一、索引简介 #(本文推荐:https://www.cnblogs.com/clschao/articles/10049133.html)
索引:索引在MySQL中也叫做“键”或者"key"(primary key,unique key,还有一个index key),是存储引擎用于快速找到记录的一种数据结构。索引对于良好的性能非常关键,尤其是当表中的数据量越来越大时,索引对于性能的影响愈发重要,减少io次数,加速查询。
索引误区:索引不是越多越好。若索引太多,应用程序的性能可能会受到影响,可能造成磁盘使用率偏高。
二、索引原理
索引的影响
1、在表中有大量数据的前提下,创建索引速度会很慢。
2、在索引创建完毕后,对表的查询性能会发幅度提升,但是写性能会降低。
本质都是:通过不断地缩小想要获取数据的范围来筛选出最终想要的结果,同时把随机的事件变成顺序的事件,也就是说,有了这种索引机制,我们可以总是用同一种查找方式来锁定数据。
三、磁盘IO与预读
磁盘读取数据靠的是机械运动,每次读取数据花费的时间可以分为寻道时间、旋转延迟、传输时间三个部分,寻道时间指的是磁臂移动到指定磁道所需要的时间(主流磁盘一般在5ms以下);旋转延迟就是我们经常听说的磁盘转速(比如一个磁盘7200转/min,表示每分钟能转7200次,也就是说1秒钟能转120次,旋转延迟就是1/120/2 = 4.17ms,也就是半圈的时间),找到磁道了,寻点时间,这寻点时间的一个平均值就是半圈的时间,这个半圈时间叫做平均延迟时间,那么平均延迟时间加上平均寻道时间就是你找到一个数据所消耗的平均时间,传输时间指的是从磁盘读出或将数据写入磁盘的时间。
三、索引的数据结构
1、b+树结构
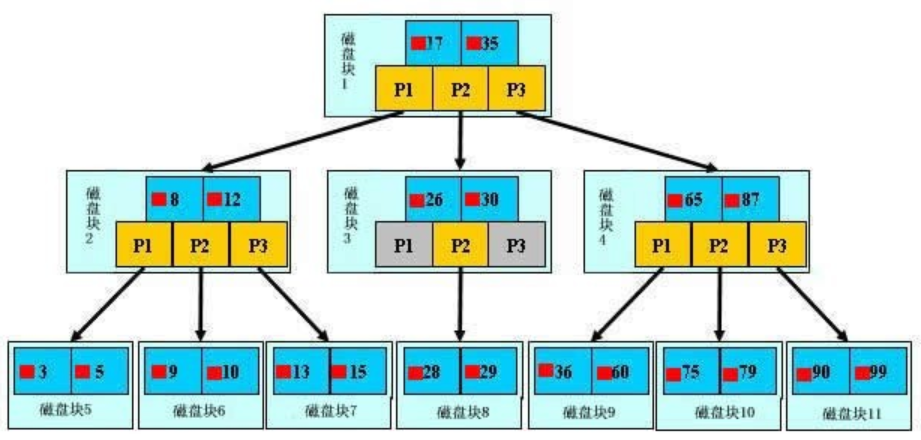
2、b+树性质
(1)1.索引字段要尽量的小 。这样数据块里面可以存储更多数据,再增加数据的时候可以使层数增加缓慢一些。

(2)索引的最左匹配特性:简单来说就是你的数据来了以后,从数据块的左边开始匹配,再匹配右边的。
四、聚集索引与辅助索引
1、聚集索引(根据主键建立的b+树结构)
InnoDB存储引擎表示索引组织表,即表中数据按照主键顺序存放。而聚集索引(clustered index)就是按照每张表的主键构造一棵B+树,同时叶子结点存放的即为整张表的行记录数据,也将聚集索引的叶子结点称为数据页。聚集索引的这个特性决定了索引组织表中数据也是索引的一部分。同B+树数据结构一样,每个数据页都通过一个双向链表来进行链接。
2、聚集索引的好处之一:它对主键的排序查找和范围查找速度非常快,叶子节点的数据就是用户所要查询的数据。如用户需要查找一张表,查询最后的10位用户信息,由于B+树索引是双向链表,所以用户可以快速找到最后一个数据页,并取出10条记录
#参照第六小结测试索引的准备阶段来创建出表s1 mysql> desc s1; #最开始没有主键 +--------+-------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +--------+-------------+------+-----+---------+-------+ | id | int(11) | NO | | NULL | | | name | varchar(20) | YES | | NULL | | | gender | char(6) | YES | | NULL | | | email | varchar(50) | YES | | NULL | | +--------+-------------+------+-----+---------+-------+ 4 rows in set (0.00 sec) mysql> explain select * from s1 order by id desc limit 10; #Using filesort,需要二次排序 +----+-------------+-------+------------+------+---------------+------+---------+------+---------+----------+----------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+------+---------+------+---------+----------+----------------+ | 1 | SIMPLE | s1 | NULL | ALL | NULL | NULL | NULL | NULL | 2633472 | 100.00 | Using filesort | +----+-------------+-------+------------+------+---------------+------+---------+------+---------+----------+----------------+ 1 row in set, 1 warning (0.11 sec) mysql> alter table s1 add primary key(id); #添加主键 Query OK, 0 rows affected (13.37 sec) Records: 0 Duplicates: 0 Warnings: 0 mysql> explain select * from s1 order by id desc limit 10; #基于主键的聚集索引在创建完毕后就已经完成了排序,无需二次排序 +----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+-------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+-------+ | 1 | SIMPLE | s1 | NULL | index | NULL | PRIMARY | 4 | NULL | 10 | 100.00 | NULL | +----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+-------+ 1 row in set, 1 warning (0.04 sec)
聚集索引的好处之二:范围查询(range query),即如果要查找主键某一范围内的数据,通过叶子节点的上层中间节点就可以得到页的范围,之后直接读取数据页即可。
mysql> alter table s1 drop primary key; Query OK, 2699998 rows affected (24.23 sec) Records: 2699998 Duplicates: 0 Warnings: 0 mysql> desc s1; +--------+-------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +--------+-------------+------+-----+---------+-------+ | id | int(11) | NO | | NULL | | | name | varchar(20) | YES | | NULL | | | gender | char(6) | YES | | NULL | | | email | varchar(50) | YES | | NULL | | +--------+-------------+------+-----+---------+-------+ 4 rows in set (0.12 sec) mysql> explain select * from s1 where id > 1 and id < 1000000; #没有聚集索引,预估需要检索的rows数如下,explain就是预估一下你的sql的执行效率 +----+-------------+-------+------------+------+---------------+------+---------+------+---------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+------+---------+------+---------+----------+-------------+ | 1 | SIMPLE | s1 | NULL | ALL | NULL | NULL | NULL | NULL | 2690100 | 11.11 | Using where | +----+-------------+-------+------------+------+---------------+------+---------+------+---------+----------+-------------+ 1 row in set, 1 warning (0.00 sec) mysql> alter table s1 add primary key(id); Query OK, 0 rows affected (16.25 sec) Records: 0 Duplicates: 0 Warnings: 0 mysql> explain select * from s1 where id > 1 and id < 1000000; #有聚集索引,预估需要检索的rows数如下 +----+-------------+-------+------------+-------+---------------+---------+---------+------+---------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+-------+---------------+---------+---------+------+---------+----------+-------------+ | 1 | SIMPLE | s1 | NULL | range | PRIMARY | PRIMARY | 4 | NULL | 1343355 | 100.00 | Using where | +----+-------------+-------+------------+-------+---------------+---------+---------+------+---------+----------+-------------+ 1 row in set, 1 warning (0.09 sec)
2、辅助索引
表中除了聚集索引外其他索引都是辅助索引(Secondary Index,也称为非聚集索引)(unique key啊、index key啊),与聚集索引的区别是:辅助索引的叶子节点不包含行记录的全部数据。
五、MySQL索引管理
一、功能
#1. 索引的功能就是加速查找 #2. mysql中的primary key,unique,联合唯一也都是索引,这些索引除了加速查找以外,还有约束的功能
二、创建索引
#方法一:创建表时 CREATE TABLE 表名 ( 字段名1 数据类型 [完整性约束条件…], 字段名2 数据类型 [完整性约束条件…], [UNIQUE | FULLTEXT | SPATIAL ] INDEX | KEY [索引名] (字段名[(长度)] [ASC |DESC]) ); #方法二:CREATE在已存在的表上创建索引 CREATE [UNIQUE | FULLTEXT | SPATIAL ] INDEX 索引名 ON 表名 (字段名[(长度)] [ASC |DESC]) ; #方法三:ALTER TABLE在已存在的表上创建索引 ALTER TABLE 表名 ADD [UNIQUE | FULLTEXT | SPATIAL ] INDEX 索引名 (字段名[(长度)] [ASC |DESC]) ; #删除索引:DROP INDEX 索引名 ON 表名字;
三、删除索引
drop index 索引名 on table;