第四周:卷积神经网络Part3
视频学习:循环神经网络
1.绪论
- 循环神经网络的基本应用:
语音问答、机器翻译、股票预测、作词机、作诗、图像理解、视觉问答等; - 循环神经网络与卷积神经网络:
循环神经网络:处理时序关系的任务;
卷积神经网络:输入与输出之间是相互独立的;
2.基本组成结构
-
基本结构:两种输入、两种输出、一种函数
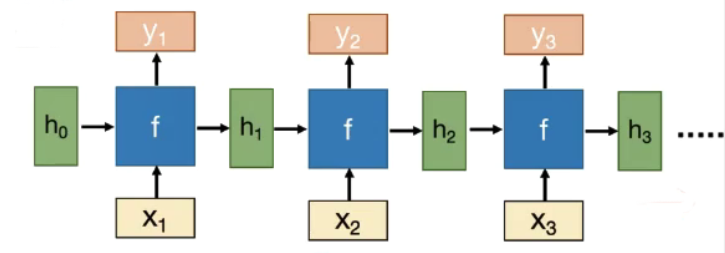
-
f被不断重复利用;
-
模型所需要学习的参数是固定的;
-
无论我们的输入长度是多少,我们只需要一个函数f;
-
深度RNN
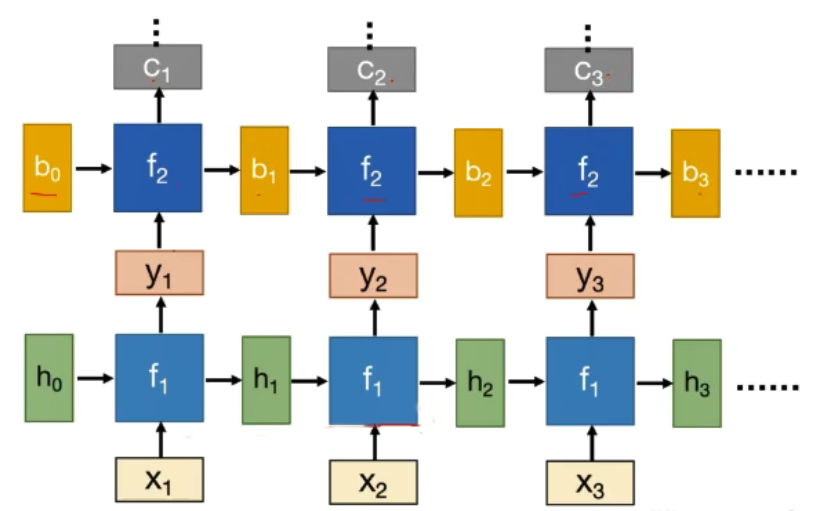
-
双向RNN
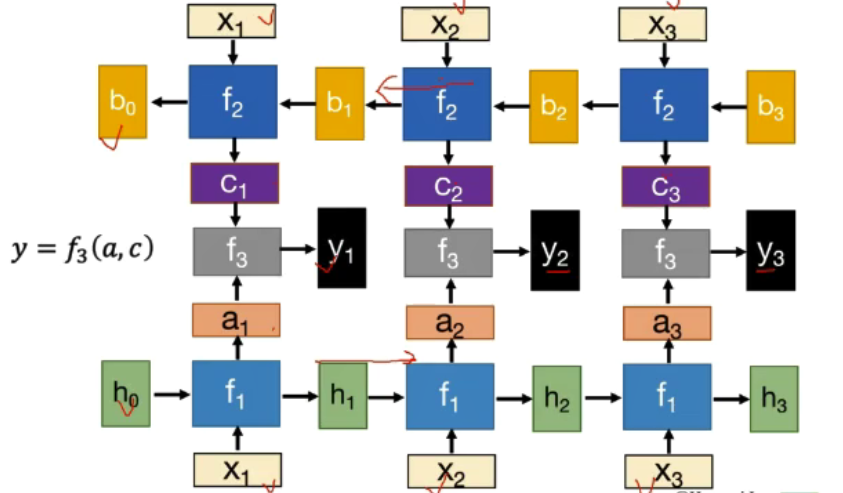
-
小结
-
隐藏层状态h可以被看作是“记忆”,因为它包含了之前时间点上的相关信息;
-
输出y不仅由当前的输入所决定,还会考虑到之前的“记忆”,有两者共同决定;
-
RNN在不同时刻共享同一组参数( U,W,V ),极大的减小了需要训练和预估的参数量;
-
BPTT算法
总损失为每一时刻的损失和;
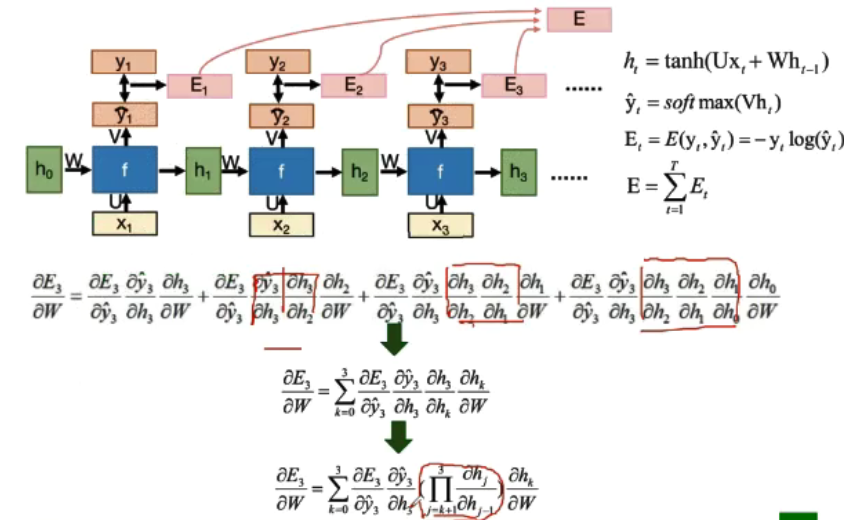
3.循环神经网络的变种
-
传统RNN的问题
-
梯度消失 -> 长时依赖问题 -> 改进模型,LSTM、GRU
-
梯度爆炸 -> 模型训练不稳定 -> 权重衰减,梯度截断
-
LSTM:Long Short-term Memory
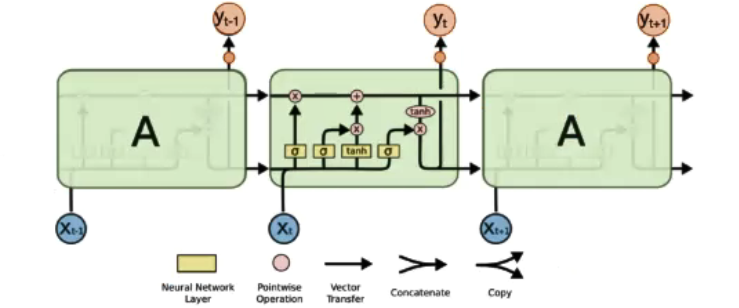
-
LSTM 有三个门(遗忘门,输入门,输出门),来保护和控制细胞状态;
- 遗忘门:决定丢弃信息;
- 输入门:确定需要更新的信息;
- 输出门:输出信息;
-
RNN 与 LSTM 的不同:
- 处理方式不同(RNN:tanh;LSTM:求和);
- RNN 的“记忆”在每个时间点都会被新的输入覆盖,但 LSTM 中“记忆”是与新的输入相加;
- LSTM:如果前边的输入对 Ct 产生了影响,那这个影响会一直存在,除非遗忘门的权重为0;
-
小结:
- LSTM实现了三个门计算:遗忘门,输入门,输出门;
- LSTM的一个初始化技巧就是将输入门的 bias 置为正数(1或5)这样模型刚开始训练时 forget gate 的值接近于 1 ,不会发生梯度消失;
- LSTM 运算复杂 -> 解决:GRU;
-
GRU:Gated Recurrent Unit
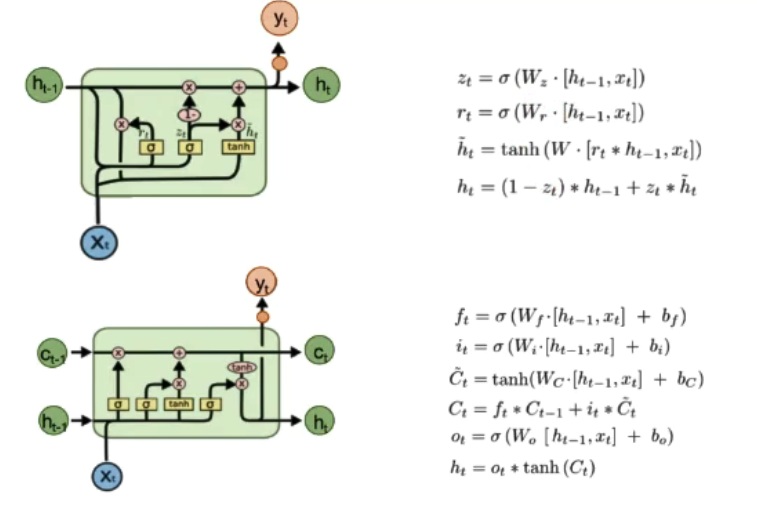
-
差异:
- GRU 只有两个门,分别为重置门和更新门;
- 混合了细胞状态和隐藏状态;
- 重置门:控制忽略前一时刻的状态信息的程度,重置门越小说明忽略的越多;
- 更新门:控制前一时刻的状态信息被带入到当前状态的程度,更新门值越大表示前一时刻的状态信息带入越多;
-
相似:
- 从t-1到t的时刻的记忆的更新都引入加法;
- 可以防止梯度消失;
3.扩展
-
解决RNN梯度消失的其他方法
- Clockwise RNN
-
Attention
- 使得所关注的信息权重大一些