1 视频学习
1.1 绪论
1.机器学习的三要素:
1)模型(问题建模,确定假设空间)
2)策略(确定目标函数)
3)算法(求解模型参数)
2.专家系统与机器学习:
1)专家系统:基于手工规则建立专家系统,结果容易解释,但系统构建费时费力,依赖于专家主观经验,难以保证一致性和准确性;
2)机器学习:基于数据自动学习,提高信息处理的效率且准确率较高,减少人工繁杂工作,但结果不易解释。
3.深度学习的不能:
1)算法输出不稳定,容易被攻击;
2)模型复杂度高,难以纠错和调试;
3)模型层及复杂程度高,参数不透明;
4)端到端训练方式对数据依赖性强,模型增量性差;
5)专注直观感知类问题,对开放性推理问题无能为;
6)人类知识无法有效引入进行监督,机器偏见难以避免。
1.2 神经网络基础
1.2.1 浅层神经网络
1.M—P神经元
- 多输入信号进行累加
- 权值wi正负模拟兴奋/抑制,大小模拟强度
- 输入和超过阈值,神经元被激活
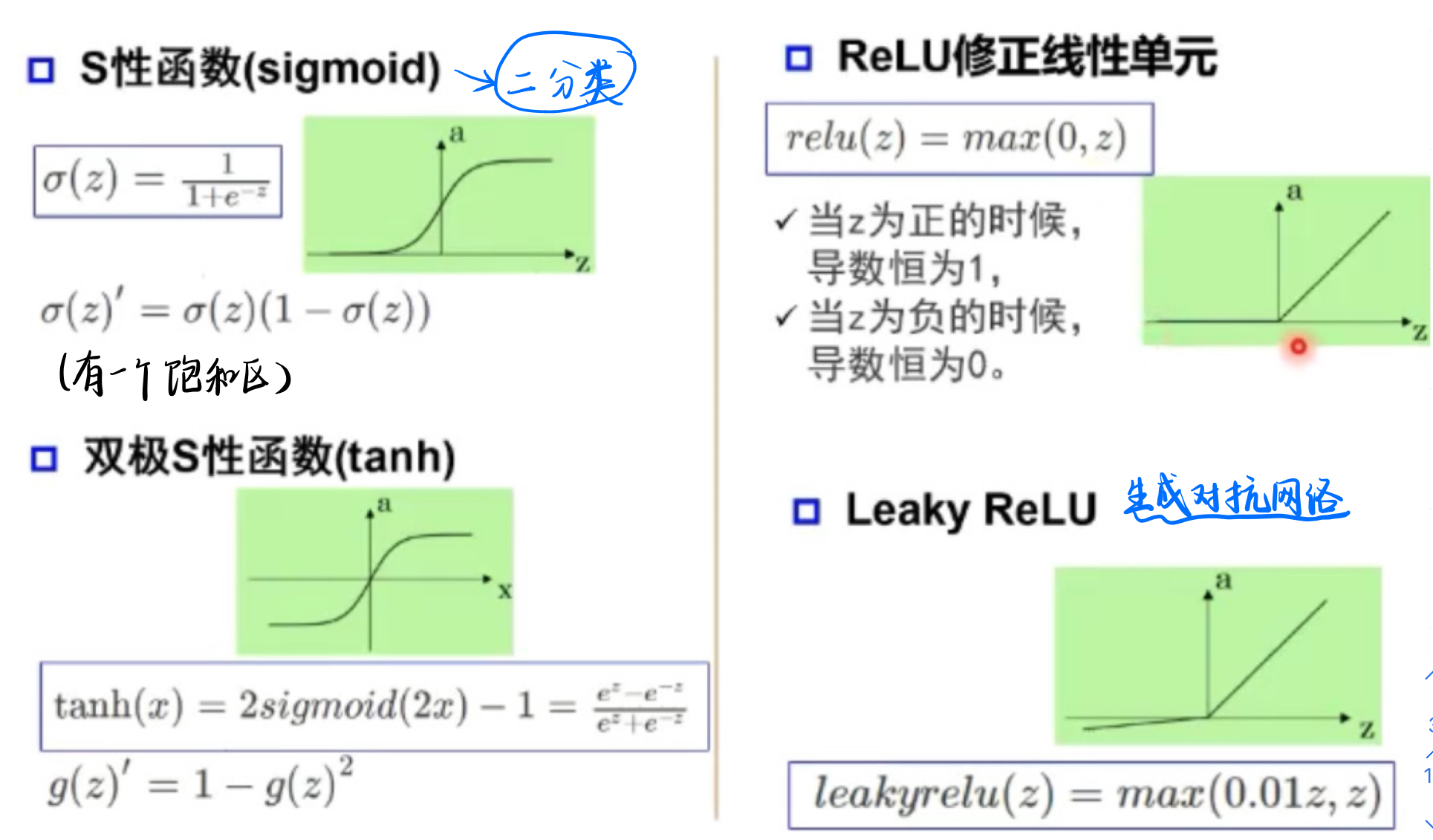
- 激活函数:
2.单层感知器
- M-P神经元的权重预先设置,无法学习
- 单层感知器是首个可以学习的人工神经网络
3.万有逼近定理
如果一个隐层包含足够多的神经元,三层前馈神经网络(输入-隐层-输出)能以任意精度逼近预定的连续函数。
4.双隐层感知器逼近非连续函数
当隐层足够宽时,双隐层感知器可以逼近任意非连续函数:可以解决任何复杂的问题。
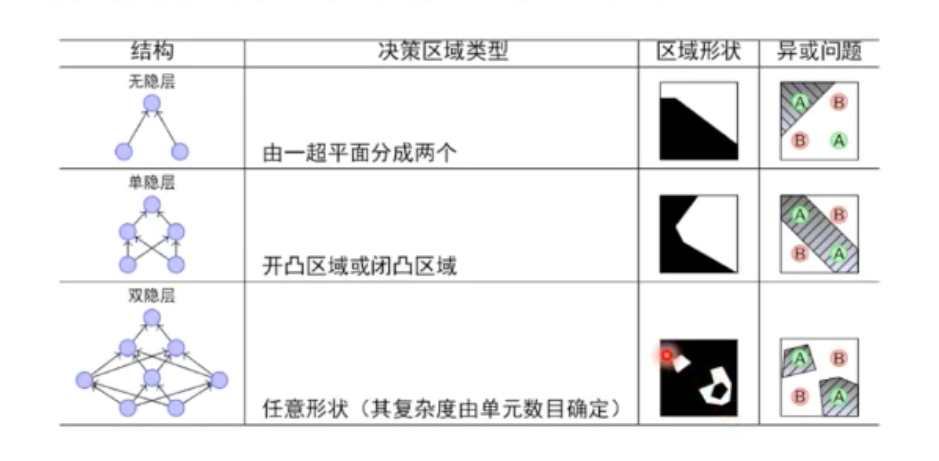
5.神经网络每一层的作用
完成输入到输出的空间变换:
- 升维/降维
- 放大/缩小
- 旋转
- 平移
- 弯曲
1.2.2 神经网络的参数学习:误差反向传播
1.梯度和梯度下降
- 参数沿负梯度方向更新可以使函数值下降
- 依赖初始值的选择
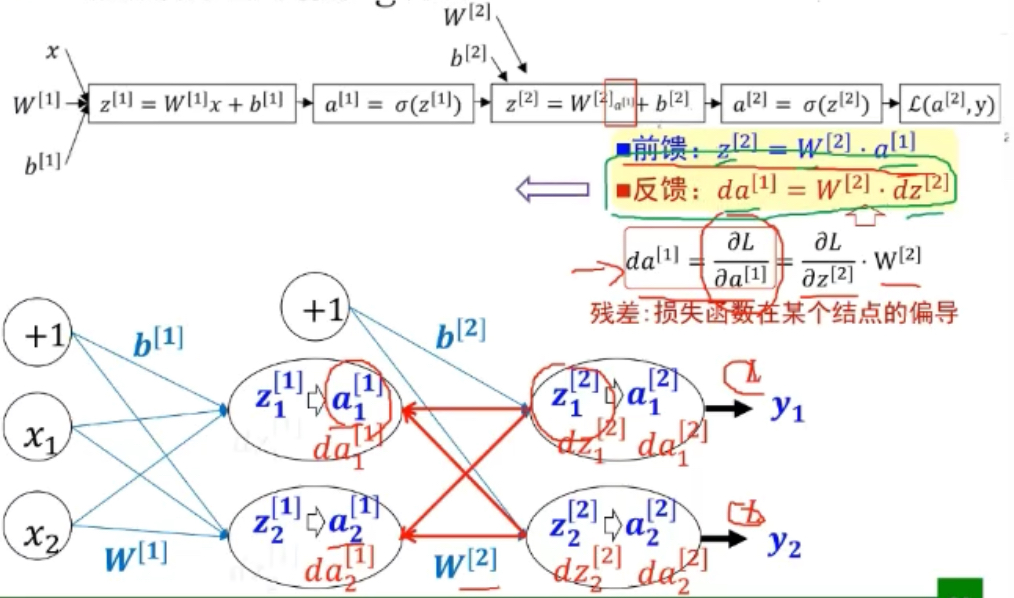
2.三层前馈神经网络的BP算法
前馈:某一层的输出是经过前一层的输入空间变换得到的
反馈:利用每一层的损失向前求偏导
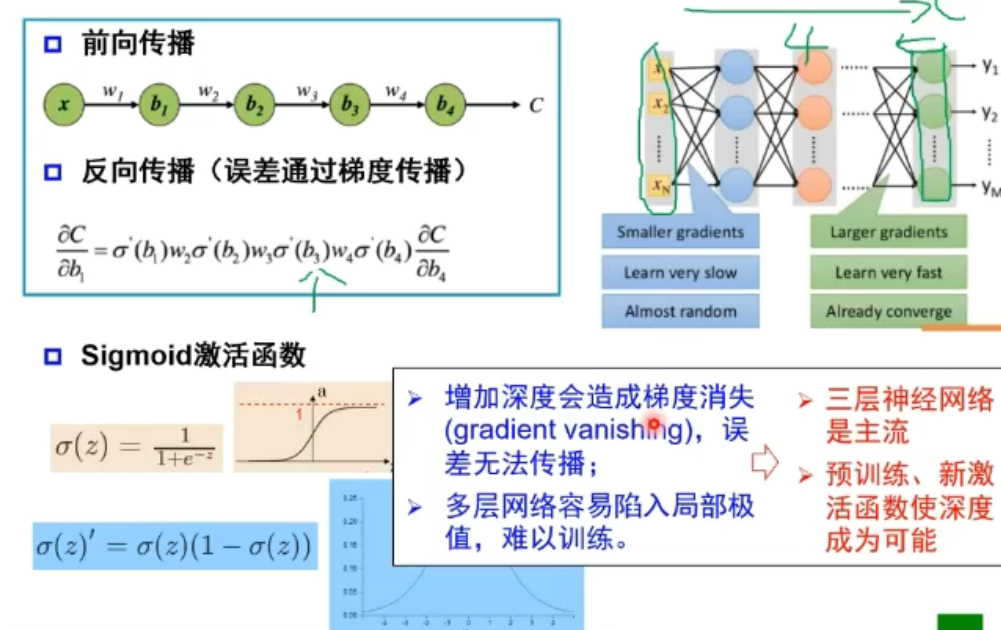
1.2.3 深层神经网络的问题:梯度消失(->"第二次落")
Sigmoid激活函数有一个饱和区,增加梯度使后面几层可以训练的很好,而前面的层不会发生变化。
1.2.4 逐层预训练
- 每次训练一个三层网络得到中间结果,再利用中间结果训练另一个三层网络,不断累加,得到最终结果
- 经过逐层预训练得到的解会相对收敛,训练会更快
- 最终一层加入监督信息来微调
- 由于前面的网络层没有很好的监督信息,所以引入受限玻尔兹曼机和自编码器
1.自编码器
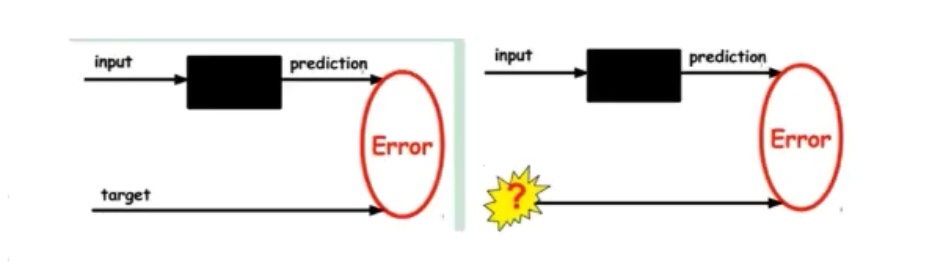
- 输入与输出相同
- 将input输入编码器再输入解码器得到输出
- 没有额外监督信息,自身作为监督信息
2.受限玻尔兹曼机(RBM)
能量分布->联合概率
2 代码练习
2.1 图像处理基本练习
1.下载并显示图像
plt.imshow(colony[:,:,:]) #显示三通道(RGB)
plt.imshow(colony[:,:,0]) #显示B通道
2.读取并改变像素值
data.camera() #返回一张相机的灰度图片(512 x 512)
mask = camera < 80 #图片中像素值大于80的位置对应的mask数组的值为False,其余为True
data.chelsea() #返回一张彩色图片猫;
reddish = cat[:, :, 0] > 160 #图片R(RGB)通道的像素值大于160的位置变为红色
3.转换图像数据类型
img_as_float Convert to 64-bit floating point.
img_as_ubyte Convert to 8-bit uint.
img_as_uint Convert to 16-bit uint.
img_as_int Convert to 16-bit int.
4.显示直方图
img = data.camera()
print(img)
plt.hist(img.ravel(), bins=256, histtype='step', color='black') #ravel()将多维数组降维成一维
5.图像分割
# Use colony image for segmentation
colony = io.imread('yeast_colony_array.jpg')
# Plot histogram
img = skimage.color.rgb2gray(colony) #转灰度图
plt.hist(img.ravel(), bins=256, histtype='step', color='black');
6.Canny算子用于边缘检测
from skimage.feature import canny
from scipy import ndimage as ndi
img_edges = canny(img) #描绘图像边缘
img_filled = ndi.binary_fill_holes(img_edges) #沿着图像边缘把图像填满
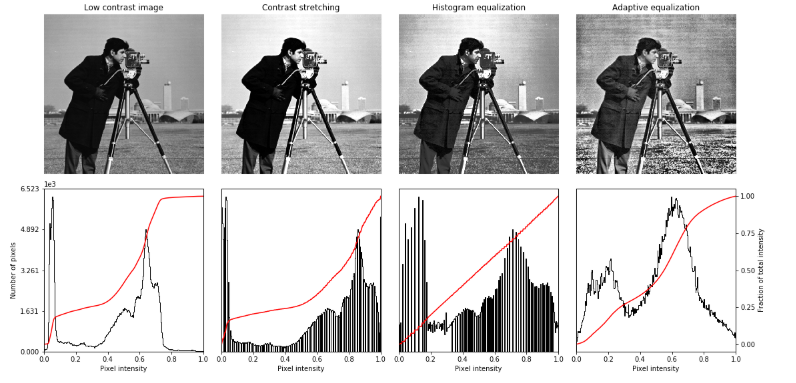
7.改变图像的对比度
#对比度拉伸
from skimage import exposure
p2, p98 = np.percentile(img, (2, 98))
img_rescale = exposure.rescale_intensity(img, in_range=(p2, p98))
plt.imshow(img_rescale, 'gray')
# 直方图均衡化
img_eq = exposure.equalize_hist(img)
plt.imshow(img_eq, 'gray')
# 局部对比度增强
img_adapteq = exposure.equalize_adapthist(img, clip_limit=0.03)
plt.imshow(img_adapteq, 'gray')
直方图均衡化:将一副图像的直方图分布变成近似均匀分布,从而增强图像的对比度。
8.结果展示
2.2 Pythorch基础练习
1.定义数据
- 一般定义数据使用torch.Tensor , tensor的意思是张量,是数字各种形式的总称
- Tensor支持各种各样类型的数据,包括:
torch.float32, torch.float64, torch.float16, torch.uint8, torch.int8, torch.int16, torch.int32, torch.int64
2.定义操作
- 基本运算包括: abs/sqrt/div/exp/fmod/pow ,及一些三角函数 cos/ sin/ asin/ atan2/ cosh,及 ceil/round/floor/trunc 等
- 布尔运算包括: gt/lt/ge/le/eq/ne,topk, sort, max/min
- 线性计算包括: trace, diag, mm/bmm,t,dot/cross,inverse,svd 等
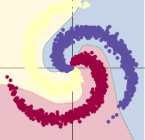
2.3 螺旋分类
import random
import torch
from torch import nn, optim
import math
from IPython import display
from plot_lib import plot_data, plot_model, set_default
# 因为colab是支持GPU的,torch 将在 GPU 上运行
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print('device: ', device)
# 初始化随机数种子。神经网络的参数都是随机初始化的,
# 不同的初始化参数往往会导致不同的结果,当得到比较好的结果时我们通常希望这个结果是可以复现的,
# 因此,在pytorch中,通过设置随机数种子也可以达到这个目的
seed = 12345
random.seed(seed)
torch.manual_seed(seed)
N = 1000 # 每类样本的数量
D = 2 # 每个样本的特征维度
C = 3 # 样本的类别
H = 100 # 神经网络里隐层单元的数量
device: cuda:0
X = torch.zeros(N * C, D).to(device)
Y = torch.zeros(N * C, dtype=torch.long).to(device)
for c in range(C):
index = 0
t = torch.linspace(0, 1, N) # 在[0,1]间均匀的取10000个数,赋给t
# 下面的代码不用理解太多,总之是根据公式计算出三类样本(可以构成螺旋形)
# torch.randn(N) 是得到 N 个均值为0,方差为 1 的一组随机数,注意要和 rand 区分开
inner_var = torch.linspace( (2*math.pi/C)*c, (2*math.pi/C)*(2+c), N) + torch.randn(N) * 0.2
# 每个样本的(x,y)坐标都保存在 X 里
# Y 里存储的是样本的类别,分别为 [0, 1, 2]
for ix in range(N * c, N * (c + 1)):
X[ix] = t[index] * torch.FloatTensor((math.sin(inner_var[index]), math.cos(inner_var[index])))
Y[ix] = c
index += 1
print("Shapes:")
print("X:", X.size())
print("Y:", Y.size())
Shapes:
X: torch.Size([3000, 2])
y: torch.Size([3000])
# visualise the data
plot_data(X, Y)

1.构建线性模型分类
learning_rate = 1e-3
lambda_l2 = 1e-5
# nn 包用来创建线性模型
# 每一个线性模型都包含 weight 和 bias
model = nn.Sequential(
nn.Linear(D, H),
nn.Linear(H, C)
)
model.to(device) # 把模型放到GPU上
# nn 包含多种不同的损失函数,这里使用的是交叉熵(cross entropy loss)损失函数
criterion = torch.nn.CrossEntropyLoss()
# 这里使用 optim 包进行随机梯度下降(stochastic gradient descent)优化
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate, weight_decay=lambda_l2)
# 开始训练
for t in range(1000):
# 把数据输入模型,得到预测结果
y_pred = model(X)
# 计算损失和准确率
loss = criterion(y_pred, Y)
score, predicted = torch.max(y_pred, 1)
acc = (Y == predicted).sum().float() / len(Y)
print('[EPOCH]: %i, [LOSS]: %.6f, [ACCURACY]: %.3f' % (t, loss.item(), acc))
display.clear_output(wait=True)
# 反向传播前把梯度置 0
optimizer.zero_grad()
# 反向传播优化
loss.backward()
# 更新全部参数
optimizer.step()
[EPOCH]: 999, [LOSS]: 0.864019, [ACCURACY]: 0.500
print(y_pred.shape)
print(y_pred[10, :])
print(score[10])
print(predicted[10])
torch.Size([3000, 3])
tensor([0.1070, 0.1738, 0.1800], device='cuda:0', grad_fn=<SliceBackward>)
tensor(0.1800, device='cuda:0', grad_fn=<SelectBackward>)
tensor(2, device='cuda:0')
# Plot trained model
print(model)
plot_model(X, Y, model)
Sequential(
(0): Linear(in_features=2, out_features=100, bias=True)
(1): Linear(in_features=100, out_features=3, bias=True)
)

2.构建两层神经网络分类
learning_rate = 1e-3
lambda_l2 = 1e-5
# 这里可以看到,和上面模型不同的是,在两层之间加入了一个 ReLU 激活函数
model = nn.Sequential(
nn.Linear(D, H),
nn.ReLU(),
nn.Linear(H, C)
)
model.to(device)
# 下面的代码和之前是完全一样的,这里不过多叙述
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate, weight_decay=lambda_l2) # built-in L2
# 训练模型,和之前的代码是完全一样的
for t in range(1000):
y_pred = model(X)
loss = criterion(y_pred, Y)
score, predicted = torch.max(y_pred, 1)
acc = ((Y == predicted).sum().float() / len(Y))
print("[EPOCH]: %i, [LOSS]: %.6f, [ACCURACY]: %.3f" % (t, loss.item(), acc))
display.clear_output(wait=True)
# zero the gradients before running the backward pass.
optimizer.zero_grad()
# Backward pass to compute the gradient
loss.backward()
# Update params
optimizer.step()
# Plot trained model
print(model)
plot_model(X, Y, model)
Sequential(
(0): Linear(in_features=2, out_features=100, bias=True)
(1): ReLU()
(2): Linear(in_features=100, out_features=3, bias=True)
)
2.4 回归分析
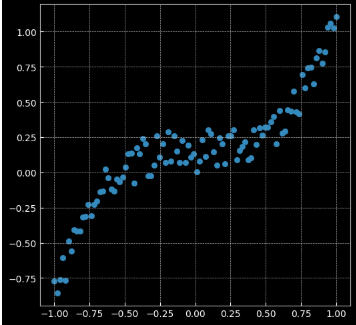
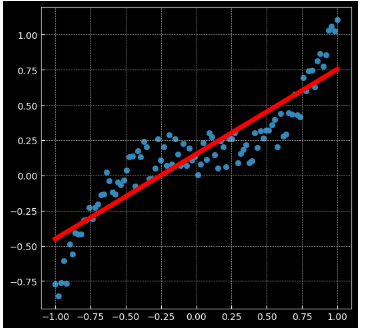
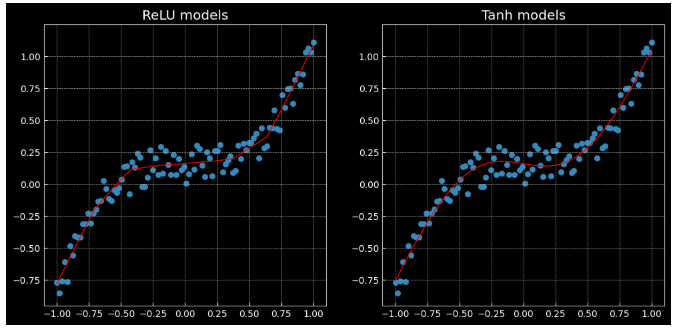
- relu激活函数是分段线性的,得到的结果也是分段线性的;tanh是光滑的,得到的结果也是光滑的