前言
简单介绍一下文档数据库。
正文
mongodb 是一个以json为数据模型的文档数据库。
这里要介绍一下什么是json。因为有些人认为'{a:1,b:2}' 是json,而"this is a" 不是json。
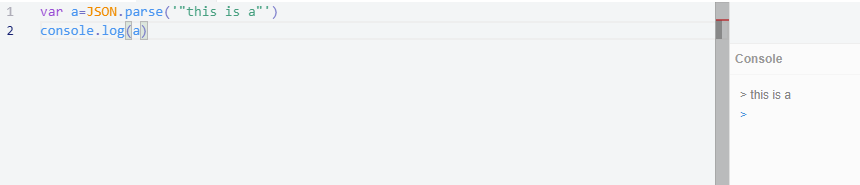
然证明这的确是一个json。事实证明数组也是。

所以不能把json想的过于狭义。
可以看下百度百科:
https://baike.baidu.com/item/JSON/2462549?fr=aladdin
那么什么是文档数据库?
从1989年起,Lotus通过其群件产品Notes提出了数据库技术的全新概念-"文档数据库",文档数据库区别于传统的其它数据库,它是用来管理文档。在传统的数据库中,信息被分割成离散的数据段,而在文档数据库中,文档是处理信息的基本单位。一文档可以很长、很复杂、可以无结构,与字处理文档类似。一个文档相当于关系数据库中的一条记录。
因为mongodb 是文档数据库,且是以json为数据模型的,那么可以想想,mongdb的最小单位就是一个文档,也就是mongodb里面的一条记录或者说一个json。
我们知道mongodb是开源的,为什么开源呢? 其实这就是一种新的市场模式,而不仅仅说互联网时代开源style,要知道天下没有免费的午餐。
mongodb 是 mongodbBD Inc的上市公司开发的,提供mongodb服务的。有人会想mongodb 开源了,别人不就免费了吗?这不得亏本,还能搞上市。
要知道一个公司如果使用mongodb到达一定的时候,是要有方案才能维护用户,这就是mongodb Inc的业务,业务才是赚钱的。开源并不会影响该公司的收入,同样的还多了这么多测试实例,所以不用想到别人开源免费让你使用,就好像占了多大便宜一样。
mongodb 有两个版本,一个是社区版一个是企业版。社区版基于SSPL,一种和AGPL基本类似的开源协议,企业版是基于商业协议,需要付费的。
使用用给产品,那么需要知道其中的历史。
-
0.x 2008 可以说是mongdb的诞生,可以用来存储然后读取。
-
1.x 2010 提供了复制集和分片集,这个时候提供高可用了。
-
2.x 更丰富的数据库功能,以前几乎只是单纯的读取和写入,跟丰富的数据库就加入了很多功能,如聚合等。
-
3.x 收购WiredTiger 和发展周边生态环境,这个时候mongodb才走向成熟了。 因为当时mongodb 有了数据引擎,也就是有了带有芯片的发动机,这个时候mongodb 很多提的bug,或者速度问题得到解决了。
所以市场上大多数应该是3.x以上的,毕竟没有芯片的发动机还是相当危险的。
- 4.x 2018 分布式事务支持,所以要想使用事务,那么需要使用4 以上的版本。
现在很多公司开始使用mongodb了,为什么要使用呢? 其优势是什么。
说一下个人使用情况,因为微服务的使用,说一说mongodb相比其他数据库的优点。
微服务讲究一个服务自治的概念,也就是说每一个服务其实都是有一个数据库的。
那么这个时候就面临选择了,选择关系型数据库还是非关系型数据库了。
这个时候应该大部分时候会使用非关系型数据库,为什么这么说呢?
因为微服务的服务自治,该服务一般设计的业务比较简单。
比如一个account服务,里面有用户信息,用户的团队信息,用户的等级信息。他们都是信息,但是他们之间没有什么联系,其实也就是记录,故而非关系数据库好些,这样设计模型也简单一些。
然后还有一个就是比如说account 服务存储用户信息,那一条用户信息里面增加了一个字段,那么其实是可以之间在代码中增加该字段的写入,而不需去增加一个像关系数据库里面一样去改变表的结构。
我们知道如果去修改表的结构的话,还是一个风险高的事件,不是说增加字段这个操作有多危险,而是增加字段的时候,其实会修改每一条记录的数据,如果遇到庞大的数据体,还是会影响到线上的,mongodb 对此还是非常灵活的。
可以看到mongodb 非常灵活,因为mongodb 太灵活了,那么太灵活的东西也有不好的问题,那就是比如我们sex这个字段,要不是男要不是女,那么不得对其进行约束?
事实上mongodb也提供了jsonSchema这个东西来进行约束了。https://www.docs4dev.com/docs/zh/mongodb/v3.6/reference/reference-operator-query-jsonSchema.html
这东西不一定要用,如果我们在应用层面没问题的话,其实是不需要的。
mongodb 使用过程还发现其一个设计特点,比如说有一个网关api的权限表设计:
{
userId:"xxx",
permission:[// 相关权限]
}
以我们的关系模型设计呢,这个permission可能就是一张表了,而在此,只是一个属性。
又比如说用户设置密码找回3个问题:
{
userid:"",
questions:[
{
'question':'xxx',
'answers':'xxx'
},
....
]
}
这条记录就可以覆盖一个场景。
这些都是简单的场景,如果复杂的场景,那么在关系数据库中你需要建立的表就更多了,那么表与表之间连接查询,效率可想而知。
mongodb 能够通过简单的设计就能够覆盖一些复杂的业务模型了,这样在代码层面上也就简单了很多了。
就像前面说的,几张表的联合查询,一张表一次行记录即可查出,那么代码的设计也很简单,代码越简单,那么维护性也就好。初学者可能觉得代码看起来越牛逼越好,其实大道至简。
除了有些业务使用mongodb能得到设计上的简化外,还有一些也需要用到。
比如说,数据行业,需要大量快速的存储,mongodb的存储是非常快的,结构也灵活。
还有一个特点就是高可用和横向扩展能力。
比如说mysql,如果数据达到1个亿,那么是会出现不流畅的,这个时候就需要重新设计和各种优化了。但是mongodb,如果达到一个亿,那么只需要使用mongodb的横向扩展能力,对于mongodb而言,这一切才刚刚开始,其定位是TB-PB级的。
当然这是数据行业很容易遇到的场景,其他的可能没有这么快达到一个亿数据。mongodb的横向扩展和高可用方案还是可以的。
结
下一节正式开始。