dpkg的机制,Debian,提供的软件就能够简单的安装起来,同时还能提供安装后的软件信息。只要是衍生于 Debian 的其他 Linuxdistributions,大多使用dpkg这个机制来管理软件的,包括B2D,Ubuntu等等。
在mint下这两者对于安装软件都有着非常重要的作用。
常见的apt命令有:
- install 其后安装软件包名,用于安装一个软件包
- update 从软件源镜像服务器上下载/更新用于更新本地软件源的软件包列表
- upgrade 升级本地可更新的全部软件包,但存在依赖问题时将不会升级,通常会在更新之前执行一次update
- remove 移除已安装的软件包,包括与被移除软件包有依赖关系的软件包,但不包含软件包的配置文件
其中apt的常见参数:
- -s 模拟安装
- -f 修复损坏的依赖关系,常适用于dpkg命令之后
- --reinstall 重新安装已经安装但可能存在问题的包
dpkg的常见参数有:
- -i 安装指定deb包
- -R 后面目录名用于安装该目录下所有的deb包
- -s 现实已装包的信息
- -S 搜索已安装包
- -L 现实已安装软件包的目录信息
更换mint镜像源
认识了重要的apt和dpkg命令之后我们要活学活用,有些小伙伴在安装完系统之后就立马进行软件安装了,虽然是个联网应用,但是这个下载速度实在是太慢了(当然我们学校的网速也快不到哪去)。细心的你会发现,在进行软件安装的时候
会发现控制台中会不断的输出信息,其中有着这么一条
Get: 1 http://cn.archive.ubuntu.com bionic/main amd64 * amd64 2:8.0.1453-1ubuntu1
这表明apt其实是从cn.archive.ubuntu.com这个网址获取软件的,路由追踪之后发现这个网站的ip是美国ip,所以我们从这里下载软件速度当然就很慢了。接下来我们要做的就是更换软件镜像源。这里附上清华Ubuntu镜像源说明的链接,按照上面的教程更换即可。之后我们对mint进行一些常用的软件进行安装使得系统能够正常运行即可。
学习中遇到的重点&难点&问题及思考过程
”实验楼“提供的学习资料和平台对于我这样的新手来说还是非常适合的,覆盖面非常广,可以说基本的Linux知识都覆盖了。这里我不再复述”实验楼“中所提的全部知识点,只提出重点&难点&问题及思考过程。
重点
这里的重点是指学习过程中非常基本但很重要的知识点。
文件与目录
Linux是一个多用户多操作的操作系统,在Linux中不仅可以创建多个用户,还可以创建多个用户组。Linux下每个文件都有对应着三个群体,一是文件拥有者,二是拥有者所在的用户组,三是其他用户。而对于每一种群体这样便得出了Linux下文件权限的标识:user,group和others。而对于每一个文件,每一类用户均有读、写和执行这三种操作权限,因此,Linux下文件的权限表示方法就变为如下方式:
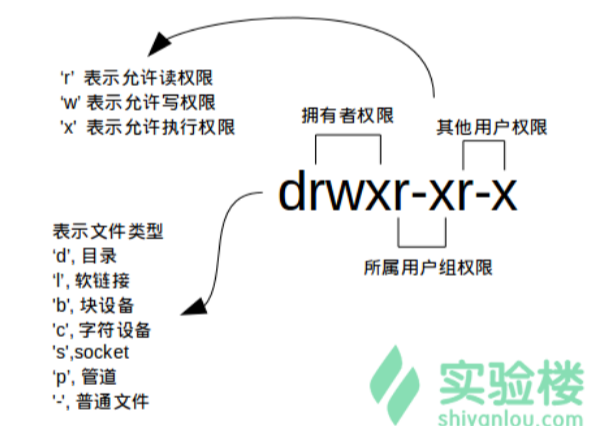
可以看到,第一个字母表示该文件的类型,之后的三组数表示文件对应各个群体所拥有的权限。如果某个群体没有该项权限,那么这一栏用”-“表示,如drw-r--r--。当我们要改变其各个群体的权限时,通常采用chmod命令的两种方式:
第一种为数字式,即把rwx的位置看成是二进制的位数,这样如果想把某个群体的权限改成可读可写即为(110)2,对应的十进制即是6。如chmod 600 file,即是把file文件改成只有拥有者可查看。
第二种为加减赋值操作,对应与上述chmod 600 file命令,应等价为chmod u+rw file;chmod go-rw file。不过对比之下就能发现数字式的方便太多了。
和Windows完全不同的地方在于,Linux所有的事物,如文件夹,设备等等其实本质都是文件。在Linux下,一切皆文件,对于习惯使用Windows的我们,当打开Windows的文件资源管理器时可以看到普通文件是标注的文件大小的,而目录也没有大小的说法,但是在Linux下使用ll命令查看当前目录下的所有文件时,你会发现竟然连目录都有大小。同时,Linux是以树形目录结构的形式来构建整个系统的,可以理解为树形目录是一个用户可操作系统的骨架。虽然本质上无论是目录结构还是操作系统内核都是存储在磁盘上的,但从逻辑上来说 Linux 的磁盘是“挂在”(挂载在)目录上的,每一个目录不仅能使用本地磁盘分区的文件系统,也可以使用网络上的文件系统。举例来说,可以利用网络文件系统(Network File System,NFS)服务器载入某特定目录等。了解了Linux的目录大致体系,接下来我们要做的就是深入学习各个目录的作用了。为了能够更好的规划Linux的各个目录,神奇的Linux社区定义了FHS,全称Filesystem Hierarchy Standard,文件系统层次结构标准。为了方便以后查阅,这里附上一张”实验楼“的FHS树形目录图。
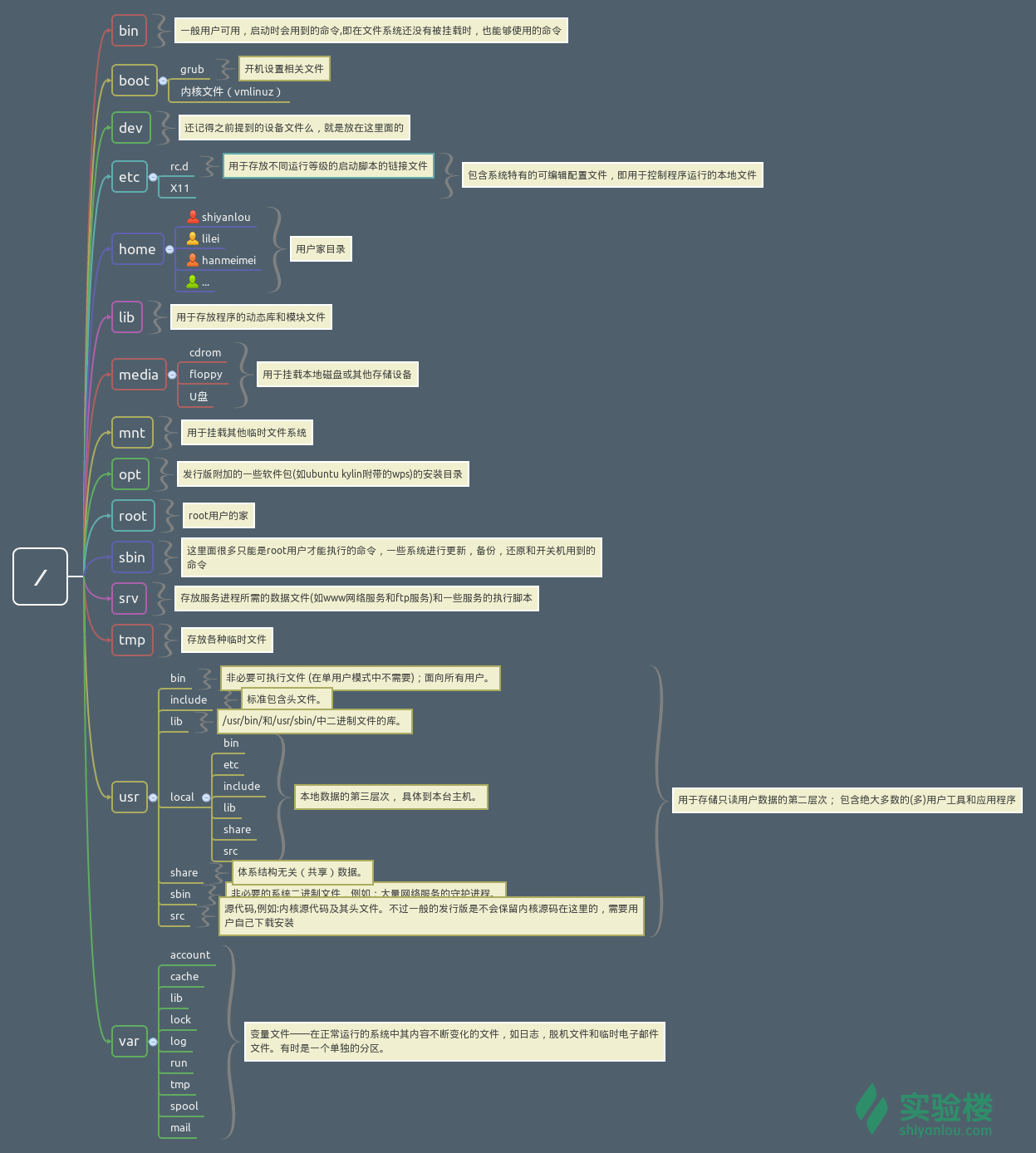
可以看到,对于初学者来说,这个目录还真是一点都不友好呀,五花八门,看的真的容易头晕。作为初学者,我们虽然不用对自己要求过高,但是最基本的我们还是要清楚的。这里说说三个最基本的目录。
- "" 根目录”“是这个树形目录图的树根,所有的子目录都是挂载在根目录上的,在FHS的定义中,第一层定义即是定义根目录下的各个目录应该要放什么数据。
- ”usr“ 依据FHS定义,此目录下防止的数据属于可分享和不可变动的。其中usr是UNIX Software Resource的缩写,也就是UNIX操作系统软件资源的存放目录。
- ”var“ var目录主要针对常态性变动的文件,包括缓存、登录文件以及日志等。
Shell
什么是shell?对于初学者来说,这又是个既有趣又复杂的问题。笼统的来讲,我们需要通过shell,将我们输入的命令与内核通信,好让内核可以控制硬件来正确无误的工作,这就是shell。简单来说,其实shell的功能只是提供用户操作系统的一个接口,因此这个shell需要可以调用其他软件才能更好的帮助我们完成工作。所以这么一想,在使用Linux时我们所有的工作基本都是在bash或是zsh这些shell下来键入命令从而完成的。回想下,如果是windows下我们会如何去完成一项工作呢?首先,我们应该确定用何种软件或者文件才能解决我们要完成的工作。比如我们要完成一项编程工作,那么我们需要双击IDE的快捷方式,或是点开IDE.exe文件,这样打开IDE之后我们才能完成后续的工作。但是如果你在Linux下依然使用鼠标点击的话是不是就有点奇怪了,虽然对于新手来说这是非常正常的一件事。但是如果深入学习Linux之后,你就发现,仅仅在shell中键入一系列命令我们便可以完成一系列工作。当然,shell的用途远不止键入命令这一功能,我们还可以使用shell程序编写(bash高级编程属于其中一种)来管理系统,不过此博客不提及此功能(其实是博主还有没有学会)。那么接下来我们先看看让shell可以键入一系列命令的功臣——变量。
(环境)变量
所谓变量,就是计算机中用于记录一个value的符号,而这些符号将用于不同的运算处理。其实大家第一次接触变量应该都是在编程的时候,例如c语言中,设定一个全局的整形int变量,则在整个程序中都可以使用该变量。其实Linux中也是如此,只不过我们习惯把shell中的全局变量称之为环境变量,即不仅仅能在当前shell下使用,而是在任意shell下均可使用的一种变量,相对的局部变量称之为变量。那么我们为何要使用变量呢?我们来看环境变量的优点。
- 方便记忆,便于修改。
- 为各个不同的用户高度定制个性化系统提供便捷。
对于第一点可能比较好理解,第二点可能不是那么容易体会了。我们从系统本身来看,在登录Linux系统之前,也即进入shell之前,系统需要一些环境变量来辨识该用户的shell,以方便之后的使用,而这些环境变量即是我们通常提到的LANG、PATH、HOME等等。我们举个例子,一个学霸和一个学渣同时使用一台计算机学习Linux,学霸想用英文而学渣当然想用中文了。在Windows下的话可能就很难办了,但是Linux就不同了,在不同用户的shell下直接对环境变量LANG进行设置就好啦。学霸的用户使用export LANG=en_US.utf-8命令,而学渣的则使用export LANG=zh_CN.utf-8就完美解决问题啦!
环境变量的使用大大提升了Linux的使用体验,这里贴上一些常用的变量设定规则以便日后参考。 - var="lang is $LANG" 双引号内的特殊字符如 $ 等,可以保有原本的特性 lang is en_US.utf-8
- var='lang is $LANG' 单引号内的特殊字符则仅为一般字符 (纯文本) lang is $LANG
- var=`command` or var=$(command) 在一串指令的执行中,还需要藉由其他额外的指令所提供的信息时,可以使用反单引号『
指令』或 『$(指令)』 - export var 使得该变量成为环境变量
- PATH="$PATH":/home/bin or PATH=${PATH}:/home/bin 若该变量为扩增变量内容时,则可用 "$变量名称" 或 ${变量} 累加内容
当然,每个shell下都有自己的环境配置文件,基于博主的水平,这个问题还有待进一步的学习。
难点和问题及思考过程
Linux是一个庞大复杂但功能强大的系统,学习的过程中必须循序渐进,不断提出问题并想方设法的解决问题,这样才能更好的掌握Linux这个系统。
难点 crontab例行性工作
实话说,对于初学者来说,这是个较为复杂的命令,即使它的功能非常强大。首先,我们使用man手册进行查看,可以知道crontab就是一项循环执行的例行性工作排程。而crontab命令有三个参数,分别为-e,-l,-r,-e表示编辑crontab文件以进行例行性工作设置,-l表示查看当前用户下的crontab文件中的例行性工作任务,-r表示删除所有的crontab文件中的例行性工作任务。接着,我们看看crontab的格式
Example of job definition:
.---------------- minute (0 - 59)
| .------------- hour (0 - 23)
| | .---------- day of month (1 - 31)
| | | .------- month (1 - 12) OR jan,feb,mar,apr ...
| | | | .---- day of week (0 - 6) (Sunday=0 or 7) OR sun,mon,tue,wed,thu,fri,sat
| | | | |
* *** * user-name command to be executed
格式标注的非常详细,简单说来,就是前面五个通配符表示的是不同的时间位,而在crontab会根据所设定的时间来执行设定的命令。当然,对于每个时间位,其中还有一些可用的特殊字符。
- * 匹配任一时刻
- , 分割时段,表示逗号前后的时段均执行命令
- - 一段时间范围,具体细节同上
- /n 其中n代表数字,即每隔n单位间隔执行一次。
举个例子,如果我要每隔五分钟执行用户主目录下的test.sh脚本文件,我应该这样写*/5 * * * * ~/test.sh。
在man手册我们发现还有三个相关的文件,分别是: - /etc/cron.allow
- /etc/cron.deny
- /var/spool/cron/crontabs
其中allow表示白名单,deny表示黑名单,即进入白名单的用户就可以使用crontab程序,其中allow的优先级高于deny,但不建议将同一用户写入两个文件夹中。而/var/spool/cron/crontabs则表示的每个用户的crontab文件,即每个用户的crontab命令都放置在此文件中。当我们使用crontab -e命令时进入的即为此文件。
总体说来,crontab并不难,只是对于初学者来说较为复杂,在多学习多接触之后就问题不大了。
难点 数据流重导向&管道命令
看着这几个术语,我的内心反应是拒绝的。Linux对于新手也太不友好了!这几个东西从字面上完全看不懂是什么意思啊!但是,该学的还是要学的,这也将是Bash命令中最难且最重要的一点。
之前提到了bash命令以及变量,那些都是shell下必备的工作,这里我们要谈的,将紧紧围绕这标准输入流与标准输出流。那么首先,我们来谈谈标准输出流和标准输入流是什么。
标准输入流、标准输出流以及标准错误输出流
先上张图:
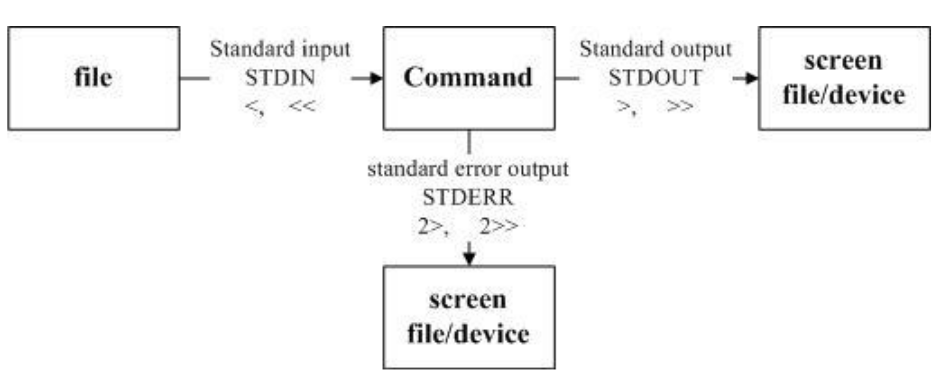
我们执行一个指令的时候,这个指令可能会由文件读入资料,经过处理之后,再将数据输出到屏幕上。在上图当中, standard output 与 standard error output 分别代表标准输出 (STDOUT)与标准错误输出 (STDERR),简单来说,在输出流中说标准这个词是针对命令来说的,不管是哪个流,都是在执行命令后流出的信息。所以标准输出流即为执行命令后正确的信息输出,错误输出流即为错误的信息输出,输入流中的信息输入方式则比较多,可以是键盘输入也可以是文件内容。例如cat file1 > file2,这其实一个复制的命令,但是它使用的就是标准输出。以上三种流都有属于自己的特殊字符:
- 标准输入 (stdin) :代码为 0 ,使用 < 或 << ;
- 标准输出 (stdout):代码为 1 ,使用 > 或 >> ;
- 标准错误输出(stderr):代码为 2 ,使用 2> 或 2>> ;
其中>表示覆盖,>>表示从尾处添加。同时,这里的特殊字符其实是文件描述字符。在shell中存在着9个文件描述字符。系统仅仅使用了0,1,2表示上述三种流,而其余的3-8都可以进行自定义设置。这里我们就不再过多讨论了。
了解了以上三种流之后,我们才能更好理解所谓的数据流重导向。
大多数时候我们都会把命令用错,这时候我们就想把这些烦人的错误信息放置在文件而不显示,那么我们应该怎么做呢?
find /home -name .bashrc > list_right 2> list_error
这样一来,对的信息就重导向到文件list_right中了,而错误信息则重导向至文件list_error中了。
$ cat > catfile << "eof"
> This is a test.
> OK now stop
> eof
$ cat catfile
This is a test.
OK now stop
上述是一段通过键盘输入来导向至catfile文件中的一段命令。
管道命令
了解了数据流重导向之后,管道命令就很好理解了。不同与;,&&,||,管道命令|仅能处理经由前一个命令传来
的正确信息,即标准输出,同样的,在|后面的命令也必须要能接受标准输入的数据才行,只有这样的命令才能称之为管道命令。
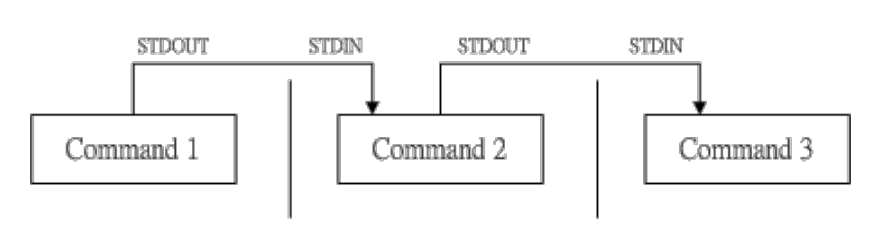
管道命令的真正含义到此已经解释完毕,至于详细的管道命令说明就不在此处一一列出,可以参看私房菜,里面有非常详细的命令说明。
学习“实验楼”过程中的问题及解决方法
此处的问题大多来自于每章节的课后作业或是测试,其他的问题大多已经归并到上述的博客中。
问题一 找出当前目录下面占用最大的前十个文件
开始一直思考使用du命令,因为此命令就是用于显示文件和目录的大小,于是使用管道命令组合,得出结论:
du -ah . | sort -n -r | head -10
但是结果也令人失望:
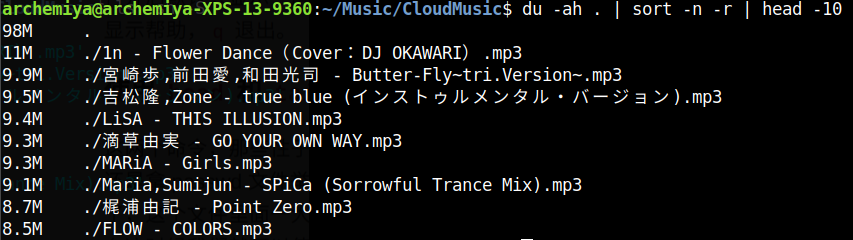
因为du命令会输出目录,而所有目录下都会包含当前目录,因此结果中始终包含最大的当前目录。思考良久,发现ls本身作为显示文件信息的命令就可以使用参数进行排序,于是: `ls -sh -S | head -10 `
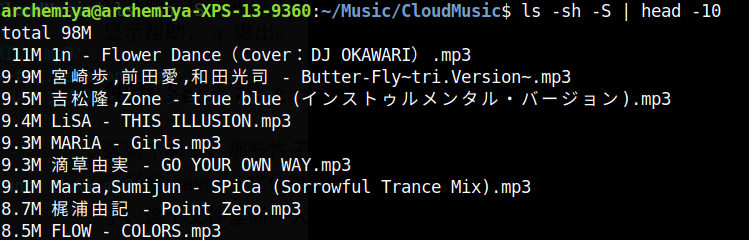
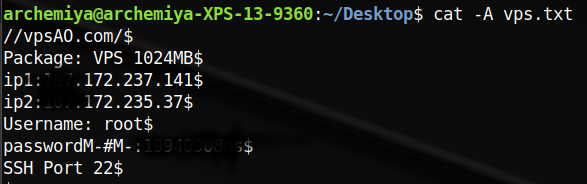
其中 - -s, --size print the allocated size of each file, in blocks - -S sort by file size, largest first ####问题二 Windows/dos 与 Linux/UNIX 文本转化 >断行符 Windows 为 CR+LF( ),Linux/UNIX 为 LF( )。使用cat -A 文本 可以看到文本中包含的不可见特殊字符。Linux >的 表现出来就是一个$,而 Windows/dos的表现为^M$,可以直接使用dos2unix和unix2dos工具在两种格式之间进行转换,使用>file命令可以查看文件的具体类型。 >不过现在希望你在不使用上述两个转换工具的情况下,使用前面学过的命令手动完成 dos 文本格式到 UNIX 文本格式的转换。
此题需用到tr命令进行特殊字符的删除:
cat file1.txt | tr -d '
' > file2.txt
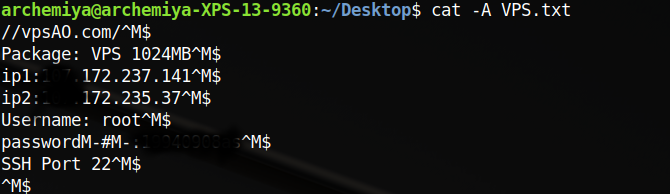
但是此命令没法从原文件直接输出到原文件。
问题三 数据提取
介绍
小明在做数据分析的时候需要提取文件中关于数字的部分,同时还要提取用户的邮箱部分,但是有的行不是数组也不是邮箱,现在需要你在>data2这个文件中帮助他用正则表达式匹配出数字部分和邮箱部分。在这里下载
wget http://labfile.oss.aliyuncs.com/courses/1/data2
将下载的data2保存在/home/shiyanlou/data2
目标
在文件data中匹配数字开头的行,结果写入/home/shiyanlou/num文件
在文件data中匹配出正确格式的邮箱,结果写入一个名为/home/shiyanlou/mail的文件
此题是典型的正则表达式匹配。贴上匹配的正则表示式:
- 数字开头的行
grep '^[0-9].*' - 邮箱
grep '[[:alnum:]]*@[[:alnum:]]*.[[:alnum:]]*'
最后
虽然还有很多关于进程等的内容没有搞透,但是Linux的学习不是一朝一夕就可以完成的,写博客也是为了督促自己不断的加紧Linux的学习步伐,当然,博客本身也是中乐趣所在。继续加油吧!