那么这篇文章就大概说下,如何在上一个版本中进行升级改造,使之成为一个多任务版本的爬虫。加快我们爬取的速度。
话不多说,先看图:
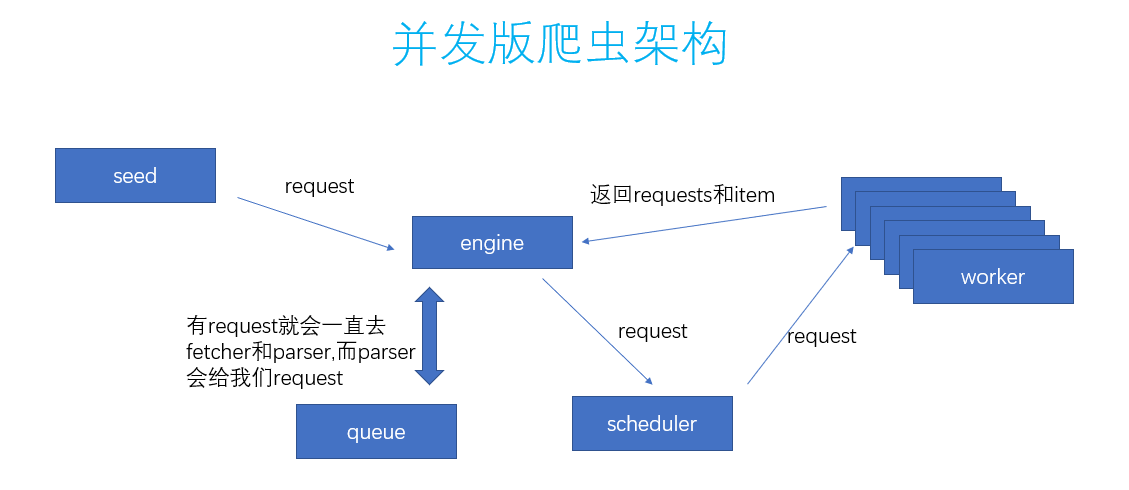
其实呢,实现方法就是加了一个scheduler的模块,所有的request都由scheduler去交给worker。
另外呢,这里的worker,也就是上文提到过的fetcher和parser的一个过程。
worker的数量由我们自己在调用engine的时候传入。
每一个worker都是一个groutine。这样可以加快抓取速度,尤其是fetcher那块的。代码如下:
func createWorker(in chan Request, out chan ParseResult) { go func() { for { request := <-in res, err := Worker(request) if err != nil { continue } out <- res } }() }
这里的关键呢,就在于scheduler如何分配。
第一种方案是来一个request就给到workChan。
func (s *SimpleScheduler) Submit(r simple_con_engine.Request) { s.workChan <- r }
但是,这种方案是不行的。
因为worker的速度太快,而这个给到workChan的速度太慢,会导致卡死。
那么,解决办法可以是每来一个request就都开一个groutine,就可以解决这个事情了。代码也就是这样了:
func (s *SimpleScheduler) Submit(r simple_con_engine.Request) { go func() { s.workChan <- r }() }
scheduler做的事情也就是这样了:
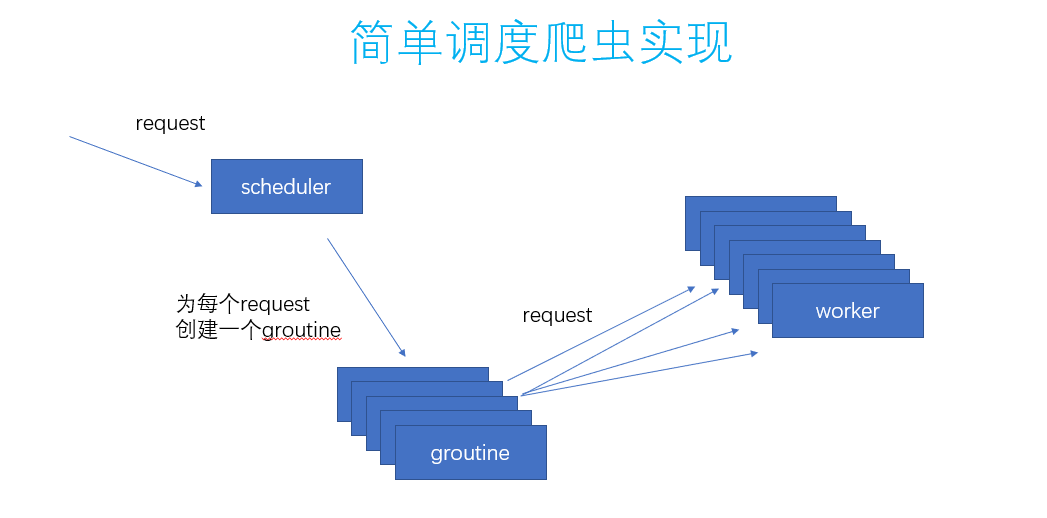
这个就可以并发的去执行爬虫的任务了,通过这个scheduler的调度。
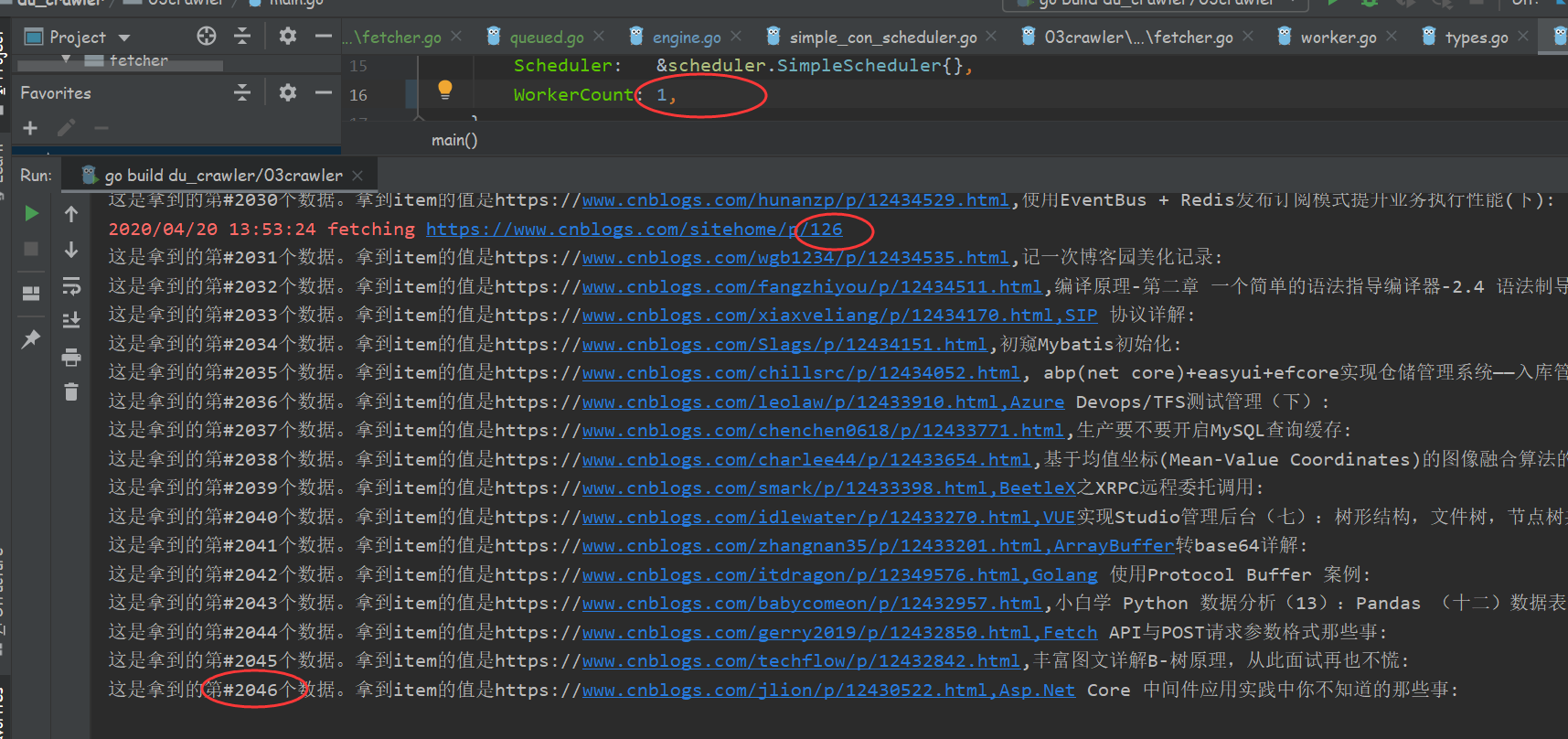
经测当workerCount为1时,其实也就相当于是单任务版爬虫为30秒爬取了2046条数据。
当workerCount为10时,这个使用了简单调度器的爬虫为30秒爬取了25505条数据,实际效率不止增加了10倍。

这个使用scheduler去实现简单调度器的并发版爬虫的源码可有:
有。
https://github.com/anmutu/du_crawler/tree/master/03crawler
那么,这个多任务版本的爬虫有什么缺点吗:
有。
当engine给到scheduler的每一个request的时候就会创建一个groutine,这个避免dead lock,但是就会创建无数个groutine,我们的控制力度就小了好多。