一。 安装前配置
- java环境,一般linux中都有
- hadoop环境
- python环境,一般linux中会默认安装
- scala环境,需要下载
- spark 软件,需要下载
二。 scala安装配置
- 下载scala压缩包
sudo tar -zxvf scala-2.11.6.tar.gz2. 添加环境变量
sudo vim ~/.bashrcexport SCALA_HOME=/usr/local/scala-2.11.6
export PATH=$PATH:$SCALA_HOME/bin
source ~/.bashrc3. 查看是否安装成功,打开终端,输入Scala
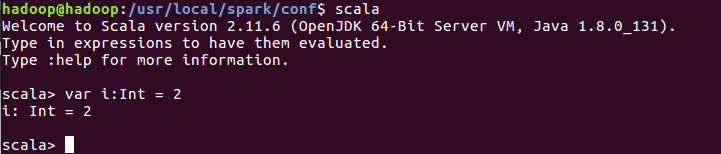
三。 spark安装配置
- 下载spark压缩包,解压到/usr/local目录,并重命名
sudo tar -zxvf spark-2.0.1-hadoop7.tar.gz
sudo mv spark-2.0.1 spark2. 修改spark配置文件
cd /usr/local/spark/conf
ls
sudo cp spark-defaults.conf.template spark-defaults.conf
sudo cp spark-env.sh.template spark-env.sh
sudo cp slaves.template slaves
sudo vim spark-env.sh
sudo vim slaves
sudo vim spark-site.xml
spark-env.sh 其中SPARK_LOCAL_IP和SPARK_MASTER_IP均为主机名或你的IP地址,还有SPARK_HISTORY_OPTS的hdfs目录需要修改为主机名或者IP地址
export JAVA_HOME=/usr/local/java-8-openjdk-amd64
export HADOOP_HOME=/usr/local/hadoop
export SPARK_HOME=/usr/local/spark
export SCALA_HOME=/usr/local/scala-2.11.6
export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop
SPARK_LOCAL_IP=hadoop
SPARK_MASTER_IP=hadoop
SPARK_MASTER_WEBUI_PORT=8080
SPARK_WORKER_WEBUI_PORT=7070
SPARK_LOCAL_DIRS=$SPARK_HOME/local_dirs
SPARK_WORKER_DIR=$SPARK_HOME/worker_dirs
SPARK_LOG_DIR=$SPARK_HOME/log_dirs
SPARK_WORKER_CORES=1
SPARK_WORKER_MEMORY=512M
export SPARK_MASTER_OPTS="-Dspark.deploy.defaultCores=1"
export SPARK_WORKER_OPTS="-Dspark.worker.cleanup.enabled=true -Dspark.worker.cleanup.appDataTtl=604800"
export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=18080 -Dspark.history.retainedApplications=3 -Dspark.history.fs.logDirectory=hdfs://hadoop:9000/historyserverforspark"
slaves 修改为主机名或IP地址,使用localhost也是可以的
hadoopspark-defaults.conf 修改为你的FS.default的IP或者主机名,localhost
spark.eventLog.enabled true
spark.eventLog.compress true
spark.eventLog.dir hdfs://hadoop:9000/historyserverforspark
spark.broadcast.blockSize 8m
spark.executor.cores 1
spark.executor.memory 512m
spark.executor.heartbeatInterval 20s
spark.files.fetchTimeout 120s
spark.task.maxFailures 6
spark.serializer org.apache.spark.serializer.KryoSerializer
spark.kryoserializer.buffer.max 256m
spark.akka.frameSize 128
spark.default.parallelism 20
spark.network.timeout 300s
spark.speculation true
3. 启动Hadoop
4. 启动spark 多了两个进程master和worker
hadoop@hadoop:/usr/local$ cd spark/sbin/
hadoop@hadoop:/usr/local/spark/sbin$ ./start-all.sh
starting org.apache.spark.deploy.master.Master, logging to /usr/local/spark/log_dirs/spark-hadoop-org.apache.spark.deploy.master.Master-1-hadoop.out
hadoop: starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/spark/log_dirs/spark-hadoop-org.apache.spark.deploy.worker.Worker-1-hadoop.out
hadoop@hadoop:/usr/local/spark/sbin$ jps
10515 DataNode
11524 Master
11094 NodeManager
10359 NameNode
11625 Worker
11724 Jps
10717 SecondaryNameNode
10959 ResourceManager
hadoop@hadoop:/usr/local/spark/sbin$ 四。 spark的使用
1. 启动spark ./spark-shell
hadoop@hadoop:/usr/local/spark/sbin$cd ../bin
hadoop@hadoop:/usr/local/spark/bin$ ./spark-shell
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel).
18/03/22 11:25:49 WARN spark.SparkConf: The configuration key 'spark.akka.frameSize' has been deprecated as of Spark 1.6 and may be removed in the future. Please use the new key 'spark.rpc.message.maxSize' instead.
18/03/22 11:26:07 WARN spark.SparkConf: The configuration key 'spark.akka.frameSize' has been deprecated as of Spark 1.6 and may be removed in the future. Please use the new key 'spark.rpc.message.maxSize' instead.
18/03/22 11:26:07 WARN spark.SparkConf: The configuration key 'spark.akka.frameSize' has been deprecated as of Spark 1.6 and may be removed in the future. Please use the new key 'spark.rpc.message.maxSize' instead.
18/03/22 11:26:07 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
18/03/22 11:26:10 WARN spark.SparkContext: Use an existing SparkContext, some configuration may not take effect.
18/03/22 11:26:10 WARN spark.SparkConf: The configuration key 'spark.akka.frameSize' has been deprecated as of Spark 1.6 and may be removed in the future. Please use the new key 'spark.rpc.message.maxSize' instead.
Spark context Web UI available at http://127.0.1.1:4040
Spark context available as 'sc' (master = local[*], app id = local-1521689169017).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_ / _ / _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_ version 2.0.1
/_/
Using Scala version 2.11.8 (OpenJDK 64-Bit Server VM, Java 1.8.0_131)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
2. spark的web界面 http://hadoop:8080
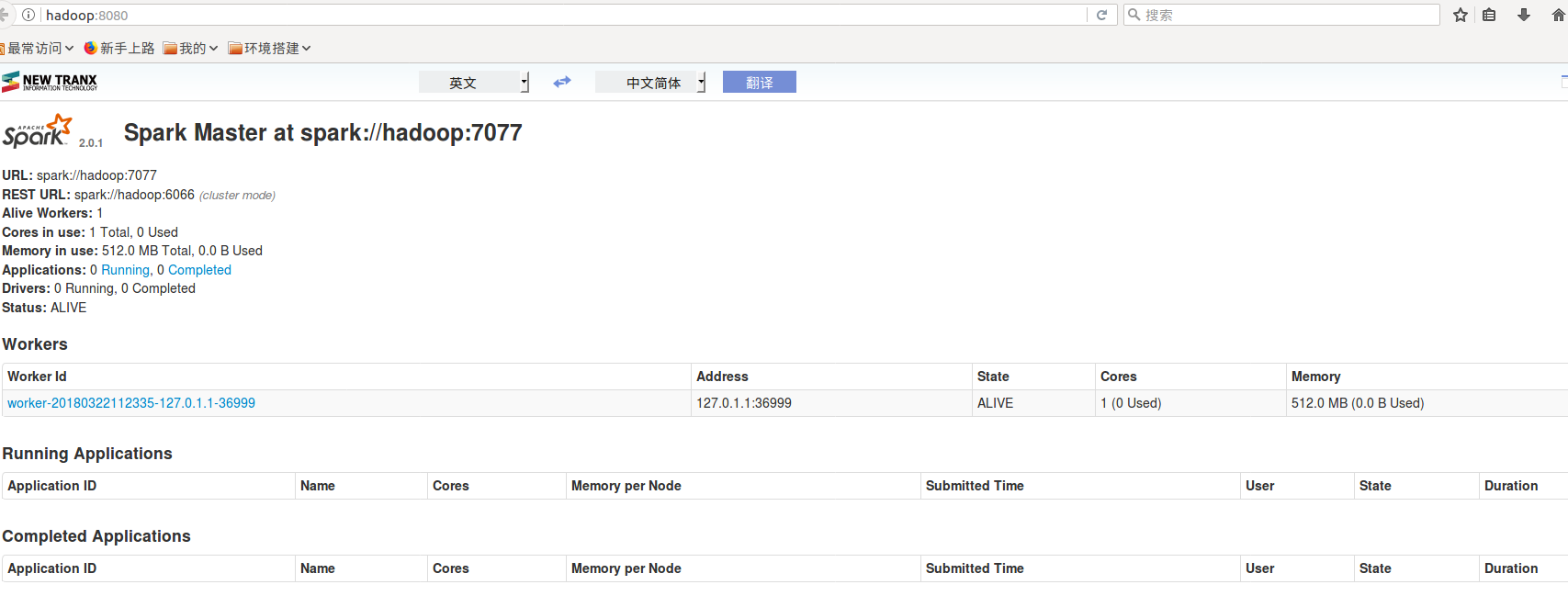
3. spark 7070 从节点的 http://hadoop:7070 从节点的参数
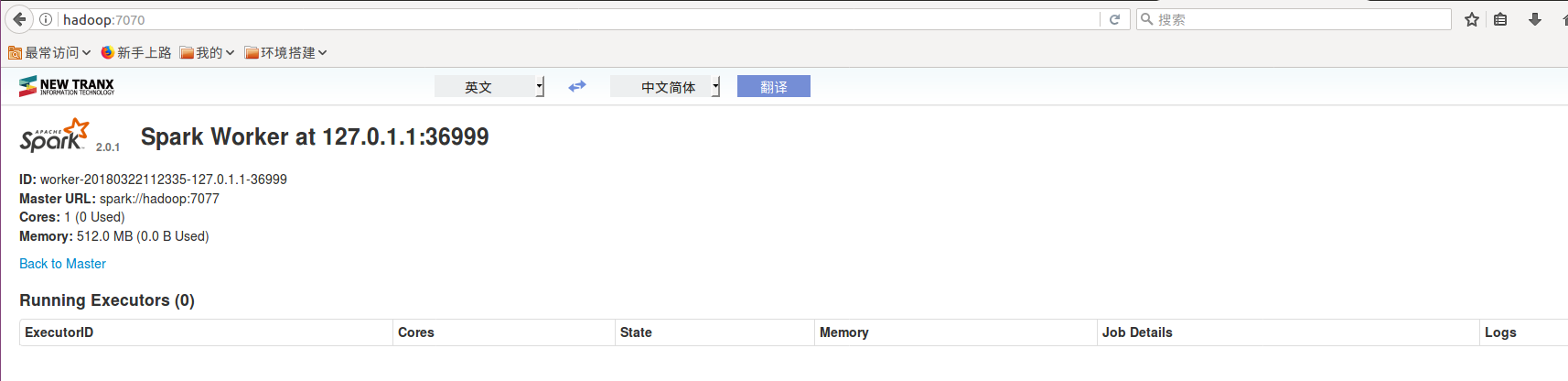
4. spark 的运行
scala> var file=sc.textFile("hdfs://hadoop:9000/hadoopin/wordcout/wc.txt")
file: org.apache.spark.rdd.RDD[String] = hdfs://hadoop:9000/hadoopin/wordcout/wc.txt MapPartitionsRDD[1] at textFile at <console>:24
scala> file.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect
res0: Array[(String, Int)] = Array(("",1), (linux,1), (home,2), (java,3))
scala>