参考原文:菜鸟教程
目录
一、数据库
show dbs -- 查看所有数据库 use DATABASE_NAME -- 如果数据库不存在,则创建数据库,否则切换到指定数据库。 db.dropDatabase() -- 删除当前数据库 db.COLLECTION_NAME.drop() -- 删除集合
二、文档
1. 插入文档
db.col.insert({ title: 'MongoDB Course', tags: ['database', 'NoSQL'] }) document = ({ -- 将数据定义为一个变量 title: 'MongoDB Course', tags: ['database', 'NoSQL'] }); db.col.save(document)
2. 更新文档
-- update db.collection.update( <query>, -- 查询条件,类似sql的where语法 <update>, -- 更新的对象,类似sql的set语法 { upsert: <boolean>, -- 可选,默认是false,表示update的记录不存在时不插入数据,true则为插入, multi: <boolean>, -- 可选,默认是false,只更新找到的第一条记录,true则更新查出来的多条记录。 writeConcern: <document> -- 可选,抛出异常的级别 } ) db.col.update( {title: 'MongoDB Course'}, {$set:{title: 'MongoDB'}} ) db.col.find().pretty() -- save 通过传入的文档来替换已有文档 db.col.save({ title: 'MongoDB', tags: ['database', 'NoSQL'] }) -- update更多例子 db.col.update( { "id" : { $gt : 3 } } , { $set : { "desc" : "OK"} } ); -- 只更新第一条记录 db.col.update( { "id" : { $gt : 3 } } , { $set : { "desc" : "OK"} },false,false ); --只更新第一条记录 db.col.update( { "id" : { $gt : 3 } } , { $set : { "desc" : "OK"} },true, false ); -- 只添加第一条 db.col.update( { "id" : { $gt : 3 } } , { $set : { "desc" : "OK"} },true, true ); --全部添加加进去 db.col.update( { "id" : { $gt : 3 } } , { $set : { "desc" : "OK"} },false,true ); --全部更新
3. 删除文档
db.collection.remove( <query>, -- (可选)删除的文档的条件 { justOne: <boolean>, -- (可选)如果设为 true 或 1,则只删除一个文档。 writeConcern: <document> -- (可选)抛出异常的级别。 } ) db.col.remove({'title':'MongoDB Course '})
4. 查询文档
db.collection.find(query, projection) -- query:(可选)指定查询条件, projection:(可选)指定返回的键 db.col.find().pretty() -- 以格式化的方式来显示所有文档
(1) MongoDB 与 RDBMS Where 语句比较
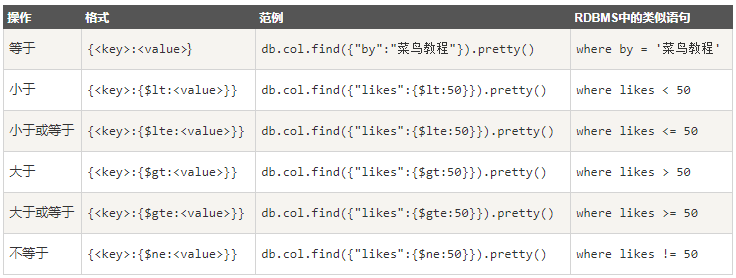
(2) AND和OR 条件
db.col.find({"by":"tom", "title":"MongoDB"}) -- and
db.col.find({$or:[{"by":"tom"},{"title": "MongoDB"}]}) -- or
db.col.find({"likes":{$gt:50}, $or:[{"by":"tom"},{"title":"MongoDB"}]}) --'where likes>50 AND (by ='tom' OR title='MongoDB')'
(3) 条件操作符
-- $gt > $gte >= $lt < $lte <= $eq = $ne != db.col.find({likes : {$lte : 150}}) -- where likes <= 150 db.col.find({likes : {$lt :200, $gt : 100}}) -- where likes>100 AND likes<200
(4) $type操作符
MongoDB 中的类型如下:
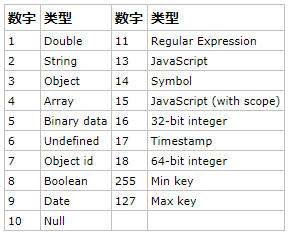
db.col.find({"title" : {$type : 2}}) -- 获取 "col" 集合中 title 为 String 的数据
(5) Limit与Skip方法
limit() -- 读取指定数量的数据, skip() -- 跳过指定数量的数据 db.col.find({},{"title":1,_id:0}).limit(2) -- 查询文档中的两条记录 db.col.find({},{"title":1,_id:0}).skip(10).limit(100) -- 读取从第10条记录后的100条记录
(6) Sort排序方法
指定排序的字段,并使用 1 和 -1 来指定排序的方式,其中 1 为升序排列,而-1是用于降序排列
db.col.find({},{"title":1}).sort({"likes":-1})
db.col.find({"title":"MongoDB"},{"title":1}).sort({"title":1}).skip(2).limit(10)
三、索引
索引是对数据库表中一列或多列的值进行排序的一种结构,索引通常能够极大的提高查询的效率。对于每个插入的数据,都会自动生成一条唯一的 _id 字段,_id 索引是绝大多数集合默认建立的索引。
db.col.getIndexes() -- 察看索引 db.col.ensureIndex({"title":-1}) -- 按title降序创建索引 db.col.ensureIndex({"title": 1, by: 1}, {background: true}) -- 让创建工作在后台执行 db.col.dropIndexes() -- 删除所有索引 db.col.dropIndex("normal_index") -- 删除指定索引
1. 创建索引
ensureIndex() 接收可选参数,可选参数列表如下:
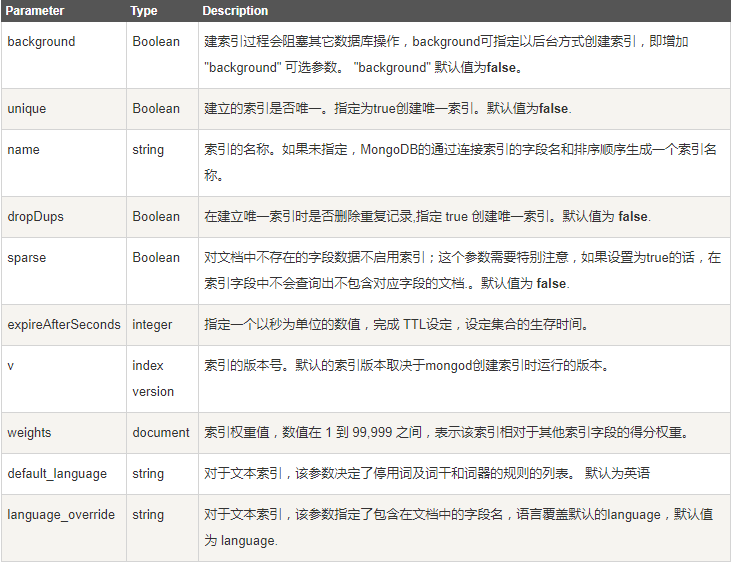
2. 查询分析
MongoDB 查询分析可以确保我们建议的索引是否有效,是查询语句性能分析的重要工具。查询分析常用函数有:explain() 和 hint()。
-- 1. 使用 explain() db.users.ensureIndex({gender:1,user_name:1}) db.users.find({gender:"M"},{user_name:1,_id:0}).explain() { -- MongoDB中索引存储在B树结构中,所以该查询使用了BtreeCursor类型的游标。没有使用索引的游标类型是BasicCursor。 -- 可以通过该索引名称查看当前数据库下的system.indexes集合(系统自动创建),获取索引的详细信息。 "cursor" : "BtreeCursor gender_1_user_name_1", "isMultiKey" : false, "n" : 1, "nscannedObjects" : 0, "nscanned" : 1, -- nscanned/nscannedObjects表明此查询一共扫描了集合中多少个文档,这个数值和返回文档的数量越接近越好。 "nscannedObjectsAllPlans" : 0, "nscannedAllPlans" : 1, "scanAndOrder" : false, "indexOnly" : true, -- 字段为 true ,表示我们使用了索引。 "nYields" : 0, "nChunkSkips" : 0, "millis" : 0, -- 当前查询所需时间,毫秒数。 "indexBounds" : {...} -- 当前查询具体使用的索引。 } -- 2. 使用 hint() 虽然MongoDB查询优化器一般工作的很不错,但是也可以使用 hint 来强制 MongoDB 使用一个指定的索引。 db.users.find({gender:"M"},{user_name:1,_id:0}).hint({gender:1,user_name:1}).explain() -- 指定了使用gender和user_name索引字段来查询
3. 覆盖索引查询
当查询中的所有字段是索引的一部分, MongoDB 只需从RAM中的索引获取数据,比扫描整个文档读取数据要快得多。
- 所有的查询字段是索引的一部分
- 所有的查询返回字段在同一个索引中
-- user集合 { "_id" : 1, "username" : "Amy", "gender" : "F", "score" : 100, "age" : 34 } { "_id" : 2, "username" : "Ram", "gender" : "M", "score" : 90, "age" : 24 } db.user.ensureIndex({gender:1,username:1}) db.user.find({gender:"M"},{username:1,_id:0}) -- 该查询会被索引覆盖,MongoDB不用去数据库文件中查找 db.user.find({gender:"M"},{username:1}) -- 该查询不会被覆盖,由于我们的索引中不包括 _id字段,而此查询没有排除该字段
4. 高级索引
当所有索引字段是一个数组或是一个子文档,不能使用覆盖索引查询
-- users集合 { "name": "Tom Benzamin" "address": {"city": "Los Angeles", "state": "California", "pincode": "123"}, -- 子文档 "tags": ["music", "cricket", "blogs"] -- 数组 } -- 索引数组字段: 在数组中创建索引,需要对数组中的每个字段依次建立索引。因此对数组tags建立索引,会为 music、cricket、blogs三个值建立单独的索引 db.users.ensureIndex({"tags":1}) db.users.find({tags:"cricket"}).explain() -- 执行结果中会显示 "cursor" : "BtreeCursor tags_1" ,表示已经使用了索引 -- 索引子文档字段: 为子文档的三个字段创建索引 db.users.ensureIndex({"address.city":1,"address.state":1,"address.pincode":1}) db.users.find({"address.city":"Los Angeles"}) db.users.find({"address.city":"Los Angeles","address.state":"California","address.pincode":"123"})--查询表达式必须遵循指定的索引的顺序
5. 索引限制
(1) 额外开销: 每个索引占据一定的存储空间,在进行插入,更新和删除操作时也需要对索引进行操作。如果你很少对集合进行读取操作,建议不使用索引。
(2) 内存(RAM)限制: 要确保该索引的大小不超过内存(RAM)的限制。如果索引的大小大于内存的限制,MongoDB会删除一些索引,这将导致性能下降。
(3) 查询限制: 索引不能被以下的查询使用 a. 正则表达式及非操作符,如$nin, $not等 b. 算术运算符,如$mod等 c. $where 子句
(4) 索引键限制:从2.6版本开始,如果现有的索引字段的值超过索引键的限制,MongoDB中不会创建索引。
(5) 最大范围: a. 集合中索引不能超过64个 b.索引名的长度不能超过128个字符 c.一个复合索引最多可以有31个字段
四、聚合
1. count() 和 distinct()
count --统计文档数量 db.collection.count(<query>) 或者 db.collection.find(<query>).count() db.user.count({"username":"amy"}); distinct --对集合中的文档进行去重处理 db.collection.distinct(field,query) db.user.distinct("username",{“age":{$gt:28}}); -- 用于查询年龄age大于28岁的不同用户名
2. aggregate()
1. 聚合的表达式:
-- 对每个分组进行计数: select sex, count(*) personCount from col group by sex db.col.aggregate([{$group: {_id: '$sex', personCount: {$sum:1} }}]) -- 对每个分组求某一列的总和sum/平均值avg/最大值max/最小值min/第一个值first/最后一个值/last -- select sex, sum(score) totalScore from col group by sex db.col.aggregate([{$group: {_id: '$sex', totalScore: {$sum:'$score'} }}]) -- 把每个分组的结果集插入到一个数组中$push/$addToSet(去掉重复的) db.mycol.aggregate([{$group: {_id: 'sex', scores: {$push:′score'} }}])


2. 管道操作符
MongoDB的聚合管道将MongoDB文档在一个管道处理完毕后将结果传递给下一个管道处理。
- $project:修改输入文档的结构。可以用来重命名、增加或删除域,也可以用于创建计算结果以及嵌套文档。
- $match:用于过滤数据,只输出符合条件的文档。$match使用MongoDB的标准查询操作。
- $group:将集合中的文档分组,可用于统计结果。
- $sort:将输入文档排序后输出。
- $limit:用来限制MongoDB聚合管道返回的文档数。
- $skip:在聚合管道中跳过指定数量的文档,并返回余下的文档。
- $unwind:将文档中的某一个数组类型字段拆分成多条,每条包含数组中的一个值
- $geoNear:输出接近某一地理位置的有序文档。
db.user.aggregate( [ {$project: {username: 1, score: 1}}, -- 指定输入字段,_id默认是包含的,可添加_id:0去掉 {$match: {score: {$gt: 70, $lte: 90}}}, {$group: {_id: username, count: {$sum: 1}}}, {$skip : 5} {$sort : {"username": 1}} ])