第一部分:实用的一些命令
man –k
man –k xxx
同命令apropos 将搜索whatis数据库,模糊查找关键字如果记不清楚工具或者函数的完整名字,可以考虑用-k参数,例如,查找和printf有关的帮助:man -k printf
结合管道使用:
man –k xxx | grep xxx | grep 1
xxx代表要搜索的关键字,1这里是man手册的命令的区段,一共由8个。
数字"1":可执行命令或shell命令
数字"2":系统调用(functions provided by the kernel)
数字"3":C语言库函数
数字"4":设备或特殊文件(通常在/dev下)
数字"5":文件格式和规则(例如/etc/passwd)
数字"6":游戏
数字"7":杂项(宏、包及其他杂项)
数字"8":系统管理员相关的命令(通常只给root)
cheat
它提供显示Linux命令使用案例,包括该命令所有的选项和简短但尚可理解的功能。
例如:怎么使用ls这个命令呢?
Cheat ls
grep
(1)grep 搜索字符串 [filename]
(2)grep 正则表达式 [filename]
在文件中搜索所有 pattern 出现的位置, pattern 既可以是要搜索的字符串,也可以是一个正则表达式.
注意:在输入要搜索的字符串时最好使用双引号/而在模式匹配使用正则表达式时,注意使用单引号
grep的选项
-c 只输出匹配行的计数
-i 不区分大小写(用于单字符)
-n 显示匹配的行号
-v 不显示不包含匹配文本的所以有行
-s 不显示错误信息
-E 使用扩展正则表达式
-r 递归查找
第二部分:实用工具
Vim编辑器
打开Vim即默认进入普通模式,按i进入插入模式,按esc从插入模式退出普通模式,再按:进入命令行模式。
普通模式下游标的移动
|
按键 |
说明 |
|
H |
左 |
|
L |
右(小写L) |
|
J |
下 |
|
K |
上 |
|
W |
移动到下一个单词 |
|
B |
移动到上一个单词 |
普通模式进入插入模式的方式
命令 说明
i 在当前光标处进行编辑
I 在行首插入
A 在行末插入
a 在光标后插入编辑
o 在当前行后插入一个新行
O 在当前行前插入一个新行
cw 替换从光标所在位置后到一个单词结尾的字符
命令行模式退出的方式:
|
命令 |
说明 |
|
:q! |
强制退出,不保存 |
|
:wq! |
强制保存并退出 |
|
:w <文件路径> |
另存为 |
|
:wq |
保存并退出 |
普通模式下退出vim
普通模式下输入Shift+zz即可保存退出vim
补充
set nu 显示行号
:set ai 自动缩行
:set ts=4 设置一个 TAB 键等于几个空格
移动光标
[[ 转到上一个位于第一列的"{"
]] 转到下一个位于第一列的"{"
{ 转到上一个空行
} 转到下一个空行
gd 转到当前光标所指的局部变量的定义
gcc编译器
1.gcc 支持编译的一些源文件后缀名
|
后缀 |
源文件 |
|
.c |
C语言源文件 |
|
.i |
经过预处理后的C源文件 |
|
.s .S |
汇编语言源文件 |
|
.h |
预处理文件(头文件) |
|
.o |
目标文件 |
|
.a |
存档文件 |
gcc 编译程序的流程

预处理:gcc –E hello.c –o hello.i;gcc –E调用cpp
编 译:gcc –S hello.i –o hello.s;gcc –S调用ccl
汇 编:gcc –c hello.s –o hello.o;gcc -c 调用as
链 接:gcc hello.o –o hello ;gcc -o 调用ld
编译过程比较难记,我们简化一下,前三步,GCC的参数连起来是“ESc”,相应输入的文件的后缀是“iso”,这样记忆起来就容易多了
注意:
- Linux的可执行文件,只需向其分配x(可执行)权限即可 sudo chmod u+x excutefile
- 作为Linux程序员,我们可以让gcc在编译的任何阶段结束,以便检查或使用该阶段的输出(这个很重要)
2.体验:用gcc编译一个经典的hello
先使用Gvim编辑C语言代码,保存为hello.c
gcc 文件名 -o 名字(随便取的代替前者的名字,因为前者是C语言源文件) 编译./名字(刚刚随便取的名字) 执行

3.gcc的细分三步
$ gcc -E hello.c -o hello.i
首先gcc会调用预处理程序cpp,展开在源程序中定义的宏(上例:#include <stdio.h>)
hello.i这是一个经过预处理器处理之后的C源文件
gcc的-E参数可以让gcc在预处理结束后停止编译过程。
$ gcc -c hello.i -o hello.o
第二步,将hello.i编译为目标代码,gcc默认将.i文件看成是预处理后的C语言源代码,因此它会直接跳过预处理, 开始编译过程。
o文件它已经是二进制文件了
Tips:
- 请记住,gcc预处理源文件的时候(第一步),不会进行语法错误的检查
- 语法检查会在第二步进行,比如花括号不匹配、行末尾没有分号、关键字错误......
gcc hello.o -o hello
第三步,gcc连接器将目标文件链接为一个可执行文件,一个大致的编译流程结束
调试器gdb
启动gdb的方法有以下几种:
- gdb <program> program也就是执行文件,一般在当前目录下。
- gdb <program> core 用gdb同时调试一个运行程序和core文件,core是程序非法执行后,core dump后产生的文件。
- gdb <program> <PID> 如果程序是一个服务程序,那么可以指定这个服务程序运行时的进程ID。gdb会自动attach上去,并调试它。program应该在PATH环境变量中搜索得到。 gdb启动时,可以加上一些gdb的启动开关,详细的开关可以用gdb -help查看。下面只列举一些比较常用的参数: -symbols <file> -s <file> 从指定文件中读取符号表。 -se file 从指定文件中读取符号表信息,并把它用在可执行文件中。 -core <file> -c <file> 调试时core dump的core文件。 -directory <directory> -d <directory> 加入一个源文件的搜索路径。默认搜索路径是环境变量中PATH所定义的路径。
gdb programm(启动GDB)
b 设断点(要会设4种断点:行断点、函数断点、条件断点、临时断点)
run 开始运行程序
bt 打印函数调用堆栈
p 查看变量值
c 从当前断点继续运行到下一个断点
n 单步运行
s 单步运行
quit 退出GDB
-
-
- display 跟踪变量值的改变
- until 跳出循环
- finish 跳出函数
- help 帮助
-
文件管理器Makefile
Makefile的使用:
首先vim Makefile
Makefile的内容,一般写法:
test(目标文件): prog.o code.o(依赖文件列表)
tab(至少一个tab的位置) gcc prog.o code.o -o test(命令).......
例:
test: prog.o code.o
(这里是按tab键) gcc prog.o code.o -o test
prog.o: prog.c code.h
gcc -c prog.c -o prog.o
code.o: code.c code.h
gcc -c code.c -o code.o
clean:
rm -f *.o test
第二章
二进制数字系统和标准字符码
无符号(unsigned)编码基于传统的二进制表示法,表示大于或者等于零的数字。
补码(two’s-complement)编码是表示有符号整数的最常见的方式,有符号整数就是可以为正或者为负的数字。
浮点数(floating-point)编码是表示实数的科学记数法的以二为基数的版本。
地址
机器级程序将存储器视为一个非常大的字节数组,称为虚拟存储器(virtual memory)。存储器的每个字节都由一个唯一的数字来标识,称为它的地址 (address)。所有可能地址的集合称为虚拟地址空间(virtual address space)。
补充:指针的值表示某个对象的位置,指针的类型表示那个位置上所存储对象的类型(比如整数或者浮点数)。
十六进制表示法,十进制、二进制和十六进制表示之间进行转换
字
每台计算机都有一个字长(word size),指明整数和指针数据的标称大小(nominal size)。因为虚拟地址是以这样的一个字来编码的,所以字长决定的最重要 的系统参数就是虚拟地址空间的最大大小。也就是说,对于一个字长为w位的机器而言,虚拟地址的范围为0~2w-1,程序最多访问2w个字节。现在计算机多 为32和64位。
数据大小
计算机和编译器支持多种不同方式编码的数字格式,如整数和浮点数,以及其他长度的数字
C语言中数字数据类型的字节数
C声明 32位机器 64位机器
Cha 1 1
short int 2 2
int 4 4
long int 4 8
long long int 8 8
char * 4 8
float 4 4
double 8 8
寻址和字节顺序
按照从最高有效字节到最低有效字节的顺序存储。前一种规则—最低有效字节在最前面的方式,称为小端法。大端法与之相反。
强制类型转换(cast)
来允许以一种数据类型引用一个对象,而这种数据类型与创建这个对象时定义的数据类型不同。大多数应用编程都强烈不推荐这种编 码技巧,但是它们对系统级编程来说是非常有用,甚至是必需的
使用typedef命名数据类型
C语言中的typedef声明提供了一种给数据类型命名的方式。
使用printf格式化输出
printf函数(还有它的同类fprintf和sprintf)提供了一种打印信息的方式,这种方式对格式化细节有相当大的控制能力。第一个参数是格式串 (format string),而其余的参数都是要打印的值。在格式串里,每个以'%'开始的字符序列都表示如何格式化下一个参数。典型的示例 有:'%d'是输出一个十进制整数,'%f'是输出一个浮点数,而'%c'是输出一个字符,其编码由参数给出。
指针的创建和间接引用
C的“取地址”运算符&创建一个指针。在这三行中,表达式&x创建了一个指向保存变量x的位置的指针。这个指针的类型取决于x的类型,因此这三个指针的类型 分别为int*、float*和void**。(数据类型void*是一种特殊类型的指针,没有相关联的类型信息。)
表示字符串
C语言中字符串被编码为一个以null(其值为0)字符结尾的字符数组。每个字符都由某个标准编码来表示,最常见的是ASCII字符码。
ASCII字符集适合于编码英语文档,但是在表达一些特殊字符方面却没有太多办法,它完全不适合编码希腊语、俄语和中文这样语言的文档。近几年 ,开发出很 多方法来对不同语言的文字编码。Java编程语言使用Unicode来表示字符串。对于C语言也有支持Unicode的程序库。
表示代码
不同的机器类型使用不同的且不兼容的指令和编码方式。即使是完全一样的进程运行在不同的操作系统上也会有不同的编码规则,因此二进制代码是不兼容的。 二进制代码很少能在不同机器和操作系统组合之间移植。
布尔代数
与或非,取反运算。位运算。
C语言中的位级运算
确定一个位级表达式的结果最好的方法,就是将十六进制的参数扩展成二进制表示并执行二进制运算,然后再转换回十六进制
掩码:某一位置为一,表示信号i有效,0则为信号i是被屏蔽的。
位级运算的一个常见用法就是实现掩码运算,这里掩码是一个位模式,表示从一个字中选出的位的集合。让我们来看一个例子,掩码0xFF(最低的8位为1)表 示一个字的低位字节。位级运算x&0xFF生成一个由x的最低有效字节组成的值,而其他的字节就被置为0。比如,对于x=0x89ABCDEF,其表达式将得到 0x000000EF。表达式~0将生成一个全1的掩码,不管机器的字大小是多少。尽管对于一个32位机器来说,同样的掩码可以写成0xFFFFFFFF,但是这样 的代码不是可移植的。
C语言中的逻辑运算
C语言还提供了一组逻辑运算符 ||、&&和!,分别对应于命题逻辑中的OR、AND和NOT运算。
C语言中的移位运算
C语言还提供了一组移位运算,以便向左或者向右移动位模式。对于无符号数据(也就是以限定词unsigned声明的整型对象),右移必须是逻辑的。而对于有符号数 据(默认的声明的整型对象),算术的或者逻辑的右移都可以。
与移位运算有关的操作符优先级问题
常常有人会写这样的表达式1<<2+3<<4,其本意是(1<<2)+(3<<4)。但是在C语言中,前面的表达式等价于1<<(2+3)<<4,这是由于加法(和减法)的优先 级比移位运算要高。然后,按照从左至右结合性规则,括号应该是这样打的(1<<(2+3))<<4,因此得到的结果是512,而不是期望的52。
整型数据类型
C、C++和Java中的有符号和无符号数C和C++都支持有符号(默认)和无符号数。Java只支持有符号数。
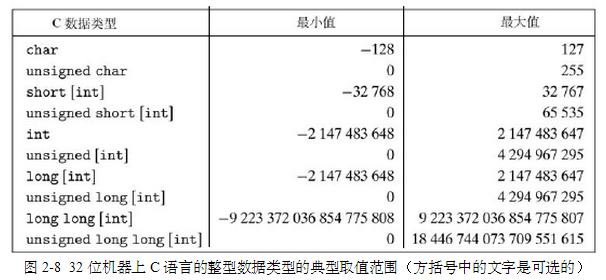
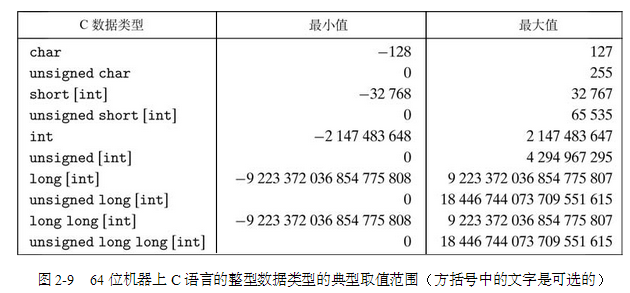
无符号数的编码
补码编码
利用补码可以把数学运算统一成加法,只要一个加法器就可以实现所有的数学运算。
有符号数还有两种标准的表示方法:
反码(Ones’ Complement):除了最高有效位的权是-(2w-1-1)而不是-2w-1,它和补码是一样的。
原码(Sign-Magnitude):最高有效位是符号位,用来确定剩下的位应该取负权还是正权。
有符号数和无符号数之间的转换
函数U2T描述了从无符号数到补码的转换,而T2U描述的是补码到无符号的转换。这两个函数描述了在大多数C语言实现中这两种数据类型之间的强制类型转换效果。
C语言中的有符号数和无符号数
由于C语言对同时包含有符号和无符号数表达式的这种处理方式,出现了一些奇特的行为。当执行一个运算时,如果它的一个运算数是有符号的而另一个是无符号 的,那么C语言会隐式地将有符号参数强制类型转换为无符号数,并假设这两个数都是非负的,来执行这个运算。就像我们将要看到的,这种方法对于标准的算术 运算来说并无多大差异。
扩展一个数字的位表示
把short转换成unsigned时,我们先要改变大小,之后再完成从有符号到无符号的转换。也就是说(unsigned)sx等价于(unsigned)(int)sx,求值得 到4 294 954 951,而不等价于(unsigned)(unsigned short)sx,后者求值得到53 191。事实上,这个规则是C语言标准要求的。
无符号加法
无符号加法等价于计算和模上2w。可以通过简单的丢弃x + y的w + 1位表示的最高位,来计算这个数值。比如,考虑一个4位数字表示,x = 9和y = 12的位表示 分别为[1001]和[1100]。它们的和是21,5位的表示为[10101]。但是如果丢弃最
高位,我们就得到[0101],也就是十进制值的5。这就和值21 mod 16 = 5一致。
补码加法
定义z为整数和z =4 x + y,z'为 z' = 4z mod 2w,而z''为z'' =U2Tw(z')。数值z''等于x +wt
y。我们分成4种情况分析,
1) -2w ≤z < -2w-1。然后,我们会有z' = z + 2w。这就得出0≤z'<-2w-1+2w=2w-1。检查等式(2-8),我们看到z'在满足z'' = z'的范围之内。这种情况称为负溢出(negative overflow)。我们将两个负数x和y相加(这是我们能得到z < -2w-1的唯一方式),得到一个非负的结果z'' = x + y + 2w。
2)-2w-1≤z < 0。那么,我们又将有z'= z + 2w,得到-2w-1+2w=2w-1≤z' < 2w。检查等式(2-8),我们看到z'在满足z'' = -2w的范围之内,因此z'' = z'-2w = z + 2w-2w = z。也就是说,我们的补码和z''等于整数和x + y。
3)0≤z<2w-1。那么,我们将有z' = z,得到0≤z' < 2w-1,因此z'' = z' = z。补码和z''又等于整数和x + y。
4)2w-1≤z<2w。我们又将有z' = z,得到2w-1≤z' < 2w。但是在这个范围内,我们有z'' = z'-2w,得到z''= x + y -2w。这种情况称为正溢出(positive overflow)。
无符号乘法
因此,w位无符号乘法运算* wu的结果为:
x * wu y=(x·y) mod 2w
补码乘法
w位的补码乘法运算* w t 的结果为:x * w t y = U2Tw((x · y) mod 2w)
二进制小数
IEEE浮点数表示
IEEE浮点标准用V = (-1)s × M × 2E的形式来表示一个数:
• 符号(sign) s决定这个数是负数(s=1)还是正数(s=0),而对于数值0的符号位解释作为特殊情况处理。
• 尾数(significand) M是一个二进制小数,它的范围是1~2-ε,或者是0~1-ε。• 阶码(exponent) E的作用是对浮点数加权,这个权重是2的E次幂 (可能是负数)。将浮点数的位表示划分为三个字段,分别对这些值进行编码:
• 一个单独的符号位s直接编码符号s。
• k位的阶码字段exp = ek-1…e1e0编码阶码E。
• n位小数字段frac = fn-1…f1 f0编码尾数M,但是编码出来的值也依赖于阶码字段的值是否等于0。
情况1:规格化的值 这是最普遍的情况。当exp的位模式既不全为0(数值0),也不全为1(单精度数值为55,双精度数值为2047)时,都属于这类情 况。在这种情况中,阶码字段被解释为以偏置(biased)形式表示的有符号整数。也就是说,阶码的值是E = e-Bias,其中e是无符号数,其位表示为ek -1…e1e0,而Bias是一个等于2k-1-1(单精度是127,双精度是1023)的偏置值。由此产生指数的取值范围,对于单精度是-126~+127,而 对于双精度是-1022~+1023。
情况2:非规格化的值
当阶码域为全0时,所表示的数就是非规格化形式。在这种情况下,阶码值是E = 1 - Bias,而尾数的值是M = f,也就是小数字段的值,不包含隐含 的开头的1
情况3:特殊值
最后一类数值是当指阶码全为1的时候出现的。当小数域全为0时,得到的值表示无穷,当s = 0 时是+∞,或者当 s = 1时是-∞。
舍入
向偶数舍入,向零舍入,向下舍入,向上舍入。
第三章
X86 寻址方式经历三代:
1 DOS时代的平坦模式,不区分用户空间和内核空间,很不安全
2 8086的分段模式
3 IA32的带保护模式的平坦模式
ISA
指令集体系结构,机器级程序的指令和格式。它定义了处理状态,指令的格式,以及每条指令对状态的影响。
获得汇编代码的两种方式:
gcc -S xxx.c -o xxx.s 获得汇编代码,也可以用objdump -d xxx 反汇编
(反汇编不需要访问程序的源代码或者汇编代码)
C语言数据类型在IA32中的大小:
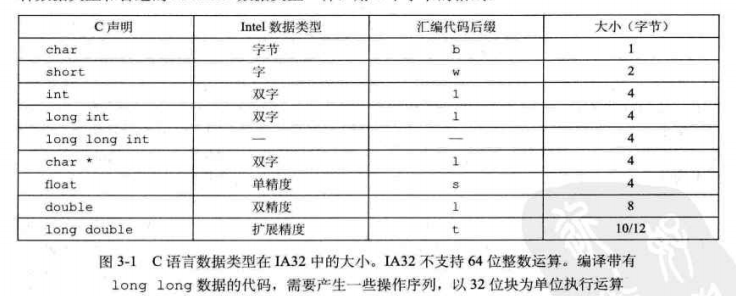
8个寄存器(32位):
eax,ecx,edxe;bx,esi,edi为六个通用寄存器。
esi edi可以用来操纵数组
ebp(帧指针),esp(栈指针)保存指向程序栈中重要位置的指针。
立即数,存储器,寄存器寻址方式:
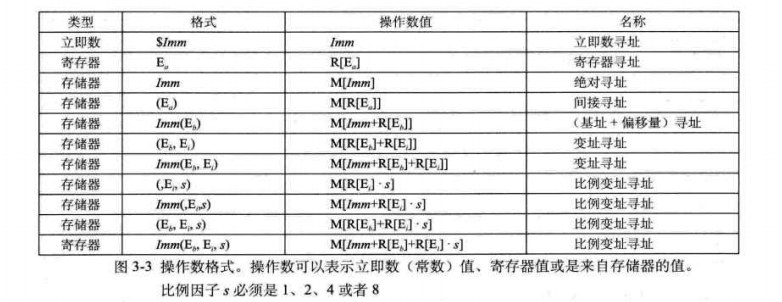
特别是:有效地址的计算方式 Imm(Eb,Ei,s) = Imm + R[Eb] + R[Ei]*s
数据传送指令:
MOV:movb,movw,movl分别传送字节,字,双字
MOVZ(零扩展,高位用0填充):同上,压栈出栈见p114表格。(注意栈顶的地址值是栈中最小的)
MOVS(符号扩展,高位用原来最高位的数值填充):同上
C语言中,指针就是地址,间接引用指针就是将指针放在一个寄存器中,然后在存储器中使用这个寄存器。
算术运算和逻辑运算:
四种整数操作:加载有效地址,一元操作,二元操作,移位。
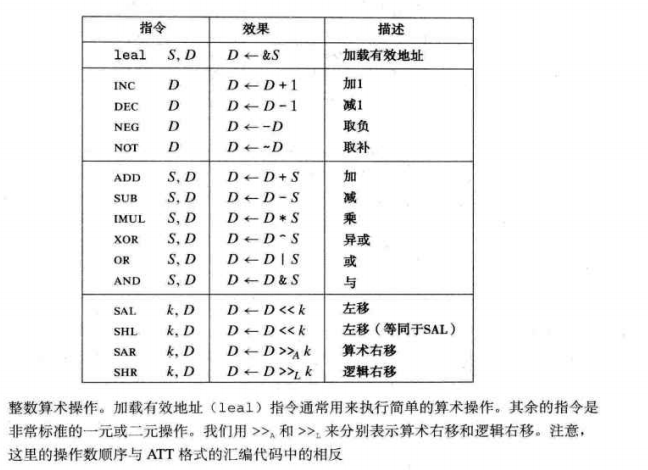
控制:
核心是跳转语句。
无条件跳转:jmp跳转目标可以是直接跳转,即跳转目标是作为指令的一部分编码;也可以是间接跳转,目标是从寄存器或存储器中读出的。
条件跳转:判断条件:标志位p124页。跳转指令,p128.
CMP是不会改变源操作数的减法,只是做比较之后改变标志位。
SUB是会改变源操作数的减法。
循环
if-else 的汇编结构:

do-while的汇编结构:

While的汇编结构:

for的汇编结构:


过程:
栈:栈顶指针,%esp。在汇编语言中,执行子程序之前,要将该跳转指令下一条指令的地址压入栈中保护起来,在子程序执行完了之后出栈,保证可以继续执行主 程序。
Call指令将控制转移到一个函数的开始,ret指令返回到call指令后的下一条指令。
第四章
ISA
指令集体系统结构:一个处理器支持的指令和指令的字节级编码。
不同的处理器家族有不同的ISA。
Y86
本章定义的一个简单的指令集。包括各种状态元素、指令和它们的编码、一组编程规范和异常事件处理。
Y86处理器
以顺序指令执行为基础,设计了一个流水化的处理器。将每条指令分成5步,每个步骤都由一个独立的硬件部分或者阶段来处理。每个时钟周期有新的指令进入流水 线,即说该处理器可以同时执行5条指令的不同阶段。(重点在于如何处理冒险冲突的情况。数电,EDA中的概念)
4.1.1 程序员可见状态
即:Y86程序中每条指令都会读取或者修改处理器状态的某些部分的状态。
帮助理解 程序员:用汇编代码写程序的人,产生机器代码的编译器。
具体内容 8个程序寄存器(与IA32 一样),3个条件码(ZF,SF,OF)。PC程序计数器存放当前正在执行指令的地址。存储器,很大的字节组,保存着程序和 数据。状态码Stat,表明程序的总体状态。 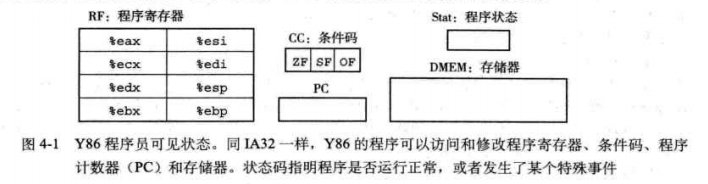
4.1.2 Y86指令
背景知识:一条指令含有一个单字节的指令指示符。可能含有一个单字节的寄存器指示符,还可能含有一个四字节的常数字。字段fn说明是 某个整数操作opl,数据移动 条件comvXX,分支条件Jxx。

movl指令:
irmovl , rrmovl , mrmovl , rmmovl .
i:立即数r:寄存器m:存储器。
第一个字母代表源操作数,第二个字符代表目的操作数。
注意:有存储器寻址参与的两种movl指令,采用基址和偏移量形式。不支持第二变址寄存器和任何寄存器值得伸缩。
4.1.3指令编码
每条指令的第一个字节:
高四位0~B表示,是代码部分。手工对指令编码时参照p232页的表格。注意rrmovl和cmovXX取值一样。
低四位是功能部分。除了opl,jXX,cmovXX以外全为0.这三者的指令对应的值,参照p233页的图。
附加部分:
寄存器指示符:参照p234页的表格,对应的寄存器的编号。
4字节的常数字(这个部分采用小端法):
- irmovl中的立即数数据
- mmovl,mrmovl中存储器m地址指示符的偏移量
- 分支指令jXX的目的地址(绝对地址)
- 调用指令call的目的地址(绝对地址)
根本前提:字节编码和指令序列是一一对应的。
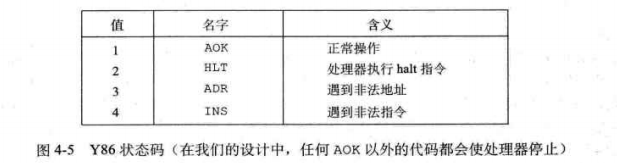
4.1.4Y86异常
使用状态码stat描述。一共有四种取值。(见p237)在Y86中除了等于1以外的其他情况,都会使处理器停止(在IA32或者更完整设计的ISA中,都会调用一个 异常处理程序但这个是简化版咯。)
4.2逻辑设计
这部分与以前学习过的电子电路,数字电路,EDA关联性非常大。
前提知识点:
*逻辑1是用1V左右的高电压表示的。
*逻辑0使用0V左右的低电压表示的。
*实现一个数字系统:计算对位进行操作的函数的组合逻辑、存储位的存储器元件、控制存储器元件更新的时钟信号。
4.2.1逻辑门:
只对单个位的数进行操作,而不是整个字。
与:&& 或: || 非: !
4.2.2组合电路:
很多逻辑门组合成一个网构建的计算块。(注意两个或多个输出不能连接在一起,并且无环。)
4.2.3字级的组合电路和HCL整数表达式
例如:bool eq=(A==B);
在HCL硬件描述语言中,每个字都可以声明为特定的位数。允许描述自是否相等。输出eq表示AB是否相等。
画字级电路的时候,实线表示携带字的每个位的线路,虚线表示布尔信号的结果。
多路复用函数使用情况表达式描述:
[
Select:expr
]
Select代表什么时候选择这种情况
Expr表示该种情况得到的数值
注意:顺序执行,第一个求值为1 的情况会被选中。一般最后一个表达式是 1:expr。表示的意思是前面所有情况都没有选中,就执行最后这个。
例如:
Int out=[
S&&q :a
S&&w:b
1 :c
]
算术逻辑单元:
两部分组成:数据输入,控制输入。
控制输入代表不同的算术或逻辑操作。
0:+
1:-
2:&
3:^
4.2.5存储器和时钟
时钟寄存器:(硬件寄存器)存储单个位或字。时钟信号控制寄存器加载输入值。
随机访问存储器(存储器)存储字,用地址来选择该读或该写那个字。
4.3Y86的顺序实现
处理指令阶段化:
取值、译码(从寄存器读入最多两个操作数)、执行、访存(写入,读出存储器)、写回(写最多两个结果到寄存器)、更新PC(设置为下一条指令的地址)。
取值:valC四字节常数字valP下一条指令的地址。
译码:从寄存器读入的数valA,valB.
执行:计算出的值valE.
访存:从存储器读出的值valM.
写回:写入寄存器的结果。
更新PC
SEQ硬件结构:
计算中不一样的地方:
四个寄存器的ID信号:srcA,valA的源;srcB,valB的源;dstE,写入valE的寄存器;dstM,写入valM的寄存器。
SEQ的时序:
需要时序控制的控制的四个硬件:程序计数器、条件码寄存器、数据寄存器、寄存器文件。
它们的值要等时钟信号(上升沿或者下降沿来临时才改变)。
SEQ阶段的实现:
取值:第一个字节Split:由icode和ifun组成。Align:一字节的寄存器指示符和四字节的常数字。
译码和回写:读、写端口都有一个地址连接(寄存器ID)和数据连接(寄存器文件的输出、入字)。
执行阶段
访存阶段更新PC
第六章存储器层次结构
6.1存储技术
6.1.1随机访问存储器(分成两类)
静态RAM(SRAM):快,作为高速缓存存储器。(几百几千兆)
动态RAM(DRAM):作为主存,图形系统的帧缓冲区。(<=几兆)
非易失性存储器
(SRAM,DRAM都是易失性存储器。)
非易失性:断电后不会丢失信息。
ROM:只读存储器(read-only memory)它有的类型既能读也能写,历史原因这样称呼它。
ROM分类:(依据 能被重新编程,写的次数 和 编程所用的机制)
PROM:只能被编程一次。
可擦写可编程ROM(EPROM):被编程105次
闪存:基于EEPROM,为大量的电子设备提供快速持久的非易失性存储。
固件:存储在ROM设备中的程序。
7.访问主存
总线是一组并行的导线,能够携带地址,数据和控制信号。
CPU与主存之间的数据传送:通过总线的共享电子电路在处理器和DRAM主存来回往返。
总线事务:读事务(主存传送数据到CPU,即cpu从主存读)、写事务(CPU传送到主存)
磁盘存储
大,但是慢。DRAM快10万倍,SRAM快100万倍。
扇区:存储等数量的数据位。
间隙:存储标识扇区的格式化位。
柱面:半径距离相等的磁道的集合。
磁盘容量
磁盘容量:磁盘最大容量。
磁盘容量=每个扇区字节数*每个磁道平均扇区数*每个表面的磁道数*每个盘面的表面数*磁盘的总盘面数
(注意:DRAM,SRAM容量:K=210,M=220,G=230,T=240
然而磁盘,I/O设备的容量:K=103,,M=106,G=109,T=1012.但是很好一点是,两者对应的值相对差很小。)
磁盘操作
寻道时间:读写头定位到磁道上的时间。通常:3~9ms
旋转时间:到了磁道,等待目标扇区的时间。最大旋转延迟:
Tmax rotation=1/RPM * 60secs/1min
平均旋转时间(延迟):最大的一半。
传送时间:驱动器读写内容所花时间。
Tavg transfer=Tmax rotation * 1/每个磁道平均扇区数
计算小结:
时间主要花在寻道和旋转延迟上。
寻道时间和旋转延迟大致相等,一般直接寻道时间*2。
6.2局部性
局部性原理:程序倾向于引用邻近最近引用过的数据项或者就是数据项本身。
时间局部性:存储器位置多次被引用。
空间局部性:存储器位置附近的位置在不远的将来被引用。
6.2.1对程序数据引用的局部性
步长为一的引用的模式为顺序引用模式。每隔K个元素进行访问,称为步长为K的引用模式。
6.2.2对指令的局部性
循环体具有良好的时间和空间局部性
6.2.3局部性规律总结
重复引用同一个变量的程序具有良好的时间局部性
对于步长为K的引用模式,K越小,空间局部性越好。
对于取指令,循环具有良好的时间和空间局部性。循环体越小,循环迭代次数越多,局部性越好。
存储器层次结构
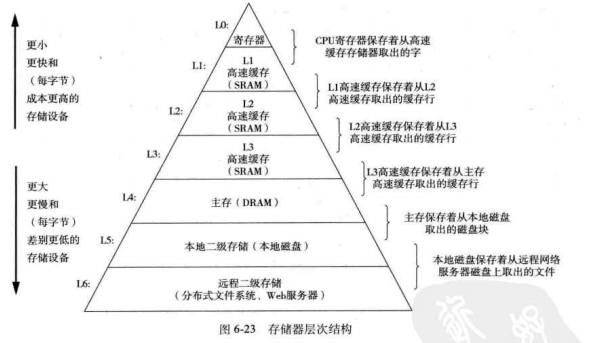
6.3.1存储器层次结构中的缓存
高速缓存:下一层(对它本身来说更大更慢的设备)的缓冲区域。使用高速缓存的过程叫做缓存。
存储器结构层次的中心思想:层次结构中的每一层都缓存来自较低一蹭的数据对象。
1.缓存命中
程序需要K+1层的数据对象d,并且d刚好在K层的一个块中。
2.缓存不命中
与缓存命中相反。
3.缓存不命中的种类
强制性不命中(冷不命中):上一层缓存是空的导致的不命中。
放置策略 :
高层的缓存(靠近CPU)使用的昂贵代价高版:
允许K+1层的任何块放在K层的任何块中
严格版:
K+1层的某个块限制放置在K层的某个块中。
冲突不命中:缓存够大,由于严格的放置策略会使K+1层不同对象映射到K层同一个块引起的不命中。
容量不命中:缓存不够大引起的不命中。
6.4高速缓存存储器
通用的高速缓存存储器结构
存储器地址:m位
高速缓存组:S=2S位
每组E行高速缓存行
每行1个B=2b字节的数据块
一个有效位:这个行是否有意义
标记位:t=m-(b+s):唯一标识高速缓存行的块
高速缓存大小C=S*E*B
高速缓存的地址:
首先组索引,确定是哪一个组,再是标记位,确定哪一行,最后块偏移。
t位:标记
s位:组索引
b位:块偏移
插入图10
6.4.2直接映射高速缓存
高速缓存的分类依据:每个组的行数。每组一行的高速缓存,称为直接映射高速缓存。
1.直接映射高速缓存中的 组选择
抽取目标地址的对应的S位组索引位。
2.直接映射高速缓存中的 行匹配
有效位&&t位标记位和目标地址的标记匹配 同时为真 则命中
不命中时 处理方法:行替换
先从下一层取出被请求的块,再在块中组索引,再行匹配(同时有效的话,就可以确认是这个对象了)。由于直接映射高速缓存每组只有一行,所以只需要 将新的行替换当前行就行了。
3.直接映射高速缓存中的 字选择
块偏移提供的是所需要的字的第一个字节的偏移。如例子:
插入图12
4.综合
描述高速缓存结构:(S,E,B,m)
不同的块被映射到同一组,是靠标记位来区分
6.4.3组相联高速缓存
由于直接映射高速缓存有冲突不命中的问题,所以放宽了每组只有一行的限制。1<E<C/B的高速缓存称为 组相联高速缓存。
1.组选择(和直接映射高速缓存一样)
2.行匹配和字选择(基本一样,只是多搜索几个行)
3.组相联高速缓存不命中时的行替换
替换哪一行:1.随机替换
2.利用局部性原理,替换被引用概率最小的行(例如最不常使用,最近很少使用的行)
6.4.4全相联高速缓存
只有一个组,这个组里包含所有高速缓存行。
1.组选择。只有一个组,所以没有组索引S=0.地址只有标记和块偏移两部分
2.行匹配字选择。同组相联高速缓存一样。
总结:
Linux入门,主要要掌握shell命令,不会使用时用man查。其他重点掌握命令:cheat,find,grep.
重要工具:vim,gcc,gdb,makefile.静态库,动态库的创建,正则表达式的实际运用,计算机基础,无符号,有符号,浮点数,位运算,逻辑运算,小端法大端法,计算机将加减都处理成加法的补码。进制转换,整数与浮点数的转换。
汇编代码,寄存器,寻址方式,传送、跳转指令,if-else do-while,while,for,switch的汇编结构,栈帧结构。
硬件语言时序结构,组合结构。
存储器层次结构,存储层次结构的中心思想,磁盘操作时间花费,局部性原理,缓存不命中时的解决策略。
不足:
到目前为止,最困难的部分是还是入门的时候。最开始学习shell的命令的时候,想要把每一个出现过的命令都记下来,因为知道这些以后都会使用,这种想法并不适合内容多,强度大的学习。后来调整了心态,先了解框架,再一步一步地填充,不会的部分先跳过,接着往下学,最后再汇总所有的不懂的部分,自己解决,解决不了再提问。然而由于很多时候我总是抵着deadline完成任务,往往是每周二晚上满满疑问无处解答,第二天只能再带着疑问去考试。问题还是应该早发现早解决。
但毫无疑问的是,我现在的学习状态比刚开学做12个实验的那一周好太多了。那个时候效率不高学习起来也很烦躁,我也是学了20多个小时的人之一。学习真的是一个有趣的过程,学得越认真,基础越扎实,往后效率就越高。特别是遇到以前学得特别起劲的汇编时,想着,计算机的课程的门门相通,这里没有学懂,这笔账就会一直欠着,以后遇到这个部分又会吃力。所以学习还是要对得起自己。从来没想过要抄谁的作业,抄谁的考试,我很感谢一直抱着这样想法的自己。虽然现在还是有很多不足,很多不明白的地方,但是我肯定会接着,不欺骗自己地接着学下去。
参考资料:
man详细介绍http://www.cnblogs.com/chengmo/archive/2010/10/26/1861809.html
man总结http://blog.csdn.net/losophy/article/details/7961958
cheat https://linux.cn/article-3760-1.html#3_10384
grep http://www.cnblogs.com/end/archive/2012/02/21/2360965.htm
自己的学习总结
《深入理解计算机系统》