本次使用了tensorflow高级API,在规范化网络编程做出了尝试。
第一步:准备好需要的库
- tensorflow-gpu 1.8.0
- opencv-python 3.3.1
- numpy
- skimage
- tqdm
第二步:准备数据集:
https://www.kaggle.com/c/dogs-vs-cats
我们使用了kaggle的猫狗大战数据集
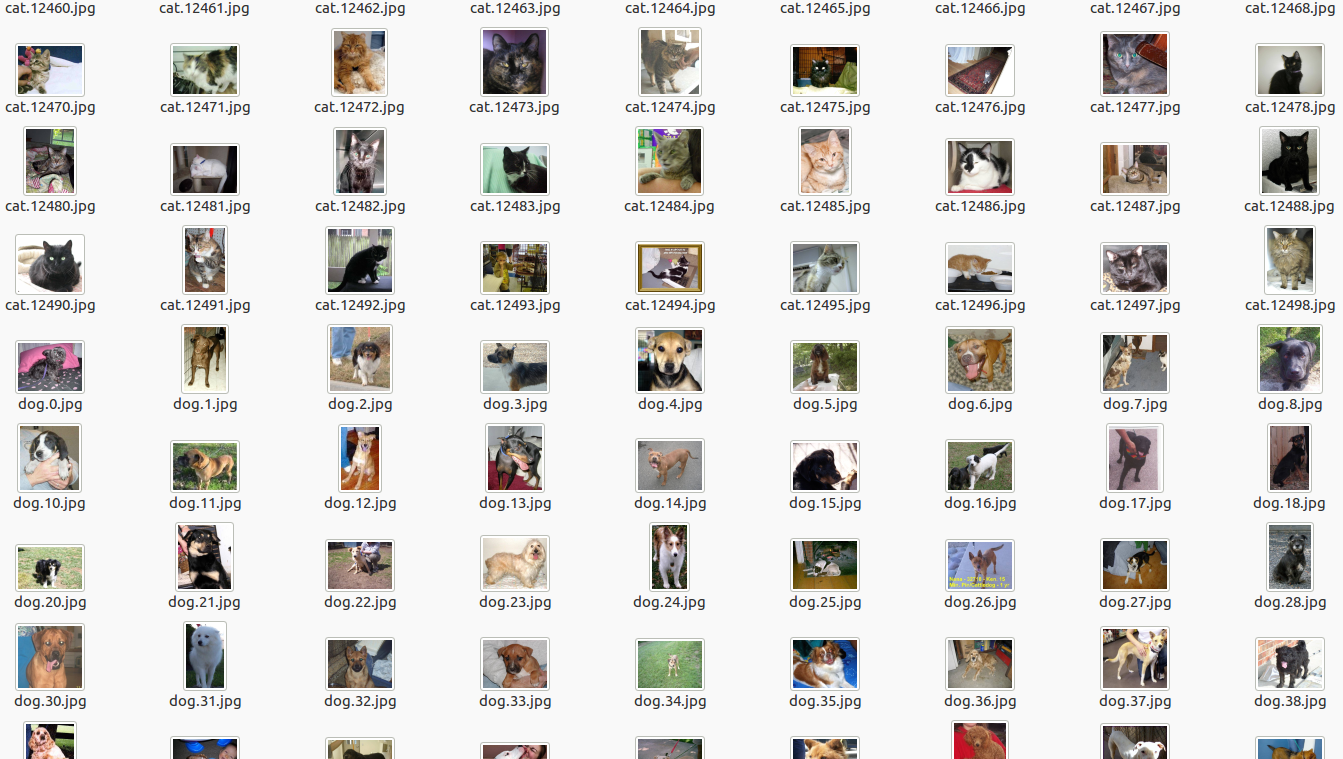
我们可以看到数据集中,文件名使用了 ‘类.编号.文件类型 ’ 的标注
为了通用以及方便起见,我们对该数据集进行分文件夹放置:

下面是分类放置的代码:
import os import shutil output_train_path = '/home/a/Datasets/cat&dog/class/cat' output_test_path = '/home/a/Datasets/cat&dog/class/dog' if not os.path.exists(output_train_path): os.makedirs(output_train_path) if not os.path.exists(output_test_path): os.makedirs(output_test_path) def scanDir_lable_File(dir,flag = True): if not os.path.exists(output_train_path): os.makedirs(output_train_path) if not os.path.exists(output_test_path): os.makedirs(output_test_path) for root, dirs, files in os.walk(dir, True, None, False): # 遍列目录 # 处理该文件夹下所有文件: for f in files: if os.path.isfile(os.path.join(root, f)): a = os.path.splitext(f) # print(a) # lable = a[0].split('.')[1] lable = a[0].split('.')[0] print(lable) if lable == 'cat': img_path = os.path.join(root, f) mycopyfile(img_path, os.path.join(output_train_path, f)) else: img_path = os.path.join(root, f) mycopyfile(img_path, os.path.join(output_test_path, f)) def mycopyfile(srcfile,dstfile): if not os.path.isfile(srcfile): print ("%s not exist!"%(srcfile)) else: fpath,fname=os.path.split(dstfile) #分离文件名和路径 if not os.path.exists(fpath): os.makedirs(fpath) #创建路径 shutil.copyfile(srcfile,dstfile) #复制文件 print ("copy %s -> %s"%( srcfile,dstfile)) root_path = '/home/a/Datasets/cat&dog' train_path = root_path+'/train/' test_path = root_path+'/test/' scanDir_lable_File(train_path)
接着为了有效使用内存资源,我们使用tfrecord来对图片进行存储
from __future__ import absolute_import from __future__ import division from __future__ import print_function import os import random from tqdm import tqdm import numpy as np import tensorflow as tf from skimage import io, transform, color, util flags = tf.flags flags.DEFINE_string(flag_name='directory', default_value='/home/a/Datasets/cat&dog/class', docstring='数据地址') flags.DEFINE_string(flag_name='save_dir', default_value='./tfrecords', docstring='保存地址') flags.DEFINE_integer(flag_name='test_size', default_value=350, docstring='测试集大小') FLAGS = flags.FLAGS MODES = [tf.estimator.ModeKeys.TRAIN, tf.estimator.ModeKeys.EVAL, tf.estimator.ModeKeys.PREDICT] def _float_feature(value): if not isinstance(value, list): value = [value] return tf.train.Feature(float_list=tf.train.FloatList(value=value)) def _int_feature(value): if not isinstance(value, list): value = [value] return tf.train.Feature(int64_list=tf.train.Int64List(value=value)) def _bytes_feature(value): if not isinstance(value, list): value = [value] return tf.train.Feature(bytes_list=tf.train.BytesList(value=value)) def convert_to_tfrecord(mode, anno): """转换为TfRecord""" assert mode in MODES, "模式错误" filename = os.path.join(FLAGS.save_dir, mode + '.tfrecords') with tf.python_io.TFRecordWriter(filename) as writer: for fnm, cls in tqdm(anno): # 读取图片、转换 img = io.imread(fnm) img = color.rgb2gray(img) img = transform.resize(img, [224, 224]) # 获取转换后的信息 if 3 == img.ndim: rows, cols, depth = img.shape else: rows, cols = img.shape depth = 1 # 创建Example对象 example = tf.train.Example( features=tf.train.Features( feature={ 'image/height': _int_feature(rows), 'image/width': _int_feature(cols), 'image/depth': _int_feature(depth), 'image/class/label': _int_feature(cls), 'image/encoded': _bytes_feature(img.astype(np.float32).tobytes()) } ) ) # 序列化并保存 writer.write(example.SerializeToString()) def get_folder_name(folder): """不递归,获取特定文件夹下所有文件夹名""" fs = os.listdir(folder) fs = [x for x in fs if os.path.isdir(os.path.join(folder, x))] return sorted(fs) def get_file_name(folder): """不递归,获取特定文件夹下所有文件名""" fs = os.listdir(folder) fs = map(lambda x: os.path.join(folder, x), fs) fs = [x for x in fs if os.path.isfile(x)] return fs def get_annotations(directory, classes): """获取所有图片路径和标签""" files = [] labels = [] for ith, val in enumerate(classes): fi = get_file_name(os.path.join(directory, val)) files.extend(fi) labels.extend([ith] * len(fi)) assert len(files) == len(labels), "图片和标签数量不等" # 将图片路径和标签拼合在一起 annotation = [x for x in zip(files, labels)] # 随机打乱 random.shuffle(annotation) return annotation def main(_): class_names = get_folder_name(FLAGS.directory) annotation = get_annotations(FLAGS.directory, class_names) convert_to_tfrecord(tf.estimator.ModeKeys.TRAIN, annotation[FLAGS.test_size:]) convert_to_tfrecord(tf.estimator.ModeKeys.EVAL, annotation[:FLAGS.test_size]) if __name__ == '__main__': tf.logging.set_verbosity(tf.logging.INFO) tf.app.run()
再生成tfrecord文件之后
我们选择对于tfrecord文件进行读取
def input_fn(mode, batch_size=1): """输入函数""" def parser(serialized_example): """如何处理数据集中的每一个数据""" # 解析单个example对象 features = tf.parse_single_example( serialized_example, features={ 'image/height': tf.FixedLenFeature([], tf.int64), 'image/width': tf.FixedLenFeature([], tf.int64), 'image/depth': tf.FixedLenFeature([], tf.int64), 'image/encoded': tf.FixedLenFeature([], tf.string), 'image/class/label': tf.FixedLenFeature([], tf.int64), }) # 获取参数 height = tf.cast(features['image/height'], tf.int32) width = tf.cast(features['image/width'], tf.int32) depth = tf.cast(features['image/depth'], tf.int32) # 还原image image = tf.decode_raw(features['image/encoded'], tf.float32) image = tf.reshape(image, [height, width, depth]) image = image - 0.5 # 还原label label = tf.cast(features['image/class/label'], tf.int32) return image, tf.one_hot(label, FLAGS.classes) if mode in MODES: tfrecords_file = os.path.join(FLAGS.data_dir, mode + '.tfrecords') else: raise ValueError("Mode 未知") assert tf.gfile.Exists(tfrecords_file), ('TFRrecords 文件不存在') # 创建数据集 dataset = tf.data.TFRecordDataset([tfrecords_file]) # 创建映射 dataset = dataset.map(parser, num_parallel_calls=1) # 设置batch dataset = dataset.batch(batch_size) # 如果是训练,那么就永久循环下去 if mode == tf.estimator.ModeKeys.TRAIN: dataset = dataset.repeat() # 创建迭代器 iterator = dataset.make_one_shot_iterator() # 获取 feature 和 label images, labels = iterator.get_next() return images, labels
接着构建自己的网络:我们使用tf.layer来进行构建,该方法对于构建网络十分友好。我们创建一个简单的CNN网络
def my_model(inputs, mode): """写一个网络""" net = tf.reshape(inputs, [-1, 224, 224, 1]) net = tf.layers.conv2d(net, 32, [3, 3], padding='same', activation=tf.nn.relu) net = tf.layers.max_pooling2d(net, [2, 2], strides=2) net = tf.layers.conv2d(net, 32, [3, 3], padding='same', activation=tf.nn.relu) net = tf.layers.max_pooling2d(net, [2, 2], strides=2) net = tf.layers.conv2d(net, 64, [3, 3], padding='same', activation=tf.nn.relu) net = tf.layers.conv2d(net, 64, [3, 3], padding='same', activation=tf.nn.relu) net = tf.layers.max_pooling2d(net, [2, 2], strides=2) # print(net) net = tf.reshape(net, [-1, 28 * 28 * 64]) net = tf.layers.dense(net, 1024, activation=tf.nn.relu) net = tf.layers.dropout(net, 0.4, training=(mode == tf.estimator.ModeKeys.TRAIN)) net = tf.layers.dense(net, FLAGS.classes) return net
对该网络进行操作
def my_model_fn(features, labels, mode): """模型函数""" # 可视化输入 tf.summary.image('images', features) # 创建网络 logits = my_model(features, mode) predictions = { 'classes': tf.argmax(input=logits, axis=1), 'probabilities': tf.nn.softmax(logits, name='softmax_tensor') } # 如果是PREDICT,那么只需要predictions就够了 if mode == tf.estimator.ModeKeys.PREDICT: return tf.estimator.EstimatorSpec(mode=mode, predictions=predictions) # 创建Loss loss = tf.losses.softmax_cross_entropy(onehot_labels=labels, logits=logits, scope='loss') tf.summary.scalar('train_loss', loss) # 设置如何训练 if mode == tf.estimator.ModeKeys.TRAIN: optimizer = tf.train.AdamOptimizer(learning_rate=1e-3) train_op = optimizer.minimize(loss, tf.train.get_or_create_global_step()) else: train_op = None # 获取训练精度 accuracy = tf.metrics.accuracy( tf.argmax(labels, axis=1), predictions['classes'], name='accuracy') accuracy_topk = tf.metrics.mean( tf.nn.in_top_k(predictions['probabilities'], tf.argmax(labels, axis=1), 2), name='accuracy_topk') metrics = { 'test_accuracy': accuracy, 'test_accuracy_topk': accuracy_topk } # 可视化训练精度 tf.summary.scalar('train_accuracy', accuracy[1]) tf.summary.scalar('train_accuracy_topk', accuracy_topk[1]) return tf.estimator.EstimatorSpec( mode=mode, predictions=predictions, loss=loss, train_op=train_op, eval_metric_ops=metrics)
训练该网络
def main(_): # 监视器 logging_hook = tf.train.LoggingTensorHook( every_n_iter=100, tensors={ 'accuracy': 'accuracy/value', 'accuracy_topk': 'accuracy_topk/value', 'loss': 'loss/value' }, ) # 创建 Estimator model = tf.estimator.Estimator( model_fn=my_model_fn, model_dir=FLAGS.model_dir) for i in range(20): # 训练 model.train( input_fn=lambda: input_fn(tf.estimator.ModeKeys.TRAIN, FLAGS.batch_size), steps=FLAGS.steps, hooks=[logging_hook]) # 测试并输出结果 print("=" * 10, "Testing", "=" * 10) eval_results = model.evaluate( input_fn=lambda: input_fn(tf.estimator.ModeKeys.EVAL)) print('Evaluation results: {}'.format(eval_results)) print("=" * 30) if __name__ == '__main__': tf.logging.set_verbosity(tf.logging.INFO) tf.app.run()
下面是main的总体代码:
from __future__ import absolute_import from __future__ import division from __future__ import print_function import os import tensorflow as tf flags = tf.app.flags flags.DEFINE_integer(flag_name='batch_size', default_value=16, docstring='Batch 大小') flags.DEFINE_string(flag_name='data_dir', default_value='./tfrecords', docstring='数据存放位置') flags.DEFINE_string(flag_name='model_dir', default_value='./cat&dog_model', docstring='模型存放位置') flags.DEFINE_integer(flag_name='steps', default_value=1000, docstring='训练步数') flags.DEFINE_integer(flag_name='classes', default_value=2, docstring='类别数量') FLAGS = flags.FLAGS MODES = [tf.estimator.ModeKeys.TRAIN, tf.estimator.ModeKeys.EVAL, tf.estimator.ModeKeys.PREDICT] def input_fn(mode, batch_size=1): """输入函数""" def parser(serialized_example): """如何处理数据集中的每一个数据""" # 解析单个example对象 features = tf.parse_single_example( serialized_example, features={ 'image/height': tf.FixedLenFeature([], tf.int64), 'image/width': tf.FixedLenFeature([], tf.int64), 'image/depth': tf.FixedLenFeature([], tf.int64), 'image/encoded': tf.FixedLenFeature([], tf.string), 'image/class/label': tf.FixedLenFeature([], tf.int64), }) # 获取参数 height = tf.cast(features['image/height'], tf.int32) width = tf.cast(features['image/width'], tf.int32) depth = tf.cast(features['image/depth'], tf.int32) # 还原image image = tf.decode_raw(features['image/encoded'], tf.float32) image = tf.reshape(image, [height, width, depth]) image = image - 0.5 # 还原label label = tf.cast(features['image/class/label'], tf.int32) return image, tf.one_hot(label, FLAGS.classes) if mode in MODES: tfrecords_file = os.path.join(FLAGS.data_dir, mode + '.tfrecords') else: raise ValueError("Mode 未知") assert tf.gfile.Exists(tfrecords_file), ('TFRrecords 文件不存在') # 创建数据集 dataset = tf.data.TFRecordDataset([tfrecords_file]) # 创建映射 dataset = dataset.map(parser, num_parallel_calls=1) # 设置batch dataset = dataset.batch(batch_size) # 如果是训练,那么就永久循环下去 if mode == tf.estimator.ModeKeys.TRAIN: dataset = dataset.repeat() # 创建迭代器 iterator = dataset.make_one_shot_iterator() # 获取 feature 和 label images, labels = iterator.get_next() return images, labels def my_model(inputs, mode): """写一个网络""" net = tf.reshape(inputs, [-1, 224, 224, 1]) net = tf.layers.conv2d(net, 32, [3, 3], padding='same', activation=tf.nn.relu) net = tf.layers.max_pooling2d(net, [2, 2], strides=2) net = tf.layers.conv2d(net, 32, [3, 3], padding='same', activation=tf.nn.relu) net = tf.layers.max_pooling2d(net, [2, 2], strides=2) net = tf.layers.conv2d(net, 64, [3, 3], padding='same', activation=tf.nn.relu) net = tf.layers.conv2d(net, 64, [3, 3], padding='same', activation=tf.nn.relu) net = tf.layers.max_pooling2d(net, [2, 2], strides=2) # print(net) net = tf.reshape(net, [-1, 28 * 28 * 64]) net = tf.layers.dense(net, 1024, activation=tf.nn.relu) net = tf.layers.dropout(net, 0.4, training=(mode == tf.estimator.ModeKeys.TRAIN)) net = tf.layers.dense(net, FLAGS.classes) return net def my_model_fn(features, labels, mode): """模型函数""" # 可视化输入 tf.summary.image('images', features) # 创建网络 logits = my_model(features, mode) predictions = { 'classes': tf.argmax(input=logits, axis=1), 'probabilities': tf.nn.softmax(logits, name='softmax_tensor') } # 如果是PREDICT,那么只需要predictions就够了 if mode == tf.estimator.ModeKeys.PREDICT: return tf.estimator.EstimatorSpec(mode=mode, predictions=predictions) # 创建Loss loss = tf.losses.softmax_cross_entropy(onehot_labels=labels, logits=logits, scope='loss') tf.summary.scalar('train_loss', loss) # 设置如何训练 if mode == tf.estimator.ModeKeys.TRAIN: optimizer = tf.train.AdamOptimizer(learning_rate=1e-3) train_op = optimizer.minimize(loss, tf.train.get_or_create_global_step()) else: train_op = None # 获取训练精度 accuracy = tf.metrics.accuracy( tf.argmax(labels, axis=1), predictions['classes'], name='accuracy') accuracy_topk = tf.metrics.mean( tf.nn.in_top_k(predictions['probabilities'], tf.argmax(labels, axis=1), 2), name='accuracy_topk') metrics = { 'test_accuracy': accuracy, 'test_accuracy_topk': accuracy_topk } # 可视化训练精度 tf.summary.scalar('train_accuracy', accuracy[1]) tf.summary.scalar('train_accuracy_topk', accuracy_topk[1]) return tf.estimator.EstimatorSpec( mode=mode, predictions=predictions, loss=loss, train_op=train_op, eval_metric_ops=metrics) def main(_): # 监视器 logging_hook = tf.train.LoggingTensorHook( every_n_iter=100, tensors={ 'accuracy': 'accuracy/value', 'accuracy_topk': 'accuracy_topk/value', 'loss': 'loss/value' }, ) # 创建 Estimator model = tf.estimator.Estimator( model_fn=my_model_fn, model_dir=FLAGS.model_dir) for i in range(20): # 训练 model.train( input_fn=lambda: input_fn(tf.estimator.ModeKeys.TRAIN, FLAGS.batch_size), steps=FLAGS.steps, hooks=[logging_hook]) # 测试并输出结果 print("=" * 10, "Testing", "=" * 10) eval_results = model.evaluate( input_fn=lambda: input_fn(tf.estimator.ModeKeys.EVAL)) print('Evaluation results: {}'.format(eval_results)) print("=" * 30) if __name__ == '__main__': tf.logging.set_verbosity(tf.logging.INFO) tf.app.run()
在训练完成后,我们对结果进行预测:
"""Run inference a DeepLab v3 model using tf.estimator API.""" from __future__ import absolute_import from __future__ import division from __future__ import print_function import argparse import os import sys import tensorflow as tf import train from skimage import io, transform, color, util mode = tf.estimator.ModeKeys.PREDICT _NUM_CLASSES = 2 image_size = [224,224] image_files = '/home/a/Datasets/cat&dog/test/44.jpg' model_dir = './cat&dog_model/' def main(unused_argv): # Using the Winograd non-fused algorithms provides a small performance boost. os.environ['TF_ENABLE_WINOGRAD_NONFUSED'] = '1' # model = tf.estimator.Estimator( model_fn=train.my_model_fn, model_dir=model_dir) def predict_input_fn(image_path): img = io.imread(image_path) img = color.rgb2gray(img) img = transform.resize(img, [224, 224]) image = img - 0.5 # preprocess image: scale pixel values from 0-255 to 0-1 images = tf.image.convert_image_dtype(image, dtype=tf.float32) dataset = tf.data.Dataset.from_tensors((images,)) return dataset.batch(1).make_one_shot_iterator().get_next() def predict(image_path): result = model.predict(input_fn=lambda: predict_input_fn(image_path=image_path)) for r in result: print(r) if r['classes'] ==1: print('dog',r['probabilities'][1]) else: print('cat',r['probabilities'][0]) predict(image_files) if __name__ == '__main__': tf.logging.set_verbosity(tf.logging.INFO) tf.app.run(main=main)
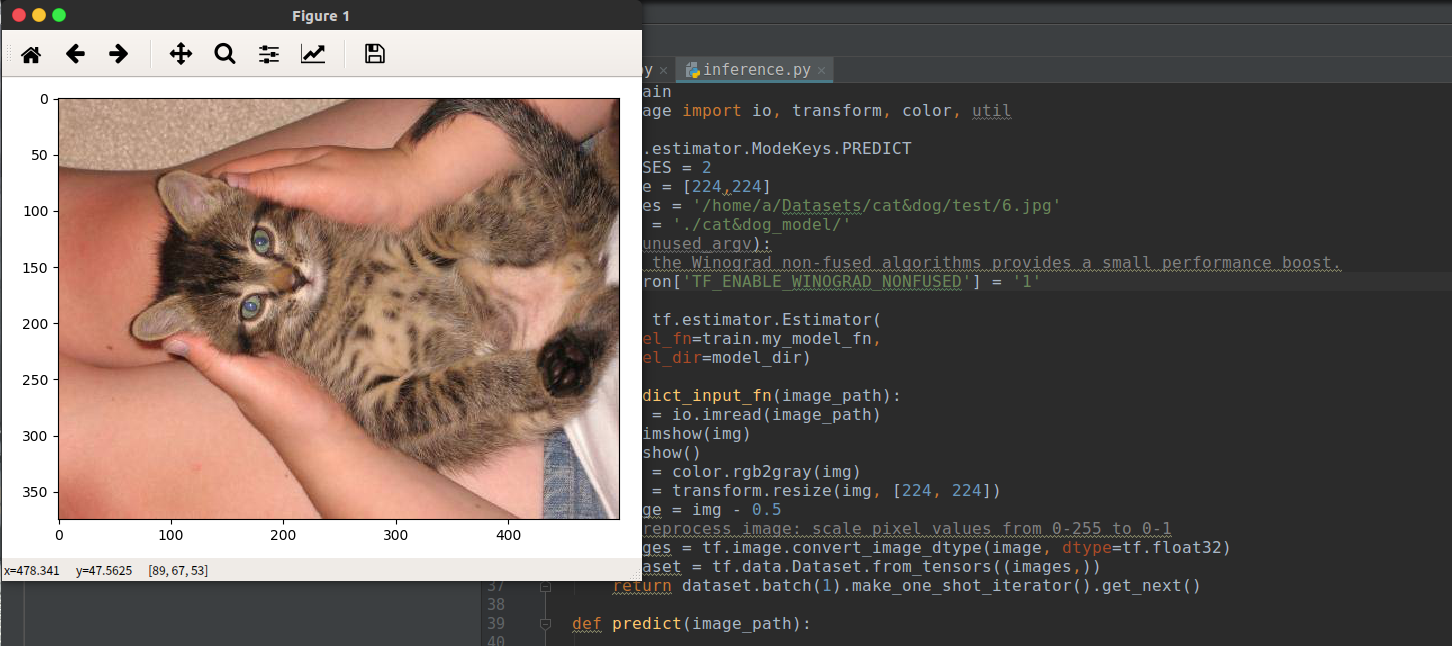
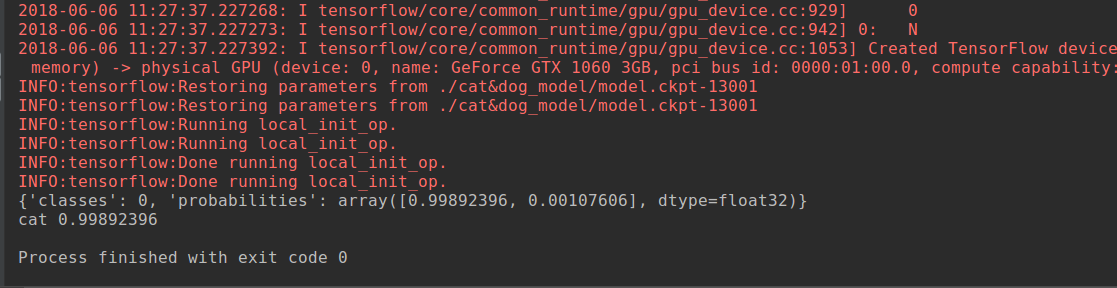
因为网络非常简单,所以测试精度大概在75%左右
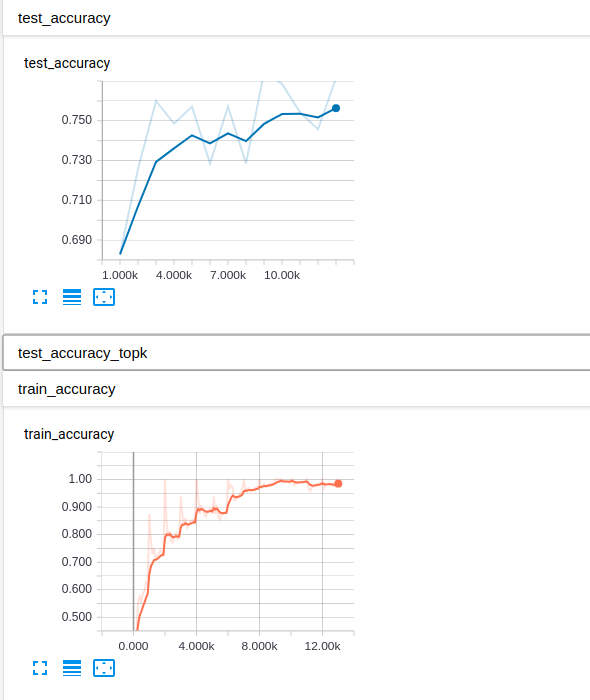
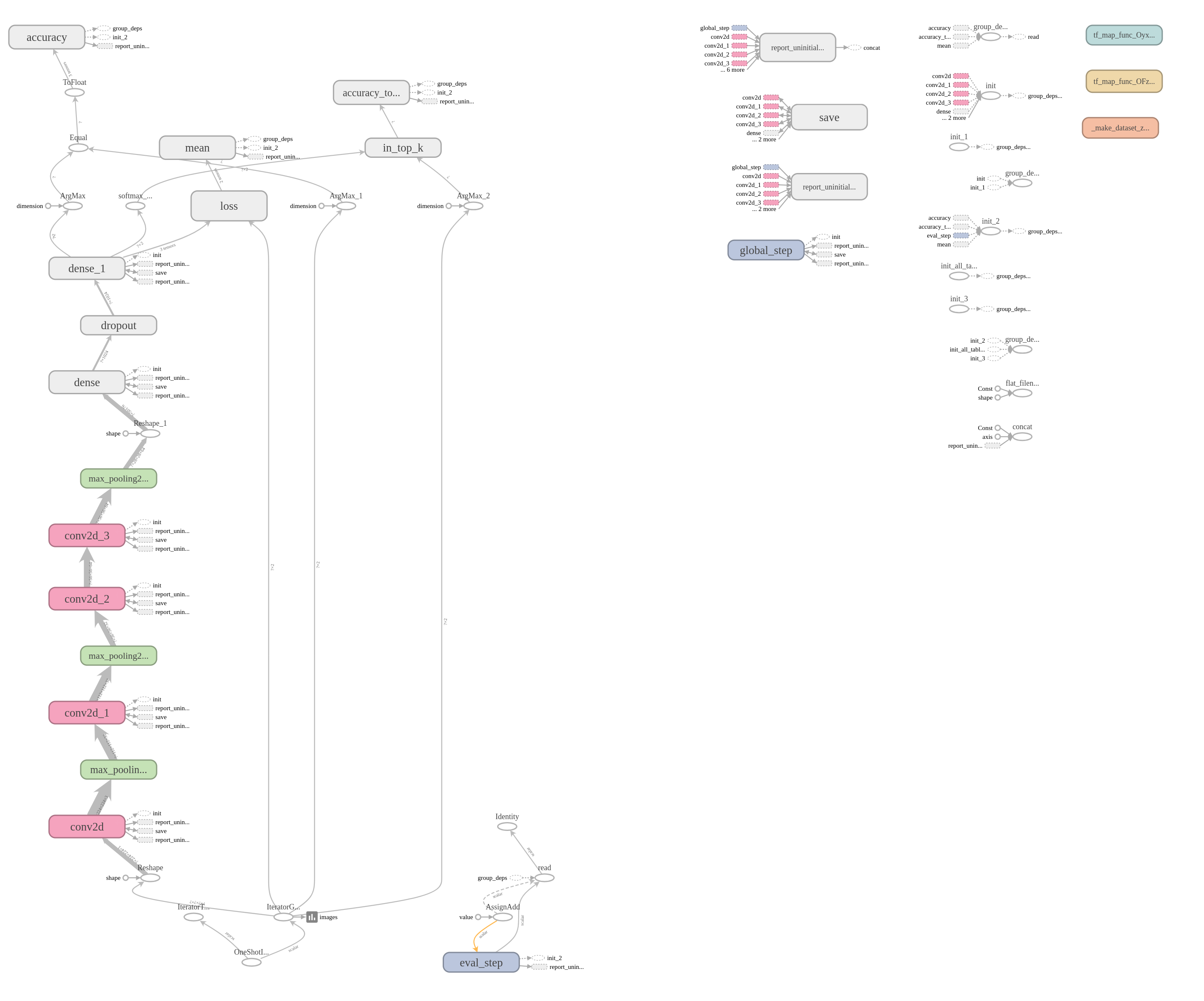
这个是最终网络图: