大数据时代虽然给我们的生活带来了很多的便利,但是往往我们想要获取或整理我们想要的资源却还是一件很难的事情,难在查找和搜寻资料,有了可共享数据的网站,却还要一页一页的点进去,筛选我们想要的信息,是不是很麻烦?是的,那么,这个时候你一定要有一个会写爬虫的朋友(或者男朋友^_^),前几次我们也已经实现了利用webcollector和htmlparser爬取网易云音乐和豆瓣图书,但是有很多网友评论说看不懂或者不明白,而且网上的资源少之又少,我自己其实也在摸索阶段,确实关于爬虫的资料很少,想买本书来学学,都没有找到适合入门的书籍,要么都是高深的理论,要么就是合并在搜索引擎里的一部分,总之,还是要靠我们自己通过查找资料,看看帮助文档,不断摸索一点一点积累起来的。
今天,我们就一起来学一下利用Jsoup技术实现一个简单的爬虫。首先,先了解一下Jsoup的帮助文档,这里是下载地址:http://git.oschina.net/AuSiang/myBug/attach_files点击名称即可下载。
一、需求分析

关于文档部分我们就不再赘述了,大家可以有时间仔细阅读,我们直接开始我们今天的案例,利用Jsoup爬取一个简单网站的案例
首先,我们选取陕西省信用建设官方网站作为我们今天爬取的对象,我们先来分析一下这个网站,如下图:


通过分析,我们可以拿到网址也就是url:http://www1.sxcredit.gov.cn/public/infocomquery.do?method=publicIndexQuery还有方法,参数等必须的条件。
二、开发
1、我们先定义一个规则类,来存放一些需要用到的常量。
/** * */ package com.ax.bug; /** * @description:规则类 * 这个规则类定义了我们查询过程中需要的所有信息,方便我们的扩展 * 以及代码的重用,因为我们不可能针对每个需求都要写一遍 * @author AoXiang * @date 2017年3月21日 * @version 1.0 */ public class Rule { /* * 链接 */ private String url; /* * 参数集合 */ private String[] params; /* * 参数对应的值 */ private String[] values; /* * 对返回的html,第一次过滤所使用的标签,先设置type */ private String resultTagName; /* * class/id/selection * 设置resultTagName的类型,默认为id */ private int type = ID; /* * GET/POST * 请求的类型,默认为Get */ private int requestMethod = GET; public static final int GET =0; public static final int POST=1; public static final int CLASS=0; public static final int ID =1; public static final int SELECTION=2; /* * 当有参构造函数存在时,无参构造函数一定要表现出来 * 如果有参构造函数没有,无参构造函数可以不写,默认就是无参的 */ public Rule(){ } /** * @param url * @param params * @param values * @param resultTagName * @param type * @param requestMethod */ public Rule(String url, String[] params, String[] values, String resultTagName, int type, int requestMethod) { super(); this.url = url; this.params = params; this.values = values; this.resultTagName = resultTagName; this.type = type; this.requestMethod = requestMethod; } /** * @return the url */ public String getUrl() { return url; } /** * @param url the url to set */ public void setUrl(String url) { this.url = url; } /** * @return the params */ public String[] getParams() { return params; } /** * @param params the params to set */ public void setParams(String[] params) { this.params = params; } /** * @return the values */ public String[] getValues() { return values; } /** * @param values the values to set */ public void setValues(String[] values) { this.values = values; } /** * @return the resultTagName */ public String getResultTagName() { return resultTagName; } /** * @param resultTagName the resultTagName to set */ public void setResultTagName(String resultTagName) { this.resultTagName = resultTagName; } /** * @return the type */ public int getType() { return type; } /** * @param type the type to set */ public void setType(int type) { this.type = type; } /** * @return the requestMethod */ public int getRequestMethod() { return requestMethod; } /** * @param requestMethod the requestMethod to set */ public void setRequestMethod(int requestMethod) { this.requestMethod = requestMethod; } }
2、定义一个类存放需要接收的结果
/** * */ package com.ax.bug; /** * @description:需要的数据对象,也就是实体类(但我们不需要数据库做连接,直接返回输出) * @author AoXiang * @date 2017年3月21日 * @version 1.0 */ public class LinkTypeData { /* * 序号id */ private String id; /* * url链接 */ private String linkHref; /* * 链接标题 */ private String linkText; /* * 摘要 */ private String summary; /* * 内容 */ private String content; /** * @return the id */ public String getId() { return id; } /** * @param id the id to set */ public void setId(String id) { this.id = id; } /** * @return the linkHref */ public String getLinkHref() { return linkHref; } /** * @param linkHref the linkHref to set */ public void setLinkHref(String linkHref) { this.linkHref = linkHref; } /** * @return the linkText */ public String getLinkText() { return linkText; } /** * @param linkText the linkText to set */ public void setLinkText(String linkText) { this.linkText = linkText; } /** * @return the summary */ public String getSummary() { return summary; } /** * @param summary the summary to set */ public void setSummary(String summary) { this.summary = summary; } /** * @return the content */ public String getContent() { return content; } /** * @param content the content to set */ public void setContent(String content) { this.content = content; } }
我们之所以要分开定义这么多类,看起来很繁琐,其实都是为了我们的代码能够更好的重用,以及扩展和维护。
4、接下来是核心的查询类
/** * */ package com.ax.bug; import java.io.IOException; import java.util.ArrayList; import java.util.List; import org.jsoup.Connection; import org.jsoup.Jsoup; import org.jsoup.nodes.Document; import org.jsoup.nodes.Element; import org.jsoup.select.Elements; /** * @description:核心的查询类 * @author AoXiang * @date 2017年3月21日 * @version 1.0 */ public class ExtractService { public static List<LinkTypeData> extract(Rule rule) throws IOException{ // 校验url validateRule(rule); // 定义和获取变量 List<LinkTypeData> datas = new ArrayList<LinkTypeData>(); LinkTypeData data = null; String url = rule.getUrl(); String[] params = rule.getParams(); String[] values = rule.getValues(); String resultTagName = rule.getResultTagName(); int type = rule.getType(); int requestType = rule.getRequestMethod(); // 建立和url的链接(参考jsoup的用法) Connection conn = Jsoup.connect(url); // 设置查询参数 if(params != null){ for(int i=0;i<params.length;i++){ conn.data(params[i],values[i]); } } // 定义节点 Document doc = null; // 设置请求类型 switch(requestType){ case Rule.GET: doc = conn.timeout(100000).get(); break; case Rule.POST: doc = conn.timeout(100000).post(); break; } /* 根据不同的请求类型处理返回的数据,当为Id时取到的只有一个指定元素, * 所以加入elements的集合中,但是为class时,取到的已经是一个集合 * 不需要再额外添加,如果没有拿到请求参数,取全部,也就是body * 主体中的内容 */ Elements results = new Elements(); switch(type){ case Rule.CLASS: results = doc.getElementsByClass(resultTagName); break; case Rule.ID: Element result = doc.getElementById(resultTagName); results.add(result); break; case Rule.SELECTION: results = doc.select(resultTagName); break; default: if(resultTagName == null || resultTagName == ""){ results = doc.getElementsByTag("body"); } } /* * 提取结果中的链接地址和链接标题,返回数据 */ for(Element result : results){ Elements links = result.getElementsByTag("a");//可以拿到链接 for(Element link : links){ String linkText = link.text(); // 对取得的html中的 出现问号乱码进行处理 linkText = new String(linkText.getBytes(),"GBK").replace('?', ' ').replace(' ', ' '); String id = link.parent().firstElementSibling().text(); id = new String(id.getBytes(),"GBK").replace('?', ' ').replace(' ', ' '); String address = link.parent().nextElementSibling().text(); address = new String(address.getBytes(),"GBK").replace('?', ' ').replace(' ', ' '); String code = link.parent().lastElementSibling().text(); code = new String(code.getBytes(),"GBK").replace('?', ' ').replace(' ', ' '); data = new LinkTypeData(); data.setLinkText(linkText); data.setSummary(address); data.setContent(code); data.setId(id); datas.add(data); } } return datas; } /** * 对传入的参数(url链接)进行必要的校验 * @author AoXiang * @date 2017年3月21日 */ public static void validateRule(Rule rule){ String url = rule.getUrl(); if(url==null || url == ""){ throw new RuleException("url不能为空"); } if(!url.startsWith("http://")){ throw new RuleException("url的格式不正确"); } if(rule.getParams()!=null && rule.getValues()!=null){ if(rule.getParams().length!=rule.getValues().length){ throw new RuleException("参数的键值对不匹配"); } } } }
5、核心查询类中用到的异常类
/** * */ package com.ax.bug; /** * @description:异常类 * @author AoXiang * @date 2017年3月21日 * @version 1.0 */ public class RuleException extends RuntimeException { private static final long serialVersionUID = 1L; public RuleException() { super(); // TODO Auto-generated constructor stub } /** * @param message * @param cause * @param enableSuppression * @param writableStackTrace */ public RuleException(String message, Throwable cause, boolean enableSuppression, boolean writableStackTrace) { super(message, cause, enableSuppression, writableStackTrace); // TODO Auto-generated constructor stub } /** * @param message * @param cause */ public RuleException(String message, Throwable cause) { super(message, cause); // TODO Auto-generated constructor stub } /** * @param message */ public RuleException(String message) { super(message); // TODO Auto-generated constructor stub } /** * @param cause */ public RuleException(Throwable cause) { super(cause); // TODO Auto-generated constructor stub } }
三、测试
核心代码我们已经完成了,代码并不多,接下来我们进行测试,建一个单元测试类叫Test。
/** * */ package com.ax.bug; import java.io.FileOutputStream; import java.io.IOException; import java.util.List; import org.apache.poi.hssf.usermodel.HSSFCell; import org.apache.poi.hssf.usermodel.HSSFCellStyle; import org.apache.poi.hssf.usermodel.HSSFRow; import org.apache.poi.hssf.usermodel.HSSFSheet; import org.apache.poi.hssf.usermodel.HSSFWorkbook; /** * @description: * @author AoXiang * @date 2017年3月21日 * @version 1.0 */ public class Test { /** * 不带查询参数 * @author AoXiang * 2017年3月21日 */ @org.junit.Test public void getDataByClass() throws IOException{ Rule rule = new Rule( "http://www1.sxcredit.gov.cn/public/infocomquery.do?method=publicIndexQuery", null,null, "cont_right", Rule.CLASS, Rule.POST); List<LinkTypeData> extracts = ExtractService.extract(rule); printf(extracts); } /** * 带查询参数 * @author AoXiang * 2017年3月21日 */ /*@org.junit.Test public void getDatasByCssQuery() throws IOException { Rule rule = new Rule("http://www.11315.com/search", new String[] { "name" }, new String[] { "兴网" }, "div.g-mn div.con-model", Rule.SELECTION, Rule.GET); List<LinkTypeData> extracts = ExtractService.extract(rule); printf(extracts); }*/ public void printf(List<LinkTypeData> datas){ // 第一步,创建一个webbook,对应一个Excel文件 HSSFWorkbook wb = new HSSFWorkbook(); // 第二步,在webbook中添加一个sheet,对应Excel文件中的sheet HSSFSheet sheet = wb.createSheet("信用企业"); // 第三步,在sheet中添加表头第0行,注意老版本poi对Excel的行数列数有限制short HSSFRow row = sheet.createRow((int) 0); // 第四步,创建单元格,并设置值表头 设置表头居中 HSSFCellStyle style = wb.createCellStyle(); style.setAlignment(HSSFCellStyle.ALIGN_CENTER); // 创建一个居中格式 HSSFCell cell = row.createCell((short) 0); cell.setCellValue("序号"); cell.setCellStyle(style); cell = row.createCell((short) 1); cell.setCellValue("企业名称"); cell.setCellStyle(style); cell = row.createCell((short) 2); cell.setCellValue("地址"); cell.setCellStyle(style); cell = row.createCell((short) 3); cell.setCellValue("工商注册号"); cell.setCellStyle(style); for (int i=0;i<datas.size();i++) { LinkTypeData ltd = (LinkTypeData) datas.get(i); System.out.println(ltd.getId()+"======="+ltd.getLinkText()+"========="+ltd.getSummary()+"========"+ltd.getContent()); // 第五步,写入实体数据 row = sheet.createRow((int)i + 1); // 第四步,创建单元格,并设置值 row.createCell((short) 0).setCellValue(ltd.getId()); row.createCell((short) 1).setCellValue(ltd.getLinkText()); row.createCell((short) 2).setCellValue(ltd.getSummary()); row.createCell((short) 3).setCellValue(ltd.getContent()); } // 第六步,将文件存到指定位置 try { FileOutputStream fout = new FileOutputStream("F:/信用企业.xls"); wb.write(fout); fout.close(); } catch (Exception e) { e.printStackTrace(); } } }
看一下运行结果:
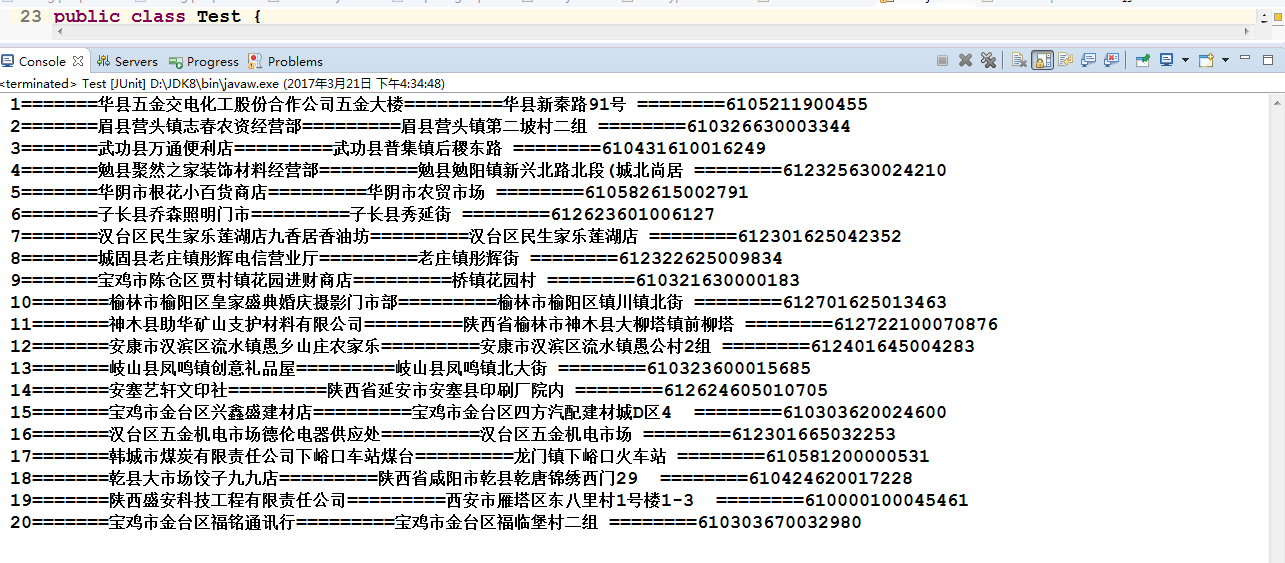

结果正是我们想要的数据,不过可能会有朋友问了,你这只是第一页的数据,如果想爬取全部的数据怎么办呢?^_^别着急,下次我们再一起学习翻页爬取的方法,好啦,今天就到这里了,我们下次见!
源码已上传至:http://git.oschina.net/AuSiang/myBug/attach_files
如果您对代码有什么异议欢迎您的留言,我们一起交流!