过拟合与欠拟合(Overfitting and underfitting)
官网示例:https://www.tensorflow.org/tutorials/keras/overfit_and_underfit
主要步骤:
- 演示过拟合
- - 创建基准模型
- - 创建一个更小的模型
- - 创建一个更大的模型
- - 绘制训练损失和验证损失函数
- 策略
- - 添加权重正则化
- - 添加丢弃层
一些知识点
过拟合
在训练集上可以实现很高的准确率,但无法很好地泛化到测试数据(或之前未见过的数据)。
可能导致欠拟合的原因:训练时间过长等。
防止过拟合的最常见方法:
- 推荐:获取并使用更多训练数据
- 最简单:适当缩小模型(降低网络容量)
- 添加权重正则化(限制网络的复杂性,也就是限制可存储信息的数量和类型)
- 添加丢弃层
此外还有两个重要的方法:数据增强和批次归一化。
欠拟合
与过拟合相对的就是欠拟合,测试数据仍存在改进空间,意味着模型未学习到训练数据中的相关模式。
可能导致欠拟合的原因:模型不够强大、过于正则化、或者根本没有训练足够长的时间等。
模型大小
防止过拟合,最简单的方法是缩小模型,即减少模型中可学习参数的数量(由层数和每层的单元数决定)。
在深度学习中,模型中可学习参数的数量通常称为模型的“容量”。
模型“记忆容量”越大,越能轻松学习训练样本与其目标之间的字典式完美映射(无任何泛化能力的映射),但无法对未见过的数据做出预测。
也就是说,网络容量越大,便能够越快对训练数据进行建模(产生较低的训练损失),但越容易过拟合(导致训练损失与验证损失之间的差异很大)。
如果模型太小(记忆资源有限),便无法轻松学习映射,难以与训练数据拟合。
需要尝试不断地尝试来确定合适的模型大小或架构(由层数或每层的合适大小决定)。
最好先使用相对较少的层和参数,然后开始增加层的大小或添加新的层,直到看到返回的验证损失不断减小为止。
奥卡姆剃刀定律
如果对于同一现象有两种解释,最可能正确的解释是“最简单”的解释,即做出最少量假设的解释。
也适用于神经网络学习的模型:给定一些训练数据和一个网络架构,有多组权重值(多个模型)可以解释数据,而简单模型比复杂模型更不容易过拟合。
简单模型”是一种参数值分布的熵较低的模型(或者具有较少参数的模型)。
权重正则化
限制网络的复杂性,具体方法是强制要求其权重仅采用较小的值,使权重值的分布更“规则”。
通过向网络的损失函数添加与权重较大相关的代价来实现。
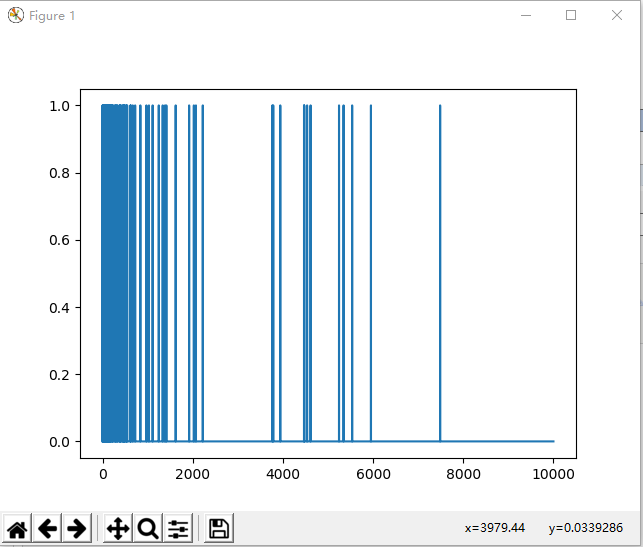
- L1正则化,其中所添加的代价与权重系数的绝对值(即所谓的权重“L1 范数”)成正比。
- L2正则化,其中所添加的代价与权重系数值的平方(即所谓的权重“L2 范数”)成正比,也称为权重衰减。
丢弃层
添加丢弃层可明显改善基准模型,是最有效且最常用的神经网络正则化技术之一。
丢弃(应用于某个层)是指在训练期间随机“丢弃”(即设置为 0)该层的多个输出特征。
“丢弃率”指变为 0 的特征所占的比例,通常设置在 0.2 和 0.5 之间。
因为“测试时的活跃单元数大于训练时的活跃单元数”,因此测试时网络不会丢弃任何单元,而是将层的输出值按等同于丢弃率的比例进行缩减。
示例
脚本内容
GitHub:https://github.com/anliven/Hello-AI/blob/master/Google-Learn-and-use-ML/4_overfit_and_underfit.py
1 # coding=utf-8 2 import tensorflow as tf 3 from tensorflow import keras 4 import numpy as np 5 import matplotlib.pyplot as plt 6 import pathlib 7 import os 8 9 os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' 10 print("# TensorFlow version: {} - tf.keras version: {}".format(tf.VERSION, tf.keras.__version__)) # 查看版本 11 ds_path = str(pathlib.Path.cwd()) + "\datasets\imdb\" # 数据集路径 12 13 # ### 查看numpy格式数据 14 np_data = np.load(ds_path + "imdb.npz") 15 print("# np_data keys: ", list(np_data.keys())) # 查看所有的键 16 # print("# np_data values: ", list(np_data.values())) # 查看所有的值 17 # print("# np_data items: ", list(np_data.items())) # 查看所有的item 18 19 # ### 加载IMDB数据集 20 NUM_WORDS = 10000 21 22 imdb = keras.datasets.imdb 23 (train_data, train_labels), (test_data, test_labels) = imdb.load_data( 24 path=ds_path + "imdb.npz", 25 num_words=NUM_WORDS # 保留训练数据中出现频次在前10000位的字词 26 ) 27 28 29 def multi_hot_sequences(sequences, dimension): 30 results = np.zeros((len(sequences), dimension)) 31 for i, word_indices in enumerate(sequences): 32 results[i, word_indices] = 1.0 33 return results 34 35 36 train_data = multi_hot_sequences(train_data, dimension=NUM_WORDS) 37 test_data = multi_hot_sequences(test_data, dimension=NUM_WORDS) 38 39 plt.plot(train_data[0]) # 查看其中的一个多热向量(字词索引按频率排序,因此索引0附近应该有更多的1值) 40 plt.savefig("./outputs/sample-4-figure-1.png", dpi=200, format='png') 41 plt.show() 42 plt.close() 43 44 # ### 演示过拟合 45 # 创建基准模型 46 baseline_model = keras.Sequential([ 47 keras.layers.Dense(16, activation=tf.nn.relu, input_shape=(NUM_WORDS,)), 48 keras.layers.Dense(16, activation=tf.nn.relu), 49 keras.layers.Dense(1, activation=tf.nn.sigmoid) 50 ]) # 仅使用Dense层创建一个简单的基准模型 51 baseline_model.compile(optimizer='adam', 52 loss='binary_crossentropy', 53 metrics=['accuracy', 'binary_crossentropy']) # 编译模型 54 baseline_model.summary() # 打印出关于模型的简单描述 55 baseline_history = baseline_model.fit(train_data, 56 train_labels, 57 epochs=20, 58 batch_size=512, 59 validation_data=(test_data, test_labels), 60 verbose=2) # 训练模型 61 62 # 创建一个更小的模型(隐藏单元更少) 63 smaller_model = keras.Sequential([ 64 keras.layers.Dense(4, activation=tf.nn.relu, input_shape=(NUM_WORDS,)), 65 keras.layers.Dense(4, activation=tf.nn.relu), 66 keras.layers.Dense(1, activation=tf.nn.sigmoid) 67 ]) 68 smaller_model.compile(optimizer='adam', 69 loss='binary_crossentropy', 70 metrics=['accuracy', 'binary_crossentropy']) 71 smaller_model.summary() 72 smaller_history = smaller_model.fit(train_data, 73 train_labels, 74 epochs=20, 75 batch_size=512, 76 validation_data=(test_data, test_labels), 77 verbose=2) # 使用相同的数据训练 78 79 # 创建一个更大的模型(远超出解决问题所需的容量) 80 bigger_model = keras.models.Sequential([ 81 keras.layers.Dense(512, activation=tf.nn.relu, input_shape=(NUM_WORDS,)), 82 keras.layers.Dense(512, activation=tf.nn.relu), 83 keras.layers.Dense(1, activation=tf.nn.sigmoid) 84 ]) 85 bigger_model.compile(optimizer='adam', 86 loss='binary_crossentropy', 87 metrics=['accuracy', 'binary_crossentropy']) 88 bigger_model.summary() 89 bigger_history = bigger_model.fit(train_data, 90 train_labels, 91 epochs=20, 92 batch_size=512, 93 validation_data=(test_data, test_labels), 94 verbose=2) # 使用相同的数据训练 95 96 97 # 绘制训练损失和验证损失图表 98 # 这里实线表示训练损失,虚线表示验证损失(验证损失越低,表示模型越好) 99 def plot_history(histories, key='binary_crossentropy'): 100 plt.figure(figsize=(16, 10)) 101 for name, his in histories: 102 val = plt.plot(his.epoch, 103 his.history['val_' + key], 104 linestyle='--', # 默认颜色的虚线(dashed line with default color) 105 label=name.title() + ' Val') 106 plt.plot(his.epoch, 107 his.history[key], 108 color=val[0].get_color(), 109 label=name.title() + ' Train') 110 plt.xlabel('Epochs') 111 plt.ylabel(key.replace('_', ' ').title()) 112 plt.legend() 113 plt.xlim([0, max(his.epoch)]) 114 115 116 plot_history([('baseline', baseline_history), ('smaller', smaller_history), ('bigger', bigger_history)]) 117 plt.savefig("./outputs/sample-4-figure-2.png", dpi=200, format='png') 118 plt.show() 119 plt.close() 120 121 # ### 策略 122 # 添加权重正则化 123 l2_model = keras.models.Sequential([ 124 keras.layers.Dense(16, 125 kernel_regularizer=keras.regularizers.l2(0.001), # 添加L2权重正则化 126 activation=tf.nn.relu, 127 input_shape=(NUM_WORDS,)), 128 keras.layers.Dense(16, 129 kernel_regularizer=keras.regularizers.l2(0.001), # 实际上是将权重正则化项实例作为关键字参数传递给层 130 activation=tf.nn.relu), 131 keras.layers.Dense(1, activation=tf.nn.sigmoid)]) 132 l2_model.compile(optimizer='adam', 133 loss='binary_crossentropy', 134 metrics=['accuracy', 'binary_crossentropy']) 135 l2_model_history = l2_model.fit(train_data, 136 train_labels, 137 epochs=20, 138 batch_size=512, 139 validation_data=(test_data, test_labels), 140 verbose=2) # 使用相同的数据训练 141 plot_history([('baseline', baseline_history), ('l2', l2_model_history)]) 142 plt.savefig("./outputs/sample-4-figure-3.png", dpi=200, format='png') 143 plt.show() # 查看在训练阶段添加L2正则化惩罚的影响,此过拟合抵抗能力强于基准模型 144 plt.close() 145 146 # 添加丢弃层 147 dpt_model = keras.models.Sequential([ 148 keras.layers.Dense(16, activation=tf.nn.relu, input_shape=(NUM_WORDS,)), 149 keras.layers.Dropout(0.5), # 通过丢弃层将丢弃引入网络中,以便事先将其应用于层的输出 150 keras.layers.Dense(16, activation=tf.nn.relu), 151 keras.layers.Dropout(0.5), # 添加丢弃层,“丢弃率”设置在0.5 152 keras.layers.Dense(1, activation=tf.nn.sigmoid) 153 ]) 154 dpt_model.compile(optimizer='adam', 155 loss='binary_crossentropy', 156 metrics=['accuracy', 'binary_crossentropy']) 157 dpt_model_history = dpt_model.fit(train_data, train_labels, 158 epochs=20, 159 batch_size=512, 160 validation_data=(test_data, test_labels), 161 verbose=2) 162 plot_history([('baseline', baseline_history), ('dropout', dpt_model_history)]) 163 plt.savefig("./outputs/sample-4-figure-4.png", dpi=200, format='png') 164 plt.show() 165 plt.close()
运行结果
C:UsersanlivenAppDataLocalcondacondaenvsmlccpython.exe D:/Anliven/Anliven-Code/PycharmProjects/Google-Learn-and-use-ML/4_overfit_and_underfit.py
# TensorFlow version: 1.12.0 - tf.keras version: 2.1.6-tf
# np_data keys: ['x_test', 'x_train', 'y_train', 'y_test']
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 16) 160016
_________________________________________________________________
dense_1 (Dense) (None, 16) 272
_________________________________________________________________
dense_2 (Dense) (None, 1) 17
=================================================================
Total params: 160,305
Trainable params: 160,305
Non-trainable params: 0
_________________________________________________________________
Train on 25000 samples, validate on 25000 samples
Epoch 1/20
- 6s - loss: 0.4610 - acc: 0.8232 - binary_crossentropy: 0.4610 - val_loss: 0.3217 - val_acc: 0.8791 - val_binary_crossentropy: 0.3217
Epoch 2/20
- 5s - loss: 0.2379 - acc: 0.9151 - binary_crossentropy: 0.2379 - val_loss: 0.2829 - val_acc: 0.8876 - val_binary_crossentropy: 0.2829
Epoch 3/20
- 4s - loss: 0.1763 - acc: 0.9379 - binary_crossentropy: 0.1763 - val_loss: 0.2900 - val_acc: 0.8847 - val_binary_crossentropy: 0.2900
Epoch 4/20
- 4s - loss: 0.1402 - acc: 0.9524 - binary_crossentropy: 0.1402 - val_loss: 0.3163 - val_acc: 0.8788 - val_binary_crossentropy: 0.3163
Epoch 5/20
- 4s - loss: 0.1145 - acc: 0.9633 - binary_crossentropy: 0.1145 - val_loss: 0.3436 - val_acc: 0.8731 - val_binary_crossentropy: 0.3436
Epoch 6/20
- 4s - loss: 0.0913 - acc: 0.9738 - binary_crossentropy: 0.0913 - val_loss: 0.3759 - val_acc: 0.8697 - val_binary_crossentropy: 0.3759
Epoch 7/20
- 4s - loss: 0.0719 - acc: 0.9811 - binary_crossentropy: 0.0719 - val_loss: 0.4285 - val_acc: 0.8619 - val_binary_crossentropy: 0.4285
Epoch 8/20
- 4s - loss: 0.0562 - acc: 0.9869 - binary_crossentropy: 0.0562 - val_loss: 0.4527 - val_acc: 0.8634 - val_binary_crossentropy: 0.4527
Epoch 9/20
- 5s - loss: 0.0432 - acc: 0.9921 - binary_crossentropy: 0.0432 - val_loss: 0.4926 - val_acc: 0.8598 - val_binary_crossentropy: 0.4926
Epoch 10/20
- 4s - loss: 0.0326 - acc: 0.9949 - binary_crossentropy: 0.0326 - val_loss: 0.5394 - val_acc: 0.8570 - val_binary_crossentropy: 0.5394
Epoch 11/20
- 5s - loss: 0.0243 - acc: 0.9972 - binary_crossentropy: 0.0243 - val_loss: 0.5726 - val_acc: 0.8569 - val_binary_crossentropy: 0.5726
Epoch 12/20
- 4s - loss: 0.0182 - acc: 0.9984 - binary_crossentropy: 0.0182 - val_loss: 0.6164 - val_acc: 0.8562 - val_binary_crossentropy: 0.6164
Epoch 13/20
- 4s - loss: 0.0133 - acc: 0.9991 - binary_crossentropy: 0.0133 - val_loss: 0.6419 - val_acc: 0.8547 - val_binary_crossentropy: 0.6419
Epoch 14/20
- 4s - loss: 0.0102 - acc: 0.9995 - binary_crossentropy: 0.0102 - val_loss: 0.6774 - val_acc: 0.8531 - val_binary_crossentropy: 0.6774
Epoch 15/20
- 4s - loss: 0.0077 - acc: 0.9997 - binary_crossentropy: 0.0077 - val_loss: 0.7014 - val_acc: 0.8539 - val_binary_crossentropy: 0.7014
Epoch 16/20
- 5s - loss: 0.0060 - acc: 0.9998 - binary_crossentropy: 0.0060 - val_loss: 0.7268 - val_acc: 0.8532 - val_binary_crossentropy: 0.7268
Epoch 17/20
- 5s - loss: 0.0048 - acc: 1.0000 - binary_crossentropy: 0.0048 - val_loss: 0.7493 - val_acc: 0.8541 - val_binary_crossentropy: 0.7493
Epoch 18/20
- 5s - loss: 0.0039 - acc: 1.0000 - binary_crossentropy: 0.0039 - val_loss: 0.7733 - val_acc: 0.8530 - val_binary_crossentropy: 0.7733
Epoch 19/20
- 5s - loss: 0.0033 - acc: 1.0000 - binary_crossentropy: 0.0033 - val_loss: 0.7883 - val_acc: 0.8535 - val_binary_crossentropy: 0.7883
Epoch 20/20
- 5s - loss: 0.0028 - acc: 1.0000 - binary_crossentropy: 0.0028 - val_loss: 0.8105 - val_acc: 0.8533 - val_binary_crossentropy: 0.8105
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_3 (Dense) (None, 4) 40004
_________________________________________________________________
dense_4 (Dense) (None, 4) 20
_________________________________________________________________
dense_5 (Dense) (None, 1) 5
=================================================================
Total params: 40,029
Trainable params: 40,029
Non-trainable params: 0
_________________________________________________________________
Train on 25000 samples, validate on 25000 samples
Epoch 1/20
- 5s - loss: 0.6191 - acc: 0.6490 - binary_crossentropy: 0.6191 - val_loss: 0.5584 - val_acc: 0.7492 - val_binary_crossentropy: 0.5584
Epoch 2/20
- 5s - loss: 0.4989 - acc: 0.8361 - binary_crossentropy: 0.4989 - val_loss: 0.4795 - val_acc: 0.8600 - val_binary_crossentropy: 0.4795
Epoch 3/20
- 5s - loss: 0.4216 - acc: 0.9002 - binary_crossentropy: 0.4216 - val_loss: 0.4286 - val_acc: 0.8737 - val_binary_crossentropy: 0.4286
Epoch 4/20
- 5s - loss: 0.3551 - acc: 0.9257 - binary_crossentropy: 0.3551 - val_loss: 0.3811 - val_acc: 0.8820 - val_binary_crossentropy: 0.3811
Epoch 5/20
- 5s - loss: 0.2593 - acc: 0.9428 - binary_crossentropy: 0.2593 - val_loss: 0.3011 - val_acc: 0.8829 - val_binary_crossentropy: 0.3011
Epoch 6/20
- 5s - loss: 0.1775 - acc: 0.9496 - binary_crossentropy: 0.1775 - val_loss: 0.2934 - val_acc: 0.8827 - val_binary_crossentropy: 0.2934
Epoch 7/20
- 5s - loss: 0.1435 - acc: 0.9575 - binary_crossentropy: 0.1435 - val_loss: 0.3068 - val_acc: 0.8790 - val_binary_crossentropy: 0.3068
Epoch 8/20
- 5s - loss: 0.1213 - acc: 0.9651 - binary_crossentropy: 0.1213 - val_loss: 0.3301 - val_acc: 0.8760 - val_binary_crossentropy: 0.3301
Epoch 9/20
- 5s - loss: 0.1043 - acc: 0.9701 - binary_crossentropy: 0.1043 - val_loss: 0.3437 - val_acc: 0.8736 - val_binary_crossentropy: 0.3437
Epoch 10/20
- 5s - loss: 0.0907 - acc: 0.9756 - binary_crossentropy: 0.0907 - val_loss: 0.3651 - val_acc: 0.8706 - val_binary_crossentropy: 0.3651
Epoch 11/20
- 5s - loss: 0.0793 - acc: 0.9793 - binary_crossentropy: 0.0793 - val_loss: 0.3876 - val_acc: 0.8688 - val_binary_crossentropy: 0.3876
Epoch 12/20
- 5s - loss: 0.0690 - acc: 0.9836 - binary_crossentropy: 0.0690 - val_loss: 0.4072 - val_acc: 0.8667 - val_binary_crossentropy: 0.4072
Epoch 13/20
- 5s - loss: 0.0606 - acc: 0.9864 - binary_crossentropy: 0.0606 - val_loss: 0.4332 - val_acc: 0.8650 - val_binary_crossentropy: 0.4332
Epoch 14/20
- 5s - loss: 0.0528 - acc: 0.9896 - binary_crossentropy: 0.0528 - val_loss: 0.4589 - val_acc: 0.8640 - val_binary_crossentropy: 0.4589
Epoch 15/20
- 5s - loss: 0.0460 - acc: 0.9915 - binary_crossentropy: 0.0460 - val_loss: 0.4782 - val_acc: 0.8636 - val_binary_crossentropy: 0.4782
Epoch 16/20
- 5s - loss: 0.0404 - acc: 0.9936 - binary_crossentropy: 0.0404 - val_loss: 0.5011 - val_acc: 0.8617 - val_binary_crossentropy: 0.5011
Epoch 17/20
- 5s - loss: 0.0355 - acc: 0.9946 - binary_crossentropy: 0.0355 - val_loss: 0.5238 - val_acc: 0.8601 - val_binary_crossentropy: 0.5238
Epoch 18/20
- 5s - loss: 0.0310 - acc: 0.9959 - binary_crossentropy: 0.0310 - val_loss: 0.5618 - val_acc: 0.8597 - val_binary_crossentropy: 0.5618
Epoch 19/20
- 5s - loss: 0.0271 - acc: 0.9966 - binary_crossentropy: 0.0271 - val_loss: 0.5733 - val_acc: 0.8586 - val_binary_crossentropy: 0.5733
Epoch 20/20
- 5s - loss: 0.0239 - acc: 0.9973 - binary_crossentropy: 0.0239 - val_loss: 0.5941 - val_acc: 0.8590 - val_binary_crossentropy: 0.5941
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_6 (Dense) (None, 512) 5120512
_________________________________________________________________
dense_7 (Dense) (None, 512) 262656
_________________________________________________________________
dense_8 (Dense) (None, 1) 513
=================================================================
Total params: 5,383,681
Trainable params: 5,383,681
Non-trainable params: 0
_________________________________________________________________
Train on 25000 samples, validate on 25000 samples
Epoch 1/20
- 12s - loss: 0.3449 - acc: 0.8565 - binary_crossentropy: 0.3449 - val_loss: 0.2915 - val_acc: 0.8830 - val_binary_crossentropy: 0.2915
Epoch 2/20
- 11s - loss: 0.1326 - acc: 0.9509 - binary_crossentropy: 0.1326 - val_loss: 0.3543 - val_acc: 0.8648 - val_binary_crossentropy: 0.3543
Epoch 3/20
- 11s - loss: 0.0385 - acc: 0.9890 - binary_crossentropy: 0.0385 - val_loss: 0.4418 - val_acc: 0.8698 - val_binary_crossentropy: 0.4418
Epoch 4/20
- 11s - loss: 0.0063 - acc: 0.9990 - binary_crossentropy: 0.0063 - val_loss: 0.5891 - val_acc: 0.8718 - val_binary_crossentropy: 0.5891
Epoch 5/20
- 11s - loss: 9.8004e-04 - acc: 1.0000 - binary_crossentropy: 9.8004e-04 - val_loss: 0.6631 - val_acc: 0.8728 - val_binary_crossentropy: 0.6631
Epoch 6/20
- 11s - loss: 2.3721e-04 - acc: 1.0000 - binary_crossentropy: 2.3721e-04 - val_loss: 0.7085 - val_acc: 0.8729 - val_binary_crossentropy: 0.7085
Epoch 7/20
- 11s - loss: 1.3367e-04 - acc: 1.0000 - binary_crossentropy: 1.3367e-04 - val_loss: 0.7327 - val_acc: 0.8731 - val_binary_crossentropy: 0.7327
Epoch 8/20
- 11s - loss: 9.4933e-05 - acc: 1.0000 - binary_crossentropy: 9.4933e-05 - val_loss: 0.7523 - val_acc: 0.8731 - val_binary_crossentropy: 0.7523
Epoch 9/20
- 11s - loss: 7.2803e-05 - acc: 1.0000 - binary_crossentropy: 7.2803e-05 - val_loss: 0.7686 - val_acc: 0.8728 - val_binary_crossentropy: 0.7686
Epoch 10/20
- 11s - loss: 5.8082e-05 - acc: 1.0000 - binary_crossentropy: 5.8082e-05 - val_loss: 0.7809 - val_acc: 0.8728 - val_binary_crossentropy: 0.7809
Epoch 11/20
- 11s - loss: 4.7624e-05 - acc: 1.0000 - binary_crossentropy: 4.7624e-05 - val_loss: 0.7929 - val_acc: 0.8728 - val_binary_crossentropy: 0.7929
Epoch 12/20
- 11s - loss: 3.9747e-05 - acc: 1.0000 - binary_crossentropy: 3.9747e-05 - val_loss: 0.8028 - val_acc: 0.8728 - val_binary_crossentropy: 0.8028
Epoch 13/20
- 11s - loss: 3.3734e-05 - acc: 1.0000 - binary_crossentropy: 3.3734e-05 - val_loss: 0.8119 - val_acc: 0.8728 - val_binary_crossentropy: 0.8119
Epoch 14/20
- 11s - loss: 2.8974e-05 - acc: 1.0000 - binary_crossentropy: 2.8974e-05 - val_loss: 0.8207 - val_acc: 0.8730 - val_binary_crossentropy: 0.8207
Epoch 15/20
- 11s - loss: 2.5101e-05 - acc: 1.0000 - binary_crossentropy: 2.5101e-05 - val_loss: 0.8285 - val_acc: 0.8732 - val_binary_crossentropy: 0.8285
Epoch 16/20
- 11s - loss: 2.1962e-05 - acc: 1.0000 - binary_crossentropy: 2.1962e-05 - val_loss: 0.8352 - val_acc: 0.8729 - val_binary_crossentropy: 0.8352
Epoch 17/20
- 11s - loss: 1.9356e-05 - acc: 1.0000 - binary_crossentropy: 1.9356e-05 - val_loss: 0.8432 - val_acc: 0.8731 - val_binary_crossentropy: 0.8432
Epoch 18/20
- 11s - loss: 1.7169e-05 - acc: 1.0000 - binary_crossentropy: 1.7169e-05 - val_loss: 0.8488 - val_acc: 0.8731 - val_binary_crossentropy: 0.8488
Epoch 19/20
- 11s - loss: 1.5288e-05 - acc: 1.0000 - binary_crossentropy: 1.5288e-05 - val_loss: 0.8549 - val_acc: 0.8733 - val_binary_crossentropy: 0.8549
Epoch 20/20
- 11s - loss: 1.3696e-05 - acc: 1.0000 - binary_crossentropy: 1.3696e-05 - val_loss: 0.8616 - val_acc: 0.8730 - val_binary_crossentropy: 0.8616
Train on 25000 samples, validate on 25000 samples
Epoch 1/20
- 5s - loss: 0.5584 - acc: 0.7977 - binary_crossentropy: 0.5183 - val_loss: 0.4038 - val_acc: 0.8720 - val_binary_crossentropy: 0.3629
Epoch 2/20
- 5s - loss: 0.3198 - acc: 0.9048 - binary_crossentropy: 0.2738 - val_loss: 0.3381 - val_acc: 0.8876 - val_binary_crossentropy: 0.2881
Epoch 3/20
- 5s - loss: 0.2625 - acc: 0.9258 - binary_crossentropy: 0.2096 - val_loss: 0.3383 - val_acc: 0.8869 - val_binary_crossentropy: 0.2832
Epoch 4/20
- 5s - loss: 0.2360 - acc: 0.9384 - binary_crossentropy: 0.1793 - val_loss: 0.3496 - val_acc: 0.8838 - val_binary_crossentropy: 0.2918
Epoch 5/20
- 5s - loss: 0.2226 - acc: 0.9444 - binary_crossentropy: 0.1631 - val_loss: 0.3622 - val_acc: 0.8798 - val_binary_crossentropy: 0.3019
Epoch 6/20
- 5s - loss: 0.2091 - acc: 0.9502 - binary_crossentropy: 0.1481 - val_loss: 0.3760 - val_acc: 0.8769 - val_binary_crossentropy: 0.3147
Epoch 7/20
- 5s - loss: 0.2018 - acc: 0.9530 - binary_crossentropy: 0.1395 - val_loss: 0.3891 - val_acc: 0.8734 - val_binary_crossentropy: 0.3261
Epoch 8/20
- 5s - loss: 0.1934 - acc: 0.9567 - binary_crossentropy: 0.1297 - val_loss: 0.3999 - val_acc: 0.8723 - val_binary_crossentropy: 0.3361
Epoch 9/20
- 5s - loss: 0.1876 - acc: 0.9576 - binary_crossentropy: 0.1234 - val_loss: 0.4165 - val_acc: 0.8708 - val_binary_crossentropy: 0.3518
Epoch 10/20
- 5s - loss: 0.1863 - acc: 0.9590 - binary_crossentropy: 0.1208 - val_loss: 0.4324 - val_acc: 0.8658 - val_binary_crossentropy: 0.3665
Epoch 11/20
- 5s - loss: 0.1800 - acc: 0.9622 - binary_crossentropy: 0.1137 - val_loss: 0.4393 - val_acc: 0.8662 - val_binary_crossentropy: 0.3725
Epoch 12/20
- 5s - loss: 0.1762 - acc: 0.9629 - binary_crossentropy: 0.1095 - val_loss: 0.4561 - val_acc: 0.8625 - val_binary_crossentropy: 0.3891
Epoch 13/20
- 5s - loss: 0.1752 - acc: 0.9629 - binary_crossentropy: 0.1073 - val_loss: 0.4601 - val_acc: 0.8643 - val_binary_crossentropy: 0.3919
Epoch 14/20
- 5s - loss: 0.1654 - acc: 0.9684 - binary_crossentropy: 0.0974 - val_loss: 0.4675 - val_acc: 0.8608 - val_binary_crossentropy: 0.3999
Epoch 15/20
- 5s - loss: 0.1592 - acc: 0.9708 - binary_crossentropy: 0.0917 - val_loss: 0.4790 - val_acc: 0.8616 - val_binary_crossentropy: 0.4114
Epoch 16/20
- 5s - loss: 0.1559 - acc: 0.9723 - binary_crossentropy: 0.0880 - val_loss: 0.4906 - val_acc: 0.8592 - val_binary_crossentropy: 0.4226
Epoch 17/20
- 5s - loss: 0.1538 - acc: 0.9722 - binary_crossentropy: 0.0857 - val_loss: 0.4978 - val_acc: 0.8580 - val_binary_crossentropy: 0.4293
Epoch 18/20
- 5s - loss: 0.1515 - acc: 0.9730 - binary_crossentropy: 0.0827 - val_loss: 0.5072 - val_acc: 0.8593 - val_binary_crossentropy: 0.4379
Epoch 19/20
- 5s - loss: 0.1480 - acc: 0.9746 - binary_crossentropy: 0.0788 - val_loss: 0.5159 - val_acc: 0.8595 - val_binary_crossentropy: 0.4464
Epoch 20/20
- 5s - loss: 0.1453 - acc: 0.9756 - binary_crossentropy: 0.0755 - val_loss: 0.5298 - val_acc: 0.8558 - val_binary_crossentropy: 0.4596
Train on 25000 samples, validate on 25000 samples
Epoch 1/20
- 6s - loss: 0.6409 - acc: 0.6162 - binary_crossentropy: 0.6409 - val_loss: 0.5187 - val_acc: 0.8435 - val_binary_crossentropy: 0.5187
Epoch 2/20
- 5s - loss: 0.4922 - acc: 0.7780 - binary_crossentropy: 0.4922 - val_loss: 0.3810 - val_acc: 0.8824 - val_binary_crossentropy: 0.3810
Epoch 3/20
- 5s - loss: 0.3860 - acc: 0.8527 - binary_crossentropy: 0.3860 - val_loss: 0.3089 - val_acc: 0.8864 - val_binary_crossentropy: 0.3089
Epoch 4/20
- 5s - loss: 0.3196 - acc: 0.8917 - binary_crossentropy: 0.3196 - val_loss: 0.2820 - val_acc: 0.8868 - val_binary_crossentropy: 0.2820
Epoch 5/20
- 5s - loss: 0.2628 - acc: 0.9102 - binary_crossentropy: 0.2628 - val_loss: 0.2768 - val_acc: 0.8890 - val_binary_crossentropy: 0.2768
Epoch 6/20
- 5s - loss: 0.2295 - acc: 0.9249 - binary_crossentropy: 0.2295 - val_loss: 0.2855 - val_acc: 0.8877 - val_binary_crossentropy: 0.2855
Epoch 7/20
- 5s - loss: 0.1997 - acc: 0.9352 - binary_crossentropy: 0.1997 - val_loss: 0.2991 - val_acc: 0.8848 - val_binary_crossentropy: 0.2991
Epoch 8/20
- 5s - loss: 0.1733 - acc: 0.9440 - binary_crossentropy: 0.1733 - val_loss: 0.3232 - val_acc: 0.8822 - val_binary_crossentropy: 0.3232
Epoch 9/20
- 5s - loss: 0.1560 - acc: 0.9499 - binary_crossentropy: 0.1560 - val_loss: 0.3375 - val_acc: 0.8823 - val_binary_crossentropy: 0.3375
Epoch 10/20
- 5s - loss: 0.1409 - acc: 0.9548 - binary_crossentropy: 0.1409 - val_loss: 0.3519 - val_acc: 0.8799 - val_binary_crossentropy: 0.3519
Epoch 11/20
- 5s - loss: 0.1216 - acc: 0.9602 - binary_crossentropy: 0.1216 - val_loss: 0.3782 - val_acc: 0.8796 - val_binary_crossentropy: 0.3782
Epoch 12/20
- 5s - loss: 0.1134 - acc: 0.9634 - binary_crossentropy: 0.1134 - val_loss: 0.4102 - val_acc: 0.8778 - val_binary_crossentropy: 0.4102
Epoch 13/20
- 5s - loss: 0.1025 - acc: 0.9660 - binary_crossentropy: 0.1025 - val_loss: 0.4156 - val_acc: 0.8769 - val_binary_crossentropy: 0.4156
Epoch 14/20
- 5s - loss: 0.0936 - acc: 0.9684 - binary_crossentropy: 0.0936 - val_loss: 0.4446 - val_acc: 0.8778 - val_binary_crossentropy: 0.4446
Epoch 15/20
- 5s - loss: 0.0883 - acc: 0.9695 - binary_crossentropy: 0.0883 - val_loss: 0.4888 - val_acc: 0.8729 - val_binary_crossentropy: 0.4888
Epoch 16/20
- 5s - loss: 0.0809 - acc: 0.9718 - binary_crossentropy: 0.0809 - val_loss: 0.4867 - val_acc: 0.8762 - val_binary_crossentropy: 0.4867
Epoch 17/20
- 5s - loss: 0.0762 - acc: 0.9721 - binary_crossentropy: 0.0762 - val_loss: 0.5257 - val_acc: 0.8755 - val_binary_crossentropy: 0.5257
Epoch 18/20
- 5s - loss: 0.0701 - acc: 0.9735 - binary_crossentropy: 0.0701 - val_loss: 0.5329 - val_acc: 0.8748 - val_binary_crossentropy: 0.5329
Epoch 19/20
- 5s - loss: 0.0681 - acc: 0.9752 - binary_crossentropy: 0.0681 - val_loss: 0.5602 - val_acc: 0.8725 - val_binary_crossentropy: 0.5602
Epoch 20/20
- 5s - loss: 0.0628 - acc: 0.9760 - binary_crossentropy: 0.0628 - val_loss: 0.5939 - val_acc: 0.8746 - val_binary_crossentropy: 0.5939