前言:传统的数据挖掘中都是在提取特征上做文章,而这又很大程度上取决于工程师自身的特征工程能力以及业务处理中的多年经验,所以想写一篇文章总结下这其中有脉可循的规律
摘要:
1.特征的可用性评估
2.特征的修剪
3.特征的可视化
4.特征的监控
5.特征的维护
内容:
1.特征的可用性评估
如果特征的缺失率高,并且不是重要性特征,可以直接弃用
如果特征方差小,说明特征的区分性并不高,可以删去这部分特征
2.特征的修剪:
识别对于模型有害的离群值/异常值(3倍标准差),或者只取数据分布中占80%的数据,丢掉长尾的20%
缺失值填充,如果是类别/离散型变量推荐填充一种新的类别;如果是实变量,推荐填充均值。减少可能造成的噪音。
去重,原始数据可能存在误报或者重复记录等问题,通过去重降低噪音,保证数据合理性,减少计算量。
其他处理,比如离散化,归一化,标准化,独热编码等,这些处理有益于减少计算量,或者规范化的处理,提高模型表现
3.特征可视化 :
单变量相关性分析与可视化
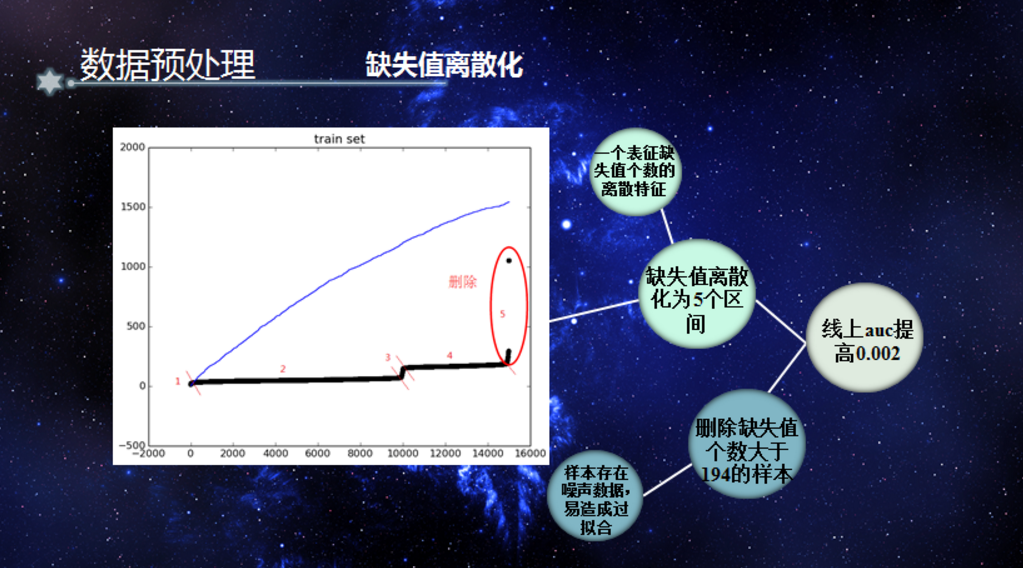
特征分布
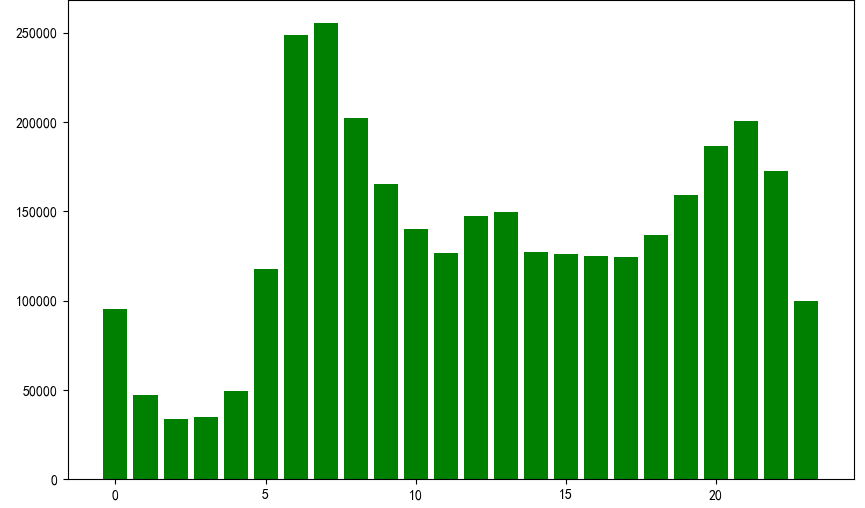
上图是2017“达观杯”个性化推荐算法挑战赛的每小时资讯阅读量的统计,细心的读者会发现早6点到早9点以及晚19点到晚22点是阅读的高峰期,其与用户实际的阅读情况也相符,
通过对数据的可视化与探索性分析(EDA),可以加深我们对数据的理解,同时做到去其糟粕,取其精华。
4.特征处理:
一般情况下特征处理会包括特征生成和特征选取等几个阶段
在特征生成阶段,根据实际的业务场景不同,选择以下几种特征进行深挖:
统计特征:count,sum,avg,diff,var/std,skew,kurt(这4项在线性回归中经常被使用)
比值特征:转化率,好评率,点击率,留存率,跳出率,以及其他放缩到01区间的特征
时间特征:累积,平均,同比,环比,间隔,频次,以及时序特征(滑动窗口)
空间特征:地区的经纬度,地域分级(1/2/3),地域分布,地理距离
排名特征:对异常数据有更强的鲁棒性,使得模型更加稳定
特征转换:平滑/多项式变换/离散化(等频/等宽)/哑变量
交叉特征:地理的经纬度
组合特征:树模型的叶结点路径(判别性高的特征),x^2+y^2,1/x+1/y,log(xy)
nnz特征/nz特征:一个样本的缺失值越多,可能会蕴含有一些信息,可以通过统计0值的个数进行表达
hash trick:对样本的特征做哈希变换,减少特征维度
在特征选取阶段,减少特征数量,可以减少过拟合的风险,较少计算量和增加模型的泛化能力
特征的选取:根据PCA的原理,如果top k个特征或者特征值足以表达数据分布中的80%,那可以只保留着80%的少数特征(值)
特征的选取:树模型和逻辑回归等可以得到特征评分的模型刷选重要特征
监控特征的变化,当重要特征的评分降低,或者数据变化较大时,及时报警进行处理