舆情分析项目
1、分析事件:重庆公交坠江原因
2、分析对象:
(1)网友评论(初级分类-分词匹配;高级分类-自然语言识别,映射人类情感和意图,比如:积极、消极、无奈、讽刺、建设、谩骂、理性分析、事后、和事佬等)
(2)评论者的公网IP(依据公网IP识别不同地域的网络用户,对本次事件的关注度)
(3)评论者的省份属性(同上)
3、数据来源:
新浪评论:http://comment5.news.sina.com.cn/comment/skin/default.html?channel=gn&newsid=comos-hnfikve6671738&group=0
4、其他:
准备数据:(直接用:中国省份数据库,世界国家名称数据库)参考本人博客
(1)中国的行政区划数据,包括全国的省、市、县(参考csdn、民政部官网)
(2)世界的国家数据(参考csdn)
(一)舆情分析项目之数据准备:采集评论数据
1、采集字段
三个字段:评论、IP、省份
其他字段:收到点赞数等等
2、Python实现数据采集
文件结构
(1)python主代码
01-busremark.py中
import json
import requests
import pymysql
import time as timeimport
from mylog import Logger
logger1 = Logger(logfile='log1.log', logname="log1", logformat=1).getlog() # 使用自定义日志对象
# 连接数据库
connect = pymysql.Connect(
host='localhost',
port=3306,
user='root',
passwd='root',
db='analyze',
charset='utf8'
)
# 获取游标
cursor = connect.cursor()
# 创建数据库语句
for page_num in range(1, 6001): # 从1采集到6000条评论
if page_num % 50 == 0: # 每采集50条数据,休息2秒
timeimport.sleep(2)
url = "http://comment5.news.sina.com.cn/page/info?version=1&format=js&channel=gn&newsid=comos-hnfikve6671738&group=0&compress=0&ie=utf8&oe=utf8&page=" + str(
page_num) + "&page_size=1&jsvar=loader_1541133929419_28637561"
# url = "http://comment5.news.sina.com.cn/page/info?version=1&format=js&channel=gn&newsid=comos-hnfikve6671738&group=0&compress=0&ie=gbk&oe=gbk&page=1&page_size=2&jsvar=loader_1541133929419_28637561"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'
}
try: # 尝试采集
# 发出请求获取响应
response = requests.get(url, headers=headers)
data_str = response.content.decode('unicode_escape')
# 排除干扰字符串
data_str = data_str.lstrip("var loader_1541133929419_28637561=")
# print(data_str)
# str转字典
data_dict = json.loads(data_str)
print(type(data_dict))
# 获取每次响应中的所有评论
all_remarks = data_dict['result']['cmntlist']
print(len(all_remarks))
i = 0
for c in all_remarks: # 遍历每次响应中的评论,并存入mysql
i += 1
print(i, "*" * 100)
nick = c["nick"] # 昵称
content = c["content"] # 评论
agree = int(c["agree"]) # 收到点赞
area = c["area"] # 地区
ip = c["ip"] # 源ip
time = c["time"] # 评论发布时间
profile_img = c["profile_img"] # 头像
print(nick)
print(content)
print(agree)
print(ip)
print(time)
print(profile_img)
# sql操作
# 增加数据操作
sql_1 = "insert into all_remarks(nick, content, agree, area, ip, time, profile_img) values(%s,%s,%s,%s,%s,%s,%s)"
data = (nick, content, agree, area, ip, time, profile_img)
cursor.execute(sql_1, data) # 生成增加sql语句
connect.commit() # 确认永久执行增加
except Exception as e: # 采集异常处理
my_e = str(e) + " ==> " + str(url)
logger1.warning(my_e) # 定义调试日志内容
# print(my_e)
continue # 忽视异常,进行后面的采集
(2)python日志
mylog.py中
# 开发一个日志系统, 既要把日志输出到控制台, 还要写入日志文件
import logging
# 用字典保存输出格式
format_dict = {
1: logging.Formatter('%(asctime)s - %(name)s - %(filename)s - %(levelname)s - %(message)s'),
2: logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s'),
3: logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s'),
4: logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s'),
5: logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
}
class Logger():
def __init__(self, logfile, logname, logformat):
'''
指定保存日志的文件路径,日志级别,以及调用文件
将日志存入到指定的文件中
'''
# 创建一个logger
self.logger = logging.getLogger(logname)
self.logger.setLevel(logging.DEBUG)
# 创建一个handler,用于写入日志文件
fh = logging.FileHandler(logfile)
fh.setLevel(logging.DEBUG)
# 再创建一个handler,用于输出到控制台
ch = logging.StreamHandler()
ch.setLevel(logging.DEBUG)
# 定义handler的输出格式
# formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
formatter = format_dict[int(logformat)]
fh.setFormatter(formatter)
ch.setFormatter(formatter)
# 给logger添加handler
self.logger.addHandler(fh)
self.logger.addHandler(ch)
def getlog(self):
return self.logger
if __name__ == '__main__':
logger1 = Logger(logfile='log1.txt', logname="fox1", logformat=1).getlog()
logger1.debug('i am debug')
logger1.info('i am info')
logger1.warning('i am warning')
logger2 = Logger(logfile='log2.txt', logname="fox2", logformat=2).getlog()
logger2.debug('i am debug2')
logger2.info('i am info2')
logger2.warning('i am warning2')
3、sql建表语句
/* Navicat MySQL Data Transfer Source Server : win7_local Source Server Version : 50717 Source Host : localhost:3306 Source Database : analyze Target Server Type : MYSQL Target Server Version : 50717 File Encoding : 65001 Date: 2018-11-06 19:33:57 */ SET FOREIGN_KEY_CHECKS=0; -- ---------------------------- -- Table structure for all_remarks -- ---------------------------- DROP TABLE IF EXISTS `all_remarks`; CREATE TABLE `all_remarks` ( `id` int(11) unsigned NOT NULL AUTO_INCREMENT, `nick` varchar(255) DEFAULT NULL, `content` text, `agree` int(10) DEFAULT NULL, `area` varchar(100) DEFAULT NULL, `ip` varchar(20) DEFAULT NULL, `time` datetime DEFAULT NULL ON UPDATE CURRENT_TIMESTAMP, `profile_img` varchar(255) DEFAULT NULL, `province_brief` varchar(20) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
4、效果截图
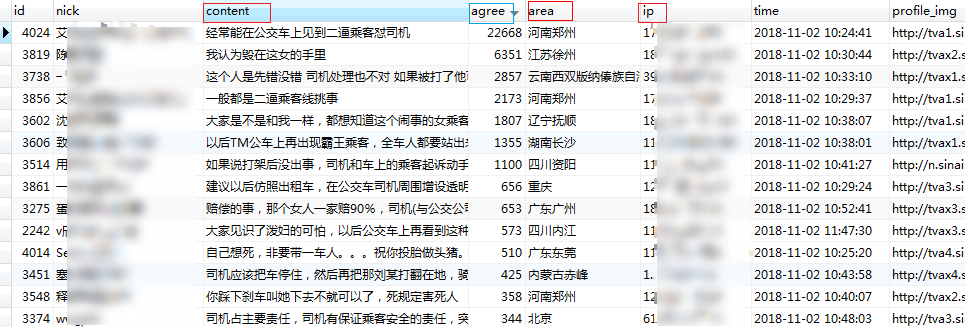
中途在添加了字段
02-mysql_to_province_country.py
import pymysql
# 连接数据库
connect = pymysql.connect(
host='localhost',
port=3306,
user='root',
passwd='root',
db='analyze',
charset='utf8'
)
# 获取游标
cursor = connect.cursor()
# 获取中国所有的省份二字简称
sql_2 = "select brief from tb_provinces"
ret_num2 = cursor.execute(sql_2) # 生成查询sql语句,并且执行。ret_num表示受影响的记录条数
pro_data = cursor.fetchall() # 获取查询结果
# 取出所有省份直辖市等列表
pro_list = []
for pro in pro_data:
pro_list.append(pro[0])
print(pro_list)
# 获取国家名称列表
sql_get_country = "select country from tb_countries"
ret_num_cou = cursor.execute(sql_get_country)
countries = cursor.fetchall()
# print(countries)
# 取出所有国家名称列表
countries_list = []
for country in countries:
countries_list.append(country[0])
print(countries_list)
print(len(countries_list))
# 循环给每条记录打省份标签
for i in range(1, 2000):
# 查询数据操作(只有查询用的全是游标,其他3种操作,要用连接的提交commit)
sql_1 = "select id,area,province_brief from all_remarks where province_brief is null or province_brief='' limit 1"
# sql_1 = "select id,area,province_brief from all_remarks limit 1"
ret_num = cursor.execute(sql_1) # 生成查询sql语句,并且执行。ret_num表示受影响的记录条数
if ret_num < 1: # 没有获取到数据库任何结果,终止本次任务
break
data = cursor.fetchall() # 获取查询结果
print(data)
# 数据准备
id = data[0][0] # id
location = data[0][1] # 地理位置详情
# print(location)
# 判断归属省份
for pro in pro_list:
if pro in location:
# print(pro)
province_brief = pro
# 修改数据操作
sql_3 = "update all_remarks set province_brief=%s where id=%s"
data = (pro, id)
cursor.execute(sql_3, data) # 生成增加sql语句
connect.commit() # 确认永久执行增加
# print("执行完毕")
break
else: # 上面循环完成,没有匹配到对应省份时
print("id=%s,不属于任何省份" % id)
print("开始判断属于哪个国家")
for country in countries_list:
if country in location:
# print(country)
# 修改数据操作
sql_4 = "update all_remarks set province_brief=%s where id=%s"
data = (country, id)
cursor.execute(sql_4, data) # 生成增加sql语句
connect.commit() # 确认永久执行增加
print("id=%s ,属于 %s" % (id, country))
break
else: # 上面循环完成,没有匹配到对应国家时
print("位置异常,没有匹配到任何省份和国家:%s" % location)
# 关闭指针
cursor.close()
# 关闭连接
connect.close()
03-matplotlib_provinc_count.py
import pymysql
import matplotlib.pyplot as plt
import matplotlib # 载入matplotlib完整库
matplotlib.rcParams['font.family'] = 'Microsoft Yahei' # 字体,改为微软雅黑,默认 sans-serif
matplotlib.rcParams['font.size'] = 18 # 字体大小,整数字号,默认10
# 连接数据库
connect = pymysql.connect(
host='localhost',
port=3306,
user='root',
passwd='root',
db='analyze',
charset='utf8'
)
# 获取游标
cursor = connect.cursor()
# 获取数据
sql_1 = "select province_brief,count_id from stst_count_province"
ret_num2 = cursor.execute(sql_1) # 生成查询sql语句,并且执行。ret_num表示受影响的记录条数
pro_data = cursor.fetchall() # 获取查询结果
# print(pro_data)
# 按照count_id 降序排列
list1 = list(pro_data)
# print(list1)
list2 = sorted(list1, key=lambda p: p[1], reverse=True)
print(list2)
# 关闭指针
cursor.close()
# 关闭连接
connect.close()
# 绘图
# 导入待绘图处理数据
base_data = list2
# 获取数据
province_list = [x[0] for x in base_data]
count_id_list = [x[1] for x in base_data]
print(province_list)
print(count_id_list)
# 设置x,y
x = [i for i in range(len(province_list))]
y = count_id_list
plt.figure(figsize=(20, 10), dpi=80)
plt.bar(
x,
y,
width=0.5,
color='r'
)
# 设置x轴刻度
_xticks_labels = [str(index + 1) + " " + value for index, value in enumerate(province_list)]
plt.xticks(x, _xticks_labels, rotation=40, fontsize=12)
# 设置y轴刻度
# y_new = [i for i in range(0, 701)][::50]
# plt.yticks(y_new)
# 设置网格
plt.grid()
# 设置文字
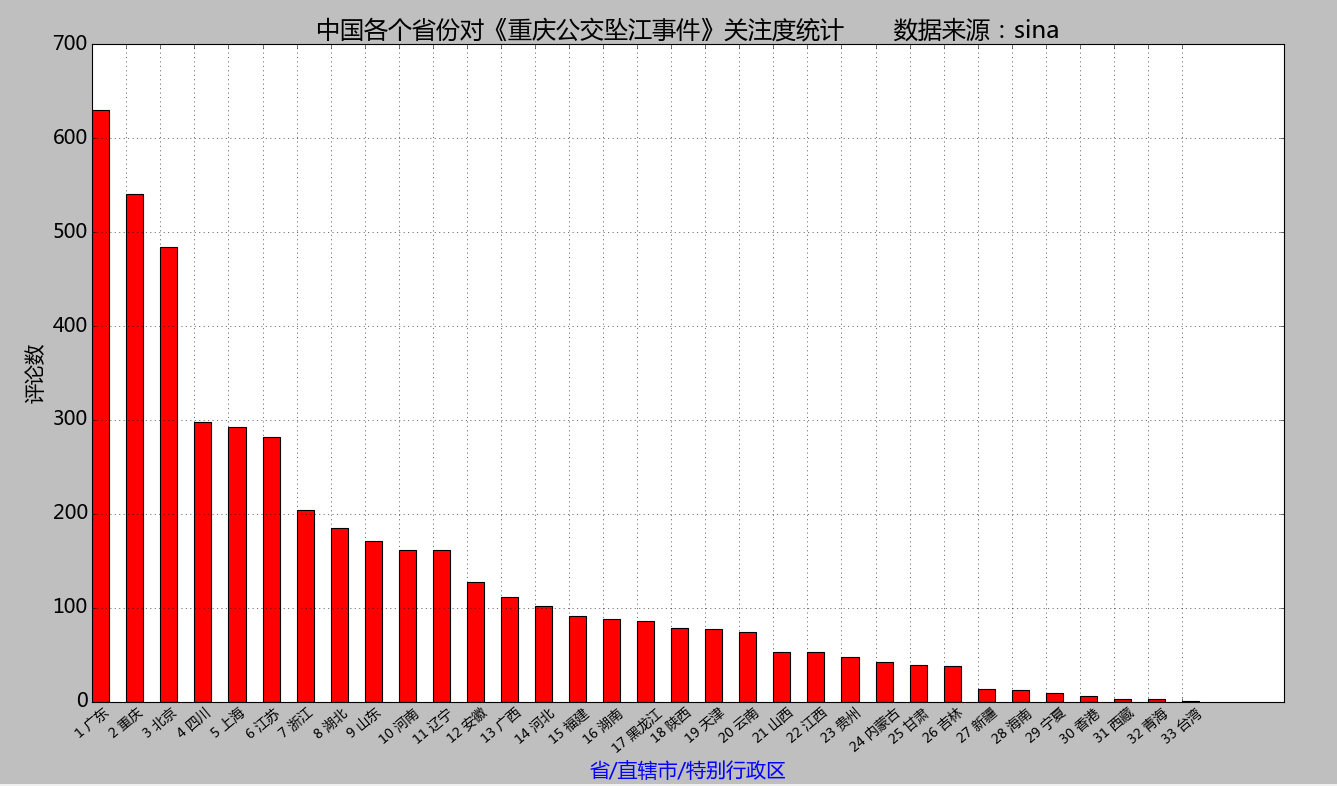
plt.title("中国各个省份对《重庆公交坠江事件》关注度统计 数据来源:sina")
plt.xlabel("省/直辖市/特别行政区", color='b')
plt.ylabel("评论数", color='black')
plt.show()
最终效果: