过拟合
过拟合(overfitting,过度学习,过度拟合):
过度准确地拟合了历史数据(精确的区分了所有的训练数据),而对新数据适应性较差,预测时会有很大误差。
过拟合是机器学习中常见的问题,解决方法主要有下面几种:
1. 增加数据量
大部分过拟合产生的原因是因为数据量太少。
2. 运用正则化
例如L1、L2 regularization等等,适用于大多数的机器学习,包括神经网络。
3. Dropout
专门用在神经网络的正则化的方法。
Dropout regularization是指在深度学习网络的训练过程中,按照一定的概率将一部分神经网络单元暂时从网络中丢弃,相当于从原始的网络中找到一个更瘦的网络。
只需要给予它一个不被drop掉的百分比,就能很好地降低overfitting。
也就是说,在训练的时候,随机忽略掉一些神经元和神经联结 ,使这个神经网络变得”不完整”,然后用一个不完整的神经网络训练一次。
到第二次再随机忽略另一些, 变成另一个不完整的神经网络。
有了这些随机drop掉的规则, 每一次预测结果都不会依赖于其中某部分特定的神经元。
Dropout的做法是从根本上让神经网络没机会过度依赖。
TensorFlow中的Dropout方法
TensorFlow提供了强大的dropout方法来解决overfitting问题。
示例
1 # coding=utf-8 2 from __future__ import print_function 3 import tensorflow as tf 4 from sklearn.datasets import load_digits # 使用sklearn中的数据 5 from sklearn.model_selection import train_test_split 6 from sklearn.preprocessing import LabelBinarizer 7 import os 8 9 os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' 10 11 digits = load_digits() 12 X = digits.data 13 y = digits.target 14 y = LabelBinarizer().fit_transform(y) 15 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=.3) # X_train是训练数据, X_test是测试数据 16 17 18 def add_layer(inputs, in_size, out_size, layer_name, activation_function=None, ): 19 Weights = tf.Variable(tf.random_normal([in_size, out_size])) 20 biases = tf.Variable(tf.zeros([1, out_size]) + 0.1, ) 21 Wx_plus_b = tf.matmul(inputs, Weights) + biases 22 Wx_plus_b = tf.nn.dropout(Wx_plus_b, keep_prob) # dropout 23 if activation_function is None: 24 outputs = Wx_plus_b 25 else: 26 outputs = activation_function(Wx_plus_b, ) 27 tf.summary.histogram(layer_name + '/outputs', outputs) 28 return outputs 29 30 31 keep_prob = tf.placeholder(tf.float32) # keep_prob(保留的结果所占比例)作为placeholder在run时传入 32 xs = tf.placeholder(tf.float32, [None, 64]) 33 ys = tf.placeholder(tf.float32, [None, 10]) 34 35 l1 = add_layer(xs, 64, 50, 'l1', activation_function=tf.nn.tanh) # 隐含层 36 prediction = add_layer(l1, 50, 10, 'l2', activation_function=tf.nn.softmax) # 输出层 37 38 cross_entropy = tf.reduce_mean(-tf.reduce_sum(ys * tf.log(prediction), 39 reduction_indices=[1])) # loss between prediction and real data 40 tf.summary.scalar('loss', cross_entropy) 41 train_step = tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy) 42 43 sess = tf.Session() 44 merged = tf.summary.merge_all() 45 train_writer = tf.summary.FileWriter("logs/train", sess.graph) 46 test_writer = tf.summary.FileWriter("logs/test", sess.graph) 47 init = tf.global_variables_initializer() 48 sess.run(init) 49 50 for i in range(500): 51 sess.run(train_step, feed_dict={xs: X_train, ys: y_train, keep_prob: 0.5}) # keep_prob=0.5相当于50%保留 52 if i % 50 == 0: 53 train_result = sess.run(merged, feed_dict={xs: X_train, ys: y_train, keep_prob: 1}) 54 test_result = sess.run(merged, feed_dict={xs: X_test, ys: y_test, keep_prob: 1}) 55 train_writer.add_summary(train_result, i) 56 test_writer.add_summary(test_result, i)
对比运行结果
在TensorBoard中查看。
训练中keep_prob=1时,暴露出overfitting问题,模型对训练数据的适应性优于测试数据,存在overfitting。
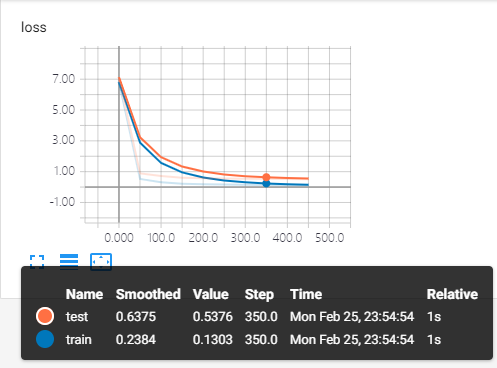
keep_prob=0.5时,dropout发挥了作用,减少了过拟合。
