摘要: 以“数字金融新原力(The New Force of Digital Finance)”为主题,蚂蚁金服ATEC城市峰会于2019年1月4日上海如期举办。财富管理专场上,蚂蚁金服财富事业群资深技术专家康宇麟做了主题为《人工智能在财富领域的应用与探索》的精彩分享。
演讲中,康宇麟分别从如何智能感知用户的需求,生产丰富的内容,动态的服务分发和提供更好的财富管理服务等四个方面为大家介绍了蚂蚁金服在人工智能方面的一些探索与尝试。在这四个方向上,蚂蚁金服希望能够与金融机构深度合作,通过蚂蚁财富将金融机构的优质内容,优质服务和优质市场观点接入到蚂蚁系统,一起为用户提供更好的服务。

以下内容根据演讲嘉宾视频分享以及PPT整理而成。
https://tech.antfin.com/activities/111/review/627
本次的分享主要围绕以下两大方面:
一、金融智能的核心能力
二、蚂蚁金服AI中台
-
感知用户的需求
-
生产丰富的内容
-
动态的服务分发
-
更好的财富管理服务
一、金融智能的核心能力
人工智能技术这几年非常火热,蚂蚁金服也在AI领域做了很多的探索,同时取得了一定的结果,沉淀了一定的能力。下图中可以看到人工智能技术基本已深入到了蚂蚁金服各个业务中。
智能营销项目 。蚂蚁金服经常会做一些营销活动,给用户发放权益红包。以前的做法是发放固定价值的权益红包。但有了智能营销之后,可以根据用户的特征,动态的决定给用户发放红包的价值。智能营销大大的降低了蚂蚁金服营销活动的成本。
保险智能理赔 。使用人工智能技术可以帮助蚂蚁金服决定给客户理赔的金额,这大大提升了运营的效率。
网商风控大脑。人工智能帮助蚂蚁金服根据借贷者的信用状况,动态的决定给借贷者的借贷份额,在控制风险的前提下最大化利润。
智能理财顾问。蚂蚁金服正在开发一套系统,以人机交互对话形式为用户提供一对一的个性化的理财顾问服务。
推荐陪伴服务。根据用户的历史的行为轨迹猜测出用户的喜好。根据用户的喜好动态的推荐适合用户的服务,产品以及内容。
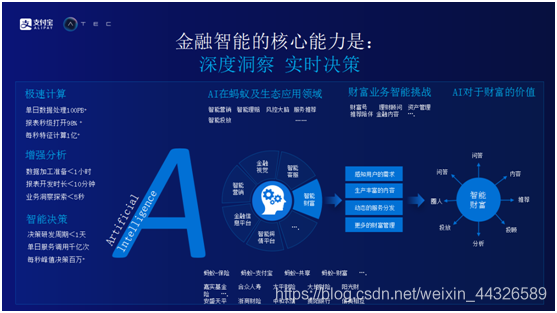
总体上,蚂蚁金服主要在做以下两件事,一是深度的洞察,二是实时决策。深度洞察是指多维度洞察,包括对投资者的洞察,对市场的洞察,对行业的洞察以及对产品的洞察等。了解了投资者和产品之后,在这个基础上做实时决策。深度洞察和实时决策之间具有很强的依赖,通过高速的计算能力和智能决策平台方便蚂蚁金服测试新的规则和策略。
二、蚂蚁金服AI中台
蚂蚁金服在人工智能领域的探索过程当中沉淀了强大的蚂蚁金服中台。聚焦到蚂蚁财富在人工智能方面的探索,主要做了如下四件事情。感知用户的需求,生产丰富的内容,动态的服务分发以及更好的财富管理服务。

1.感知用户的需求
智能问答系统。探索感知用户的需求有两种方式。第一种是隐性方式,通过学习用户的历史行为轨迹,猜测用户的需求。另外一种是显性方式,用户可以通过人机对话方式直接提问,问一些简单的问题或者概念性的问题,比如说,什么是基金?什么是股票?或者更进一步,用户也可以问现在有一万块钱,应该买什么理财产品?或者可不可以推荐一个最适合用户的基金?
下图为蚂蚁金服智能问答系统架构图。当用户提一个问题之后,主要经过五步。
Step1. 预处理。
a. 常用词过滤。用户在提问题的时候,会使用一些常用词,而这些词对后面分析用户的意图没有任何帮助。用户可能会说“早上好”,“麻烦问一下”。系统需要将这些常用词在预处理阶段直接过滤掉。
b. 纠错。纠正用户的拼写错误。比如用户经常会把“基金”写成“机经”。
c. 实体识别。简单来讲,实体识别是对用户输入的句子进行分词,再对每一个词打上相应的标签。用户问“花呗如何开通?”,这句话里面有三个词,主语是花呗,问题是如何是操作,动词是开通。对用户的问题做实体识别会对后面具体识别用户的意图有很大的帮助。
Step2. 模型层。将用户的问题转化成事先定义好的意图。比如说,用户想查询市场行情或者想购买基金,事先定义好这些意图。如何把用户问的问题转化成意图?分别通过规则和算法。规则方式一般使用FST模型和Fuzzy match(模糊匹配)来提高覆盖率。规则模型最大的好处是一旦与用户的意图匹配上了,准确率会非常高,但劣势是覆盖率会很低。如果只是依赖规则模型,很难理解用户所有的问题。在规则模型基础之上,蚂蚁金服开发了基于算法的模型,如XG B, Fast Text,及RNN,和CNN等深度学习模型。算法类模型的好处是覆盖率比规则类模型高。所以通过将规则类和算法类模型结合在一起,便可以得到满意的覆盖率和准确率。
Step3. 要素提取。用户想在平台上购买一支基金,这是一个意图,意图中有三个要素。第一个是想买什么基金,第二个是想什么时候买,第三个是想购买的份额。用户输入了一个问题之后,系统如果判断得出这个问题是一个购买基金的意图,就会尝试抓取抽取以上三个要素,如抽取到了三个要素,便可以直接帮助用户下单。有时用户可能只告诉系统一个或两个要素,其中有一些要素缺失,系统会反问用户,直到用户把所有要素信息提供给系统,系统再帮助用户下单。
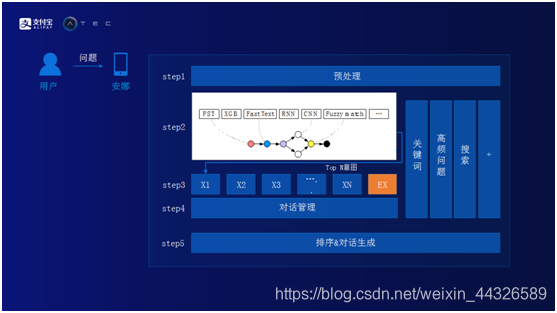
Step4. 对话管理。对话管理主要做了两件事情,意图的切换以及将当前意图中的要素进行存储。假设用户在之前的意图中缺失要素,系统反问用户收取要素信息,用户没有回答这个问题,而问了另外的问题,即转到了另外的意图。这种情况下,系统会把当前意图要素先进行存储,等下一个意图完成之后,用户如果回到前一个意图,系统再把之前的要素读取出来,避免让用户进行重新输入。
Step5. 排序和对话生成。Step3中提到的每个模型都会生成期望答案,在Step5中将它们的答案进行精排再做最后的决定。如下图,用户问基金分析,系统中匹配到基金分析的意图。从“基金分析”这个意图中需要知道“基金名字”这个要素,由于用户没有告诉系统基金名字,所以反问“你想知看看哪个基金呢?”,用户告诉系统是“中证白酒”,系统就可以提取“中证白酒”基金的相关信息并返回给用户。之后用户问了一句“有什么新闻”,实际上这是另外一个意图,但是因为在前一个意图中用户已经明确的告诉系统对“中证白酒”基金感兴趣,所以系统返回的新闻也是关于“中证白酒”的新闻。

2. 生产丰富的内容
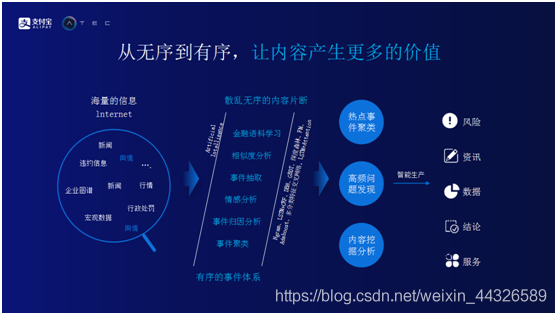
单纯了解用户意图还远远不够,智能问答系统中需要有丰富的内容。对于内容的部分,蚂蚁金服通过社区得到了优质的内容,以及通过爬虫从网上抓取了更多信息,再对信息进行了处理加工。蚂蚁金服本身并不是一家专业的内容生产公司,所以在内容方面更多的依赖于合作伙伴和机构。希望通过蚂蚁财富,将机构的优秀内容接入到蚂蚁系统中,再通过智能问答系统传递给用户。网络上有海量的信息,最大的问题海量信息都是以碎片化的方式很无序的散落在各个角落。这给用户带来了两个问题,首先,他们不知道到从哪里找到这些信息。其次,因为这些信息太过于零散,不知道如何发掘它们之间的关系,帮助用户做更好的投资决策。蚂蚁财富一直在尝试克服海量信息带来的困难,从下图可以看到蚂蚁财富主要做的两件事情。一是将无序的信息变得有序,二是在有序信息基础之上,让内容产生更多价值并服务于用户。首先,散乱无序的内容片断进入系统,系统通过各种各样的尝试将信息变成有序的事件体系。对内容进行聚类和挖掘分析,最后提取出更有价值的信息提供给客户。
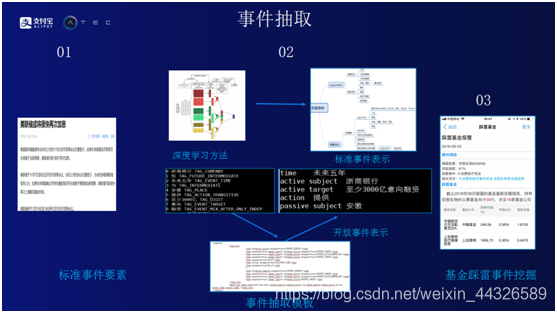
事件抽取。理解一个新闻或者一个事件有两种范式,标准化事件通路和开放式事件通路。标准化事件通路,可以简单的理解为类似的事情以前已经发生过或者见过,而且已经被系统梳理过,对这类事件和事件的要素进行定义。比如“上市公司高管离职”的事件中有三个要素,公司名字,高管姓名以及离职时间。如果事件已经遇到过,可以通过模板定义事件,即使用深度学习的方法,将事件映射到一个标准的模板,从模版中抽取要素。如果能够抽取到事件要素,可以认为这个事件匹配成功,即事件变成了结构化的信息,而且系统知识图谱库对这个事件有一定了解。但有时会发生突发事件,如中美贸易战就从未发生过,标准库中并没有这类事件的定义,可以通过开放式的事件通路来实现这类事件的抓取。开放式通路是将事件中的主谓宾抽取出来,把这些信息存到知识图谱库中。假设“国民生产总值明年会上升”事件以前没有遇到,从这句话中把相关要素提取出来。主语是“国民生产总值”,谓语是“上升”。如果后面发现类似事件出现的频率很高,可以将开放式事件转化成标准式事件。
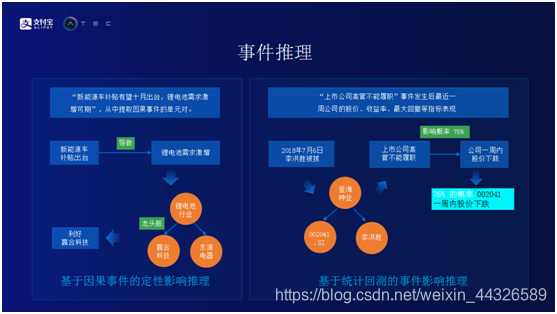
事件推理
基于因果事件的定性影响推理。在事件抽取的基础上做事件推理。一则新闻中提到“新能源车补贴有望十月出台,锂电池需求激增可期”。首先,从这句话中提取因果事件的单元对,了解到新能源车补贴出台会导致锂电池的需求剧增。然后在知识图谱库里查询,发现锂电池需求激增对锂电池行业有利好。再从知识图谱库中找到锂电池行业龙头股,即赢合科技和东源电器。从这件事情上可以推理出“新能源车补贴有望十月出台”是利好赢合科技和东源电器的。
基于统计回测的事件影响推理。有一则新闻说“2018年7月6日,上市公司高管李宏盛被抓”。首先从知识图谱库中寻找“李宏盛”,发现“李宏盛”是“登海种业”的高管,而登海种业的股票代码为002041。通过规则可以知道这是一个上市公司高管不能履职的事件。根据这类事件进行回测,查看这类事件历史发生次数,发生之后股价在未来一个星期内的变化量,进行统计,推理出002041这支股票在未来一周之内会下降。
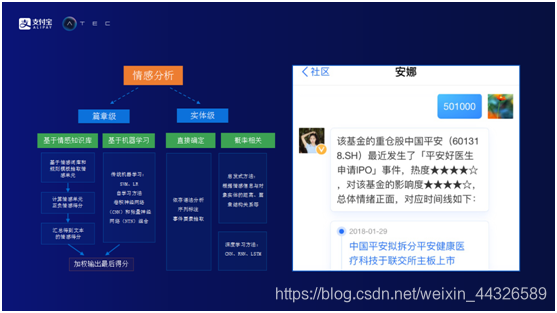
情感分析。情感分析实际上分两类,篇章级和实体级。篇章级指的是给定一段文本,判断这段文本情感上是正面还是负面。实体级情感分析是给定一段文本和句子,同时给定一个实体,判断这段文本和句子对实体的影响是正面还是负面的。
篇章级的情感分析主要有两条通路。基于情感知识库通路和基于机器算法通路。基于情感知识库通路可以理解为有一堆规则模板,从文章中会抽取出若干个情感单元,计算情感单元计情感分,最后汇集起来得到这篇文章的情感分。基于机器学习通路使用传统的机器学习方法和深度学习方法,把文章直接映射到它的情感分,最后把两条通路得到的情感分进行加权,一并输出,作为整个篇章级的情感分。
实体级的情感分析也有两条通路。第一条是直接确定,它依存语法分析,建立语法树,通过事件要素提取,得到文章对实体是正面还是负面的影响。另外一条是通过概率相关方式,如采用启发式方法,根据情感信息与对象实体的距离,篇章结构关系等,得到所对应的情感分。用户查询基金501000,即中国平安,系统了解到中国平安最近发生了“平安好医生申请IPO”事件,这个事件对中国平安是偏利好的事件,所以可以告诉用户“平安好医生申请IPO”事件对该基金的影响度是四星。
3. 服务分发
了解了用户意图和有了足够的内容之后,现在可以反馈用户,即服务分发。服务分发解决三个问题,给用户提供什么样的服务?怎么给用户提供这个服务?在什么时候给用户提供这个服务?这部分工作是基于比较成熟的算法,基本上整体过程是召回,干预,召回和再干预。如下图,在使用蚂蚁财富的APP时,资深投资人都在看系统推荐的内容,这部分内容和服务都是动态的,系统可以根据用户的个人喜好,推荐的最适合的信息和服务。

4. 智能投顾
资产配置
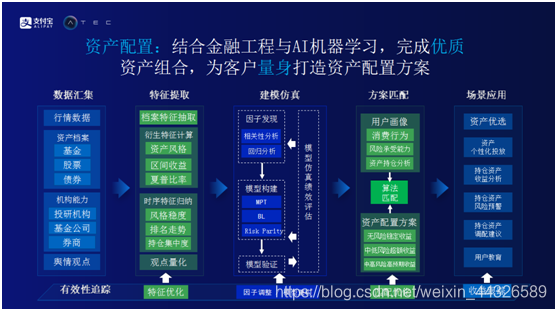
完成了感知用户意图,生成丰富内容和服务分发之后,就和用户建立了一定的信用关系,其中某些用户已经购买了一些金融产品。蚂蚁财富想更进一步结合金融工程与AI机器学习,完成优质资产组合,为客户量身打造资产配置方案。资产配置方案第一步是进行数据汇集。其中有三类数据,一类来自市场上的公开数据,放在资产档案中。另外一类是机构数据。蚂蚁金服作为一个科技公司,一直信奉的观点是让专业人去做专业的事,蚂蚁金服相信这些金融机构在金融领域的专业性和权威性。希望通过蚂蚁财富号,将金融机构的观点引入到蚂蚁系统中,帮助蚂蚁财富更加全面的对市场进行宏观和微观分析。最后一类是舆情观点数据,即在内容生产阶段拿到的关于舆情的信息。通过数据汇总,对数据进行特征提取,包括衍生特征计算,时序特征归纳,和机构的观点量化。假设机构观点不可量化,在这一步首先要将机构的观点进行量化。特征提取以后会得到超高维的特征集,由于超高维的特征集并不能够直接被用来预测市场走势,所以在下一步采取传统的分析方法或者人工智能算法,对超高维的特征集做聚类,相关性分析和回归分析,生成相应的因子,相应因子才是真正可以用来做市场预测。得到相关因子之后,配合常见的模型,如MPT,ML等,生成各种各样的投资组合,它们适用于不同投资风格投资者。最后通过研究用户的行为,采取匹配算法,得到最适合用户的投资组合。
点击阅读更多,查看更多详情