接着上篇继续跟着沫凡小哥学Python啦
1.1 什么是多线程 Threading
多线程可简单理解为同时执行多个任务。
多进程和多线程都可以执行多个任务,线程是进程的一部分。线程的特点是线程之间可以共享内存和变量,资源消耗少(不过在Unix环境中,多进程和多线程资源调度消耗差距不明显,Unix调度较快),缺点是线程之间的同步和加锁比较麻烦。
1.2 添加线程 Thread
导入模块
import threading
获取已激活的线程数
threading.active_count()
查看所有线程信息
threading.enumerate()
查看现在正在运行的线程
threading.current_thread()
添加线程,threading.Thread()接收参数target代表这个线程要完成的任务,需自行定义

def thread_job():
print('This is a thread of %s' % threading.current_thread())
def main():
thread = threading.Thread(target=thread_job,) # 定义线程
thread.start() # 让线程开始工作
if __name__ == '__main__':
main()
1.3 join 功能
因为线程是同时进行的,使用join功能可让线程完成后再进行下一步操作,即阻塞调用线程,直到队列中的所有任务被处理掉。
import threading
import time
def thread_job():
print('T1 start
')
for i in range(10):
time.sleep(0.1)
print('T1 finish
')
def T2_job():
print('T2 start
')
print('T2 finish
')
def main():
added_thread=threading.Thread(target=thread_job,name='T1')
thread2=threading.Thread(target=T2_job,name='T2')
added_thread.start()
#added_thread.join()
thread2.start()
#thread2.join()
print('all done
')
if __name__=='__main__':
main()
例子如上所示,当不使用join功能的时候,结果如下图所示:

当执行了join功能之后,T1运行完之后才运行T2,之后再运行print(‘all done’)

1.4 储存进程结果 queue
queue是python标准库中的线程安全的队列(FIFO)实现,提供了一个适用于多线程编程的先进先出的数据结构,即队列,用来在生产者和消费者线程之间的信息传递
(1)基本FIFO队列
class queue.Queue(maxsize=0)
maxsize是整数,表明队列中能存放的数据个数的上限,达到上限时,插入会导致阻塞,直至队列中的数据被消费掉,如果maxsize小于或者等于0,队列大小没有限制
(2)LIFO队列 last in first out后进先出
class queue.LifoQueue(maxsize=0)
(3)优先级队列
class queue.PriorityQueue(maxsize=0)
视频中的代码,看的还不是特别明白
import threading
import time
from queue import Queue
def job(l,q):
for i in range(len(l)):
l[i]=l[i]**2
q.put(l)
def multithreading():
q=Queue()
threads=[]
data=[[1,2,3],[3,4,5],[4,5,6],[5,6,7]]
for i in range(4):
t=threading.Thread(target=job,args=(data[i],q))
t.start()
threads.append(t)
for thread in threads:
thread.join()
results=[]
for _ in range(4):
results.append(q.get())
print(results)
if __name__=='__main__':
multithreading()
运行结果如下所示


图片截取来源:http://www.cnblogs.com/itogo/p/5635629.html
1.5 GIL 不一定有效率
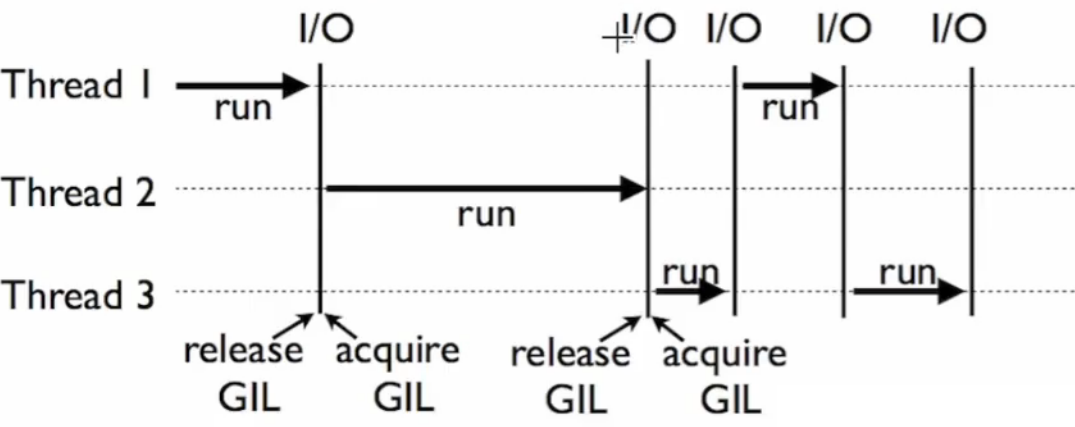
Global Interpreter Lock全局解释器锁,python的执行由python虚拟机(也成解释器主循环)控制,GIL的控制对python虚拟机的访问,保证在任意时刻,只有一个线程在解释器中运行。在多线程环境中能,python虚拟机按照以下方式执行:
1.设置 GIL
2.切换到一个线程去运行
3.运行:
a.指定数量的字节码指令,或
b.线程主动让出控制(可以调用time.sleep(0))
4.把线程设置为睡眠状态
5.解锁GIL
6.重复1-5
在调用外部代码(如C/C++扩展函数)的时候,GIL将会被锁定,直到这个函数结束为止(由于在这期间没有python的字节码被运行,所以不会做线程切换)。
下面为视频中所举例的代码,将一个数扩大4倍,分为正常方式、以及分配给4个线程去做,发现耗时其实并没有相差太多量级。
import threading
from queue import Queue
import copy
import time
def job(l, q):
res = sum(l)
q.put(res)
def multithreading(l):
q = Queue()
threads = []
for i in range(4):
t = threading.Thread(target=job, args=(copy.copy(l), q), name='T%i' % i)
t.start()
threads.append(t)
[t.join() for t in threads]
total = 0
for _ in range(4):
total += q.get()
print(total)
def normal(l):
total = sum(l)
print(total)
if __name__ == '__main__':
l = list(range(1000000))
s_t = time.time()
normal(l*4)
print('normal: ',time.time()-s_t)
s_t = time.time()
multithreading(l)
print('multithreading: ', time.time()-s_t)
运行结果为:
1.6 线程锁 Lock
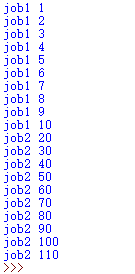
如果线程1得到了结果,想要让线程2继续使用1的结果进行处理,则需要对1lock,等到1执行完,再开始执行线程2。一般来说对share memory即对共享内存进行加工处理时会用到lock。
import threading
def job1():
global A, lock #全局变量
lock.acquire() #开始lock
for i in range(10):
A += 1
print('job1', A)
lock.release() #释放
def job2():
global A, lock
lock.acquire()
for i in range(10):
A += 10
print('job2', A)
lock.release()
if __name__ == '__main__':
lock = threading.Lock()
A = 0
t1 = threading.Thread(target=job1)
t2 = threading.Thread(target=job2)
t1.start()
t2.start()
t1.join()
t2.join()
运行结果如下所示: