NLP问题如果要转化为机器学习问题,第一步是要找一种方法把这些符号数学化。
有两种常见的表示方法:
One-hot Representation,这种方法把每个词表示为一个很长的向量。这个向量的维度是词表大小,其中绝大多数元素为 0,只有一个维度的值为 1,这个维度就代表了当前的词。例如[0,0,0,0,0,0,0,0,1,0,0,0,0,0,0,0,0]。这种表示方法会造成“词汇鸿沟”现象:不能反映词与词之间的语义关系,因为任意两个词都是正交的;而且,这种表示的维度很高。
Distributed Representation,表示的一种低维实数向量,维度以 50 维和 100 维比较常见,这种向量的表示不是唯一的。例如:[0.792, −0.177, −0.107, 0.109, −0.542, …]。这种方法最大的贡献就是让相关或者相似的词,在距离上更接近了。向量的距离可以用最传统的欧氏距离来衡量,也可以用 cos 夹角来衡量。
如果用传统的稀疏表示法表示词,在解决某些任务的时候(比如构建语言模型)会造成维数灾难。使用低维的词向量就没这样的问题。同时从实践上看,高维的特征如果要使用 Deep Learning,其复杂度太高,因此低维的词向量使用的更多。 并且,相似词的词向量距离相近,这就让基于词向量设计的一些模型自带平滑功能。word2vec 是 Google 于 2013 年开源推出的一个用于获取 word vector 的工具包,word2vec模型其实就是简单化的神经网络。随便找了张图:
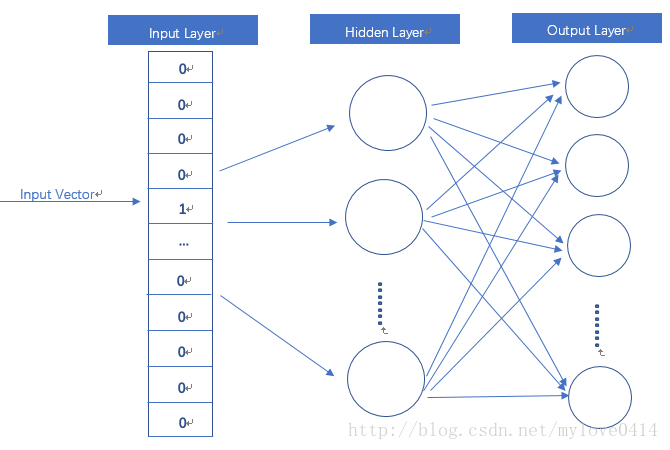
输入是One-Hot Vector,Hidden Layer没有激活函数,也就是线性的单元。Output Layer维度跟Input Layer的维度一样,用的是Softmax回归。我们要获取的dense vector其实就是Hidden Layer的输出单元。

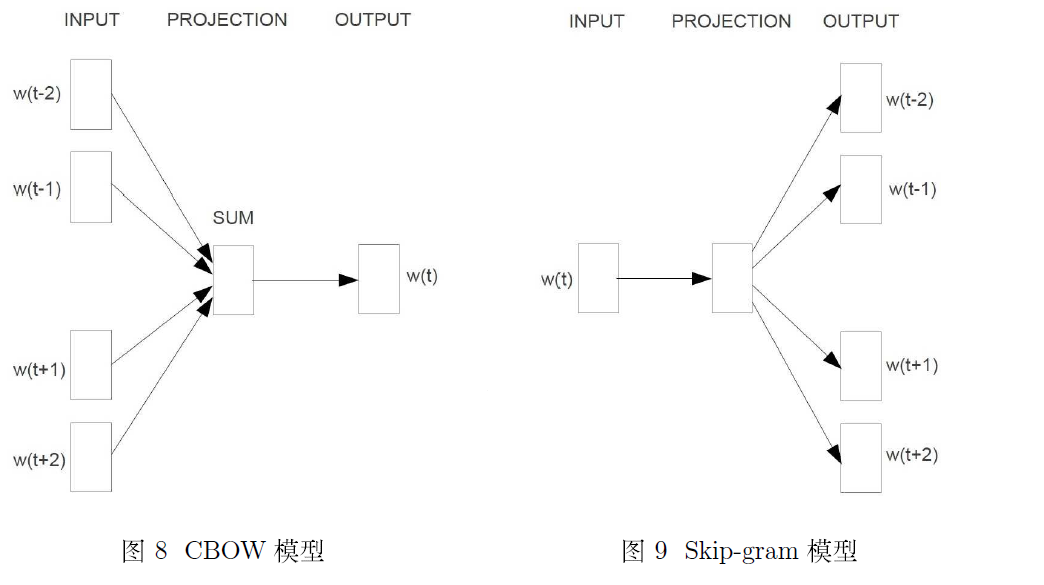
word2vec主要分为CBOW(Continuous Bag of Words)和Skip-Gram两种模式。CBOW是从原始语句推测目标字词;而Skip-Gram正好相反,是从目标字词推测出原始语句。CBOW对小型数据库比较合适,而Skip-Gram在大型语料中表现更好。