我们来介绍另外一种数据结构-堆,注意这里的堆和我们Java语言,C++语言等编程语言在内存中的“堆”是不一样的,这里的堆是一种树,由它实现的优先级队列的插入和删除的时间复杂度都为O(logN),这样尽管删除的时间变慢了,但是插入的时间快了很多,当速度非常重要,而且有很多插入操作时,可以选择用堆来实现优先级队列。
一、堆的定义
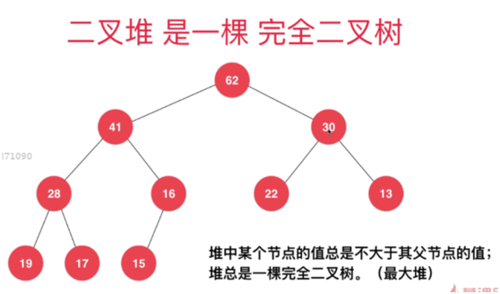
【百度百科】堆(英语:heap)是计算机科学中一类特殊的数据结构的统称。堆通常是一个可以被看做一棵完全二叉树的数组对象。堆总是满足下列性质:
- 堆中某个节点的值总是不大于或不小于其父节点的值;
- 堆总是一棵完全二叉树。
将根节点最大的堆叫做最大堆或大根堆,根节点最小的堆叫做最小堆或小根堆。常见的堆有二叉堆、斐波那契堆等。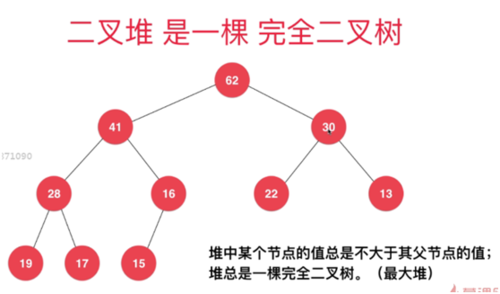
二、堆的一些实例
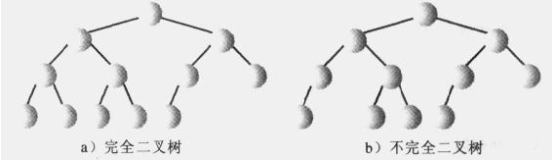
注意下面两种情况,b最后一层从左到右中间有断隔,那么也是不完全二叉树。所有a是堆,而b不是。
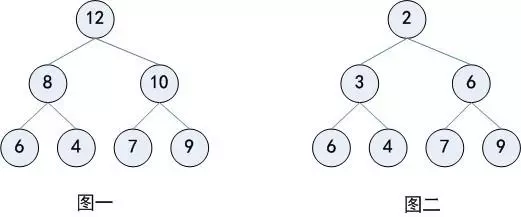
图一是最大堆,图二是最小堆:
三、堆的实现方式
堆的经典实现方式:使用数组来存储一个二叉堆,左节一次放大2倍,右节点则是2倍加1
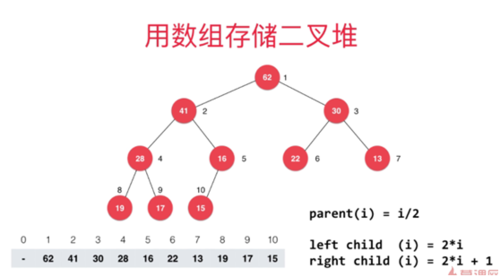
四、堆的操作
堆不是容器,而是组织容器元素的一种特别方式。 只能确定堆的范围,即开始和结束迭代器指定的范围。这意味着基本上无法对对进行遍历和查找。
因此,堆这种组织似乎非常接近无序,所以,堆的操作一般为:
- 快速的移除最大(或最小)节点;
- 快速插入新的节点。
堆有两个原始操作用于保证插入或删除节点以后堆是一个有效的最大堆或者最小堆:
shiftUp(): 如果一个节点比它的父节点大(最大堆)或者小(最小堆),那么需要将它同父节点交换位置。这样是这个节点在数组的位置上升。shiftDown(): 如果一个节点比它的子节点小(最大堆)或者大(最小堆),那么需要将它向下移动。这个操作也称作“堆化(heapify)”。
shiftUp 或者 shiftDown 是一个递归的过程,所以它的时间复杂度是 O(log n)。
基于这两个原始操作还有一些其他的操作:
insert(value): 在堆的尾部添加一个新的元素,然后使用shiftUp来修复对。remove(): 移除并返回最大值(最大堆)或者最小值(最小堆)。为了将这个节点删除后的空位填补上,需要将最后一个元素移到根节点的位置,然后使用shiftDown方法来修复堆。removeAtIndex(index): 和remove()一样,差别在于可以移除堆中任意节点,而不仅仅是根节点。当它与子节点比较位置不时无序时使用shiftDown(),如果与父节点比较发现无序则使用shiftUp()。replace(index, value):将一个更小的值(最小堆)或者更大的值(最大堆)赋值给一个节点。由于这个操作破坏了堆属性,所以需要使用shiftUp()来修复堆属性。
上面所有的操作的时间复杂度都是 O(log n),因为 shiftUp 和 shiftDown 都很费时。还有少数一些操作需要更多的时间:
search(value):堆不是为快速搜索而建立的,但是replace()和removeAtIndex()操作需要找到节点在数组中的index,所以你需要先找到这个index。时间复杂度:O(n)。buildHeap(array):通过反复调用insert()方法将一个(无序)数组转换成一个堆。如果你足够聪明,你可以在 O(n) 时间内完成。- 堆排序:由于堆就是一个数组,我们可以使用它独特的属性将数组从低到高排序。时间复杂度:O(n lg n)。
堆还有一个 peek() 方法,不用删除节点就返回最大值(最大堆)或者最小值(最小堆)。时间复杂度 O(1) 。
五、堆的用途
1.优先级队列
Java中的类PriorityQueue,可参考: PriorityQueue使用。
2.堆排序:适合处理数据量大的序列
堆排序就是利用堆删除的方法,将第一个元素和最后一个元素交换,然后size-1,在将堆里剩下的元素进行对调整,调整成一个新堆,一直到堆的size == 0,所有元素都已经排完了。
由于它在直接选择排序的基础上利用了比较结果形成。效率提高很大。它完成排序的总比较次数为O(nlog2n)。
堆排序需要两个步骤,一个建堆,二是交换重新建堆。比较复杂,所以一般在小规模的序列中不合适,但对于较大的序列,将表现出优越的性能。
3.top K 问题 :在海量数据中找出最大的前k个元素
在大量数据中找出其中最大的前k个数:可以利用堆,先将前k个数用来建堆,剩下的依次次与堆中第一个数比较(因为大堆中第一个数最大,小堆第一个数最小,这里以小堆找前k个最大的数为例),如果遇到比小顶堆的堆顶的值大的,将它放入堆中 最终的堆会是数组中最大的K个数组成的结构,在用堆排序就可以将最大的数按顺序排列。
六、内存分配中的堆区和栈区
内存中的堆和栈第一个区别就是申请方式的不同:栈是系统自动分配空间的,而堆则是程序员根据需要自己申请的空间。由于栈上的空间是自动分配自动回收的,所以栈上的数据的生存周期只是在函数的运行过程中,运行后就释放掉,不可以再访问。而堆上的数据只要程序员不释放空间,就一直可以访问到,不过缺点是一旦忘记释放会造成内存泄露。
申请效率的比较:栈由系统自动分配,速度较快。但程序员是无法控制的。堆是由new分配的内存,一般速度比较慢,而且容易产生内存碎片,不过用起来最方便。
申请大小的限制:
栈:在Windows下,栈是向低地址扩展的数据结构,是一块连续的内存的区域。这句话的意思是栈顶的地址和栈的最大容量是系统预先规定好的,在Windows下,栈的大小是2M(也有的说是1M,总之是一个编译时就确定的常数),如果申请的空间超过栈的剩余空间时,将提示overflow。因此,能从栈获得的空间较小。
堆:堆是向高地址扩展的数据结构,是不连续的内存区域。这是由于系统是用链表来存储空闲内存地址的,自然是不连续的,而链表的遍历方向是由低地址向高地址。堆的大小受限于计算机系统中有效的虚拟内存。由此可见,堆获得的空间比较灵活,也比较大。
我的微信公众号:架构真经(id:gentoo666),分享Java干货,高并发编程,热门技术教程,微服务及分布式技术,架构设计,区块链技术,人工智能,大数据,Java面试题,以及前沿热门资讯等。每日更新哦!

参考资料:
- https://www.cnblogs.com/ysocean/p/8032660.html
- https://www.jianshu.com/p/5f148c3e4f7d
- https://www.imooc.com/article/details/id/37044
- https://www.cnblogs.com/sxkgeek/p/9662491.html
- https://blog.csdn.net/szu_crayon/article/details/81812946
- https://blog.csdn.net/A__B__C__/article/details/82832511
- https://blog.csdn.net/qq_34115899/article/details/79389066
- https://blog.csdn.net/qq_34115899/article/details/82314829