一 要求
全栈爬取哔哩哔哩小视频.
url=http://vc.bilibili.com/p/eden/rank#/?tab=%E5%85%A8%E9%83%A8
二 分析
首页分析


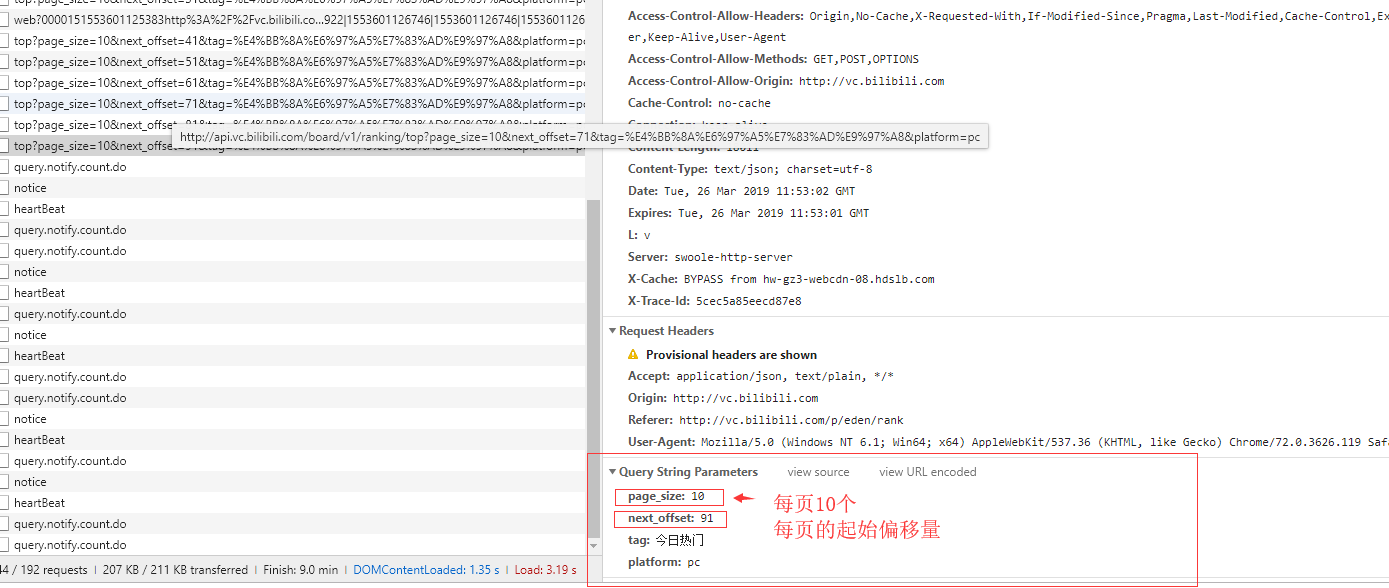
查看请求数据
代码
import requests import jsonpath headers={ 'Origin': 'http://vc.bilibili.com', 'Referer': 'http://vc.bilibili.com/p/eden/rank', 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.119 Safari/537.36', } def get_data(url,headers,params): '获取详情页的信息 data=requests.get(url=url,headers=headers).json() return jsonpath.jsonpath(data,'$..video_playurl') #返回url列表 for i in range(10): n=i*10+1 url = f'http://api.vc.bilibili.com/board/v1/ranking/top?page_size=10&next_offset={n}&tag=%E4%BB%8A%E6%97%A5%E7%83%AD%E9%97%A8&platform=pc' params = { 'page_size': 10, 'next_offset': n, 'tag': '今日热门', 'platform': 'pc', } video_playurl=get_data(url=url,headers=headers,params=params) try: j=0 for url in video_playurl: j+=1 data = requests.get(url=url, headers=headers, stream=True).content with open(f'./vedio/{i*10+j}.mp4', 'wb') as f: print(f'正在写入{i*10+j}.mp4') f.write(data) print(f'下载完毕{i*10+j}.mp4') except Exception as e: print(e)
效果图
