FoveaBox: Beyond Anchor-based Object Detector
Intro
本文是一篇one-stage anchor free的目标检测文章,大体检测思路为,网络分两路,一路预测k个channel的map,每个channel代表一个类别的概率,即输出为w×h×k,另一路预测位置,输出即为w×h×4。想法其实很容易想到,但是本文之所以work我认为很重要的一个trick是gt label的分配,positive area和negative area,回归是预测log偏移,。
我本来看了abstract之后以为是预测whk的label map,然后根据这个map上某个类别的分布去确定框,然后利用这里的信息去修正框的位置。然后看了图发现是两路预测,我直观感觉他可以合并成一路,其中cls map作为中间层输出,或者是回归支路利用上cls map的信息。
Method
Backbone是FPN,FPN的每层后面接一个subnet,subnet分为两路分别去预测cls map和回归位置。
如图所示就是大体结构:
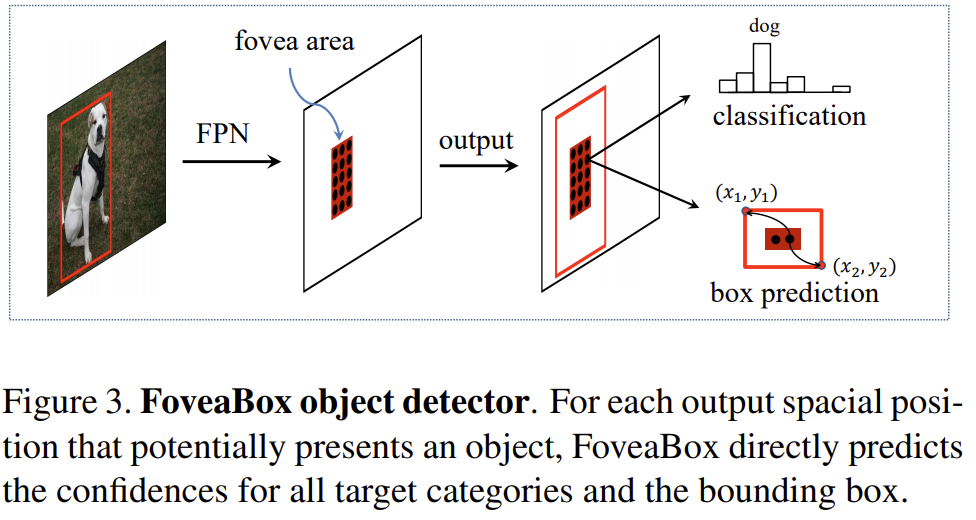
这就是本文的想法,那么有了这个想法,下一个问题就是怎么训练,哪些位置我要分配为参与训练的样本,如何分配?
作者的想法就是,首先gt在特征图上映射了一个区域,这个区域向内缩放得到一个小box认为是正样本,对应一个类别,这个区域向外放大得到一个大box,大box和小box之内认为是困难样本不参与训练,大box之外认为就是负样本,所以正样本的数量往往是比较小的,可能就那么几个点被分为正样本,取决于缩放的系数。
公式为:

l是fpn的层index。公式3就是将gt映射到对应fpn层的feature map,然后求出映射后的box的中心c,公式4就是进行缩放和扩增的操作,以确定正负样本。
上面分类说完了,然后就是回归,
回归转换为根据feature map上一点对应层和对应的xy方向index映射到原图上,与gt做差之后变换,网络学习到的是一种变换。由公式5可见x、y其实是在特征图上的位置,然后除以尺度z取log使网路更容易学习到目标。
网络学习到的就是t。

加0.5可以防止出现log0.
思考
- FoveaBox是两路预测的,如我上面说的,能否一路完成,假设我们先训练cls map,那么当cls map确定了,其实理论上可以帮助loc框定位的学习的。所以思考是否可以将cls map和feature同时作为loc层的输入,两个信息结合来帮助回归框的学习。
- 关于标签的分配作者是采用了一个系数进行缩放和放大划分,能否使用正态分布对label进行分配,靠近中间概率接近1,靠近旁边概率减小,一定阈值以外认为是负样本。
- 可否换一种回归方式,比如年龄识别中用的coarse-to-fine的stage-wise-regression方式来回归框,比如一个框的坐标值121 可以由三个不同粒度的值相加得到,121 = 100 + 20 + 1。