论文阅读 | Selective Kernel Networks
Selective Kernel Convolution
本文提出了一种卷积神经网络系统中的动态选择机制,允许每个神经元基于输入信息的多尺度自适应地调整其感受野大小。为了使神经元能够自适应地调整它们的射频大小,作者提出了一种自动选择操作,在具有不同核大小的多个核之间进行“Slective Kernel”卷积。其中由三个算子组成:Split, Fuse, Select。如下图所示:
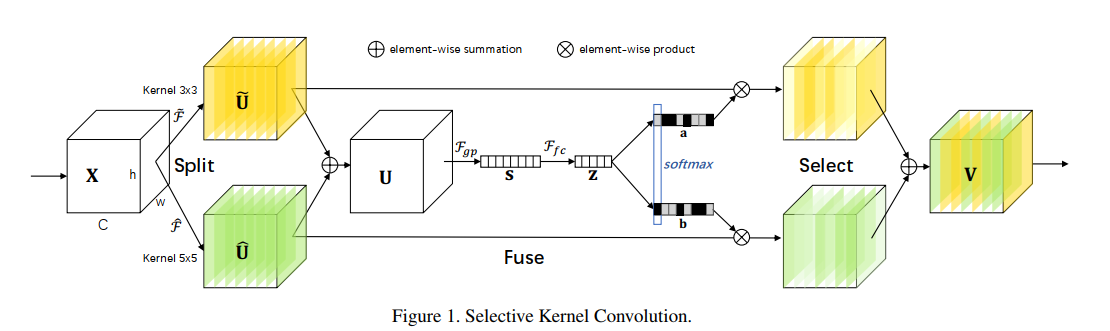
Split
Split 操作产生多条具有不同内核大小的路径,这些路径对应于不同感受野大小的神经元。以两条路径为例,对输入的特征图(X)分别做两个变换 $ ilde F $ 和 $ hat F $ ,得到$ ilde U $ 和 $ hat U $。其中每个变换依次为:grouped/depthwise convolutions, BatchNormalization, ReLU function;不同之处为卷积的卷积核大小不同,一个为 3 x 3 的卷积,另一个为 5 x 5 的卷积。
Fuse
首先通过 element-wise summation 融合来自多个分支的结果,得到(U):
对(U)做全局平均池化,得到通道的统计信息:
将得到的统计信息经过FC、BN、ReLU得到一个压缩的feature:
其中,(W in R^{ d imes C}),(d=max(C/r,L))(r为缩减率),文中实验的设置为(L=32)
Select
计算来自各个路径的权重:
其中,(A, B in R^{C imes d});(a),(b) 分别为 ( ilde U) 和 (hat U) 的 soft attention vector;(A_c in R^{1 imes d}) 是 (A) 的第 (c) 行,(a_c)是 (a) 的第 (c) 个元素;(这里有点绕,(A) 和 (B) 应该分别就是图中右边黄色和绿色部分)
通过各种核上的关注权重求和获得最终的特征图 (V) :
Network Architecture
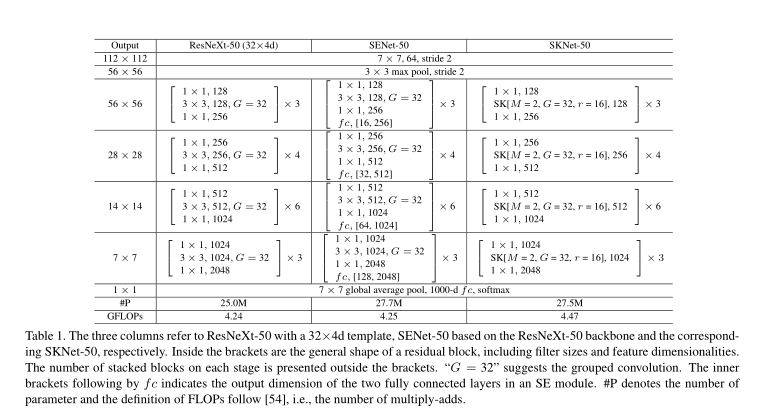
在SK单元中,有三个重要的超参数决定了SK卷积的最终设置:
- The number of paths M
- The group number G
- The reduction ratio r
作者实验后的取值:([M,G,r]=[2,32,16])
作者首先使用SK模块替换到了ResNeXt模型中,因为该模型中用到了group convolution,而且计算量也不大,实验证明,参数量大概提升了10%,计算量提高了5%。
Summary
通过在自然图像中放大目标对象和缩小背景来模拟刺激,以保持图像大小不变。结果发现,当目标物体越来越大时,大多数神经元会越来越多地从更大的核路径中收集信息。这些结果表明,所提出的sknet中的神经元具有自适应的感受野大小。