一、背景
博客园后台管理中,每页只能显示10篇文章的管理信息,如果想按照文章阅读量排序,根本就不可能。
二、分析方案
1、python爬虫requests获取后台页面中的所有文章管理数据。
2、导入电子表格Excel进行排序查看。
三、实现代码
1、cookie值的获取方法:
(1)打开谷歌浏览器Chrome,
(2)访问博客园并且登录账号,
(3)选择“新随笔”进入后台管理页面,
(4)再按下F12键,弹窗新的浏览器窗口工具,在窗口工具中选择“network”,以后注意观察,
(5)再点击“随笔”,
(6)此时观察到窗口工具中的特殊情况,如图: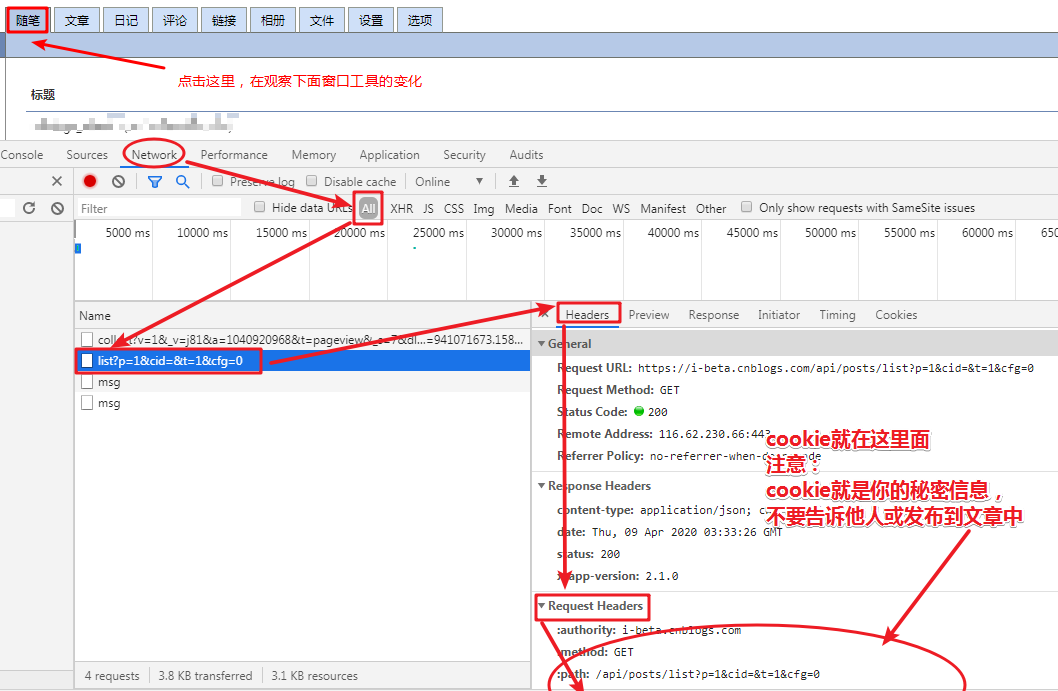
cookie值的替换样式:
'cookie': 'xxx',
注意:
(1)cookie就是你的密码信息,不要告诉他人或发布到文章中;
(2)xxx表示你的全部cookie值;
(3)cookie要用英文状态下的单引号括起来。
2、python代码如下。注意:'cookie': 0,要修改为正确的值。
安装python3
python -V # 验证python3是否安装成功
安装pip3
pip -V # 验证pip3是否安装成功
安装依赖包
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple requests
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple openpyxl
python源码(注意记得替换源码中的cookie值)
import time
import json
import math
import requests
import sys
import os
from openpyxl import Workbook
# 启动前输出
version_str = "V1.0"
logo_str = "cnBlogs_List"
logo_pic_str = """
____ _ _ _ _
___ _ __ | __ )| | ___ __ _ ___ | | (_)___| |_
/ __| '_ | _ | |/ _ / _` / __| | | | / __| __|
| (__| | | | |_) | | (_) | (_| \__ | |___| \__ |_
\___|_| |_|____/|_|\___/ \__, |___/ _____ |_____|_|___/\__|
|___/ |_____|
"""
print("%s %s" % (logo_str, version_str), end='')
print(logo_pic_str)
print("%s %s 启动中..." % (logo_str, version_str))
time.sleep(3)
# 开始启动
# 配置
# 方式一:直接赋值给常量COOKIE_STR
# cookie值
COOKIE_STR = ""
# 方式二:将cookie值存到一个指定的文件
COOKIE_PATH = "./mycookie.txt"
if os.path.exists(COOKIE_PATH) and len(COOKIE_STR) == 0:
# 如果存在cookie存值文件,且没有对系统常量cookie赋值,则读取文件中的内容
with open(COOKIE_PATH, 'r', encoding="utf-8") as f:
data_str = f.read()
if len(data_str) > 1:
# 如果存在文件内容,则向系统赋值cookie常量
COOKIE_STR = data_str
else:
print("There is no cookie value in the file %s" % COOKIE_PATH)
sys.exit()
# sys.exit()
CACHE_FILE_NAME = "cache.txt" # 缓存文件名称
EXCEL_FILE_NAME = "result.xls" # 电子表格文件名称
WORKSHEET_NAME = "cnblogs_admin" # 工作簿名称
# TABLE_HEAD_TITLE_LIST = ["title", "viewCount", "url", "comment_count", "datePublished", "dateUpdated"] # 表头名称
TABLE_HEAD_TITLE_LIST = ["标题", "阅读量", "链接", "评论数", "首次发布时间", "最近更新时间"] # 表头名称
SINGLE_PAGE_COUNT = 10 # 每页文章数目
# 定义函数
def get_data(page_n=1):
page_num = page_n
url = r'https://i-beta.cnblogs.com/api/posts/list?p=%s&cid=&t=1&cfg=0' % page_num
headers = {
'authority': 'i-beta.cnblogs.com',
'method': 'GET',
'path': '/api/posts/list?p=1&cid=&t=1&cfg=0',
'scheme': 'https',
'accept': 'application/json, text/plain, */*',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8',
'cookie': COOKIE_STR,
'referer': 'https://i-beta.cnblogs.com/posts',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-origin',
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.163 Safari/537.36',
'x-blog-id': '158654'}
# 发起get请求
response = requests.get(url, headers=headers, verify=True)
html_data = response.content.decode()
data_dict = json.loads(html_data)
post_list = data_dict["postList"] # 获取页面内容
all_post_count = data_dict["postsCount"] # 获取总文章数目
page_count = math.ceil(all_post_count / 10) # 获取总页数
if page_n == 1:
print("【code %s】第 %s 页:首页请求2遍,一遍获取总页数,另一遍获取首页数据写入文件" % (response.status_code, page_n))
else:
print("【code %s】第 %s 页" % (response.status_code, page_n))
info_result = [] # 写入表格的数据
# 写入首行
if page_num == 1:
info = TABLE_HEAD_TITLE_LIST # 首行内容
info_result.append(info)
# 获取当页内容
for index, item in enumerate(post_list):
title = item['title'] # 获取标题
viewCount = item['viewCount'] # 获取点击量
url = "https:%s" % item['url'] # 获取文章url
comment_count = item['feedBackCount'] # 获取评论数量
datePublished = item['datePublished'] # 获取首次发布日期
dateUpdated = item['dateUpdated'] # 获取最近修改日期
print((index + ((page_n - 1) * SINGLE_PAGE_COUNT) + 1), end=' ')
print(title)
# print(viewCount)
# print(url)
# print(comment_count)
# print("首发日期:", datePublished)
# print("修改日期:", dateUpdated)
# print()
info = [title, viewCount, url, comment_count, datePublished, dateUpdated] # 每行的内容
info_result.append(info)
return page_count, page_num, info_result
# 启动测试
if __name__ == '__main__':
info_result_all = [] # 所有页面的数据汇总列表
try:
page_count = int(get_data()[0]) # 获取总页面数。请求一次第一页。
except Exception:
print("请求无效,请替换为新Cookie值(COOKIE_STR)后重试")
sys.exit()
# 遍历所有页面
# for n in range(1, page_count + 1):
for n in range(1, 2 + 1):
time.sleep(1) # 休息一秒钟,降低请求频率
one_page_data_list = get_data(n) # 请求一次第n页
page_count = one_page_data_list[0]
page_num = one_page_data_list[1]
info_result = one_page_data_list[2]
info_result_all.extend(info_result)
# 将本页面数据写入缓存文件
save_file_cache = CACHE_FILE_NAME
with open(save_file_cache, 'a', encoding="utf-8") as f:
f.write("## 第 %s 页
" % page_num) # 缓存页面号
for line in info_result:
f.write("%s %s %s %s %s %s
" % tuple(line)) # 本页内容写入缓存
# 最后:将数据写入excel
save_file = EXCEL_FILE_NAME # 存入文件名称
sheet_name = WORKSHEET_NAME # 工作簿名称
wb = Workbook() # 新建工作簿
ws1 = wb.active # 获得当前活跃的工作页,默认为第一个工作页
ws1.title = sheet_name # 修改页名称。sheet名称
for row in info_result_all:
ws1.append(row)
wb.save(save_file) # Excel文件名称,保存文件
3、运行后:

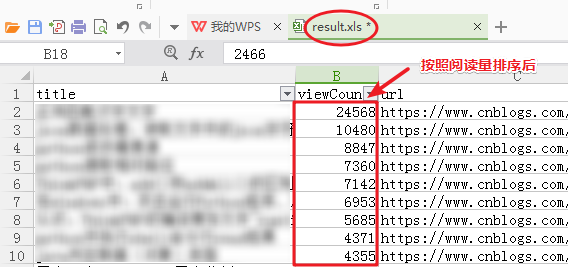
4、Excel排序后
v1.3版
新增:
1、存mysql数据
2、sql建库建表
3、已存mysql的不再重复存入,url作为唯一标识。
py文件代码:
import time
import json
import math
import requests
import sys
import os
from openpyxl import Workbook
import pymysql
# 启动前输出
version_str = "V1.3"
logo_str = "cnBlogs_List"
logo_pic_str = """
____ _ _ _ _
___ _ __ | __ )| | ___ __ _ ___ | | (_)___| |_
/ __| '_ | _ | |/ _ / _` / __| | | | / __| __|
| (__| | | | |_) | | (_) | (_| \__ | |___| \__ |_
\___|_| |_|____/|_|\___/ \__, |___/ _____ |_____|_|___/\__|
|___/ |_____|
"""
print("%s %s" % (logo_str, version_str), end='')
print(logo_pic_str)
print("%s %s 启动中..." % (logo_str, version_str))
time.sleep(2.5)
# 开始启动
# 配置
# 方式一:直接赋值给常量COOKIE_STR
# cookie值
COOKIE_STR = ""
# 方式二:将cookie值存到一个指定的文件
COOKIE_PATH = "./mycookie.txt"
if os.path.exists(COOKIE_PATH) and len(COOKIE_STR) == 0:
# 如果存在cookie存值文件,且没有对系统常量cookie赋值,则读取文件中的内容
with open(COOKIE_PATH, 'r', encoding="utf-8") as f:
data_str = f.read()
if len(data_str) > 0:
# 如果存在文件内容,则向系统赋值cookie常量
COOKIE_STR = data_str
else:
print("There is no cookie value in the file %s" % COOKIE_PATH)
sys.exit()
# sys.exit()
CACHE_FILE_NAME = "cache.txt" # 缓存文件名称
EXCEL_FILE_NAME = "result.xls" # 电子表格文件名称
WORKSHEET_NAME = "cnblogs_admin" # 工作簿名称
# TABLE_HEAD_TITLE_LIST = ["title", "countView", "countCommet", "url", "datePublished", "dateUpdated"] # 表头名称
TABLE_HEAD_TITLE_LIST = ["标题", "阅读量", "评论数", "链接", "首次发布时间", "最近更新时间"] # *.xls或cache.txt表头名称
SINGLE_PAGE_COUNT = 10 # 每页文章数目
# 配置请求参数
REQUEST_URL_PART = r'https://i-beta.cnblogs.com/api/posts/list?p=%s&cid=&t=1&cfg=0'
REQUEST_HEADERS = {
'authority': 'i-beta.cnblogs.com',
'method': 'GET',
'path': '/api/posts/list?p=1&cid=&t=1&cfg=0',
'scheme': 'https',
'accept': 'application/json, text/plain, */*',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8',
'cookie': COOKIE_STR,
'referer': 'https://i-beta.cnblogs.com/posts',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-origin',
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.163 Safari/537.36',
}
# 全局变量
info_result_all = [] # 所有页面的数据汇总列表
# 配置mysql数据库连接参数
MYSQL_HOST = 'localhost'
MYSQL_PORT = 3306
MYSQL_USER = 'root'
MYSQL_PASSWD = 'root'
MYSQL_DB = 'cbs'
MYSQL_CHARSET = 'utf8'
# 连接数据库
connect = pymysql.Connect(
host=MYSQL_HOST,
port=MYSQL_PORT,
user=MYSQL_USER,
passwd=MYSQL_PASSWD,
db=MYSQL_DB,
charset=MYSQL_CHARSET
)
# 获取游标
cursor = connect.cursor()
# 定义函数
# 获取总页数
def get_page_count(page_n=1):
page_num = page_n
# 构造请求参数
url = REQUEST_URL_PART % page_num
headers = REQUEST_HEADERS
# 发起get请求
response = requests.get(url, headers=headers, verify=True)
html_data = response.content.decode()
data_dict = json.loads(html_data)
all_post_count = data_dict["postsCount"] # 获取总文章数目
page_count = math.ceil(all_post_count / 10) # 获取总页数
# 返回总页数
return page_count
# 请求每个列表页的数据
# 1、打印到控制台
# 2、存入mysql数据库cbs中article_list表中
def get_per_page_data(page_n=1, save_mysql=True):
page_num = page_n
url = REQUEST_URL_PART % page_num
headers = REQUEST_HEADERS
# 发起get请求
response = requests.get(url, headers=headers, verify=True)
html_data = response.content.decode()
data_dict = json.loads(html_data)
post_list = data_dict["postList"] # 获取页面内容
all_post_count = data_dict["postsCount"] # 获取总文章数目
page_count = math.ceil(all_post_count / 10) # 获取总页数
print("【status %s】第 %s 页" % (response.status_code, page_n))
info_result = [] # 写入表格的数据
# 写入首行
if page_num == 1:
info = TABLE_HEAD_TITLE_LIST # 首行内容
info_result.append(info)
# 获取当页内容
for index, item in enumerate(post_list):
title = item['title'] # 获取标题
viewCount = item['viewCount'] # 获取点击量
comment_count = item['feedBackCount'] # 获取评论数量
url = "https:%s" % item['url'] # 获取文章url
datePublished = item['datePublished'] # 获取首次发布日期
dateUpdated = item['dateUpdated'] # 获取最近修改日期
# 打印到控制台
print((index + ((page_n - 1) * SINGLE_PAGE_COUNT) + 1), end=' ')
print(title)
info = [title, viewCount, comment_count, url, datePublished, dateUpdated] # 每行的内容
# 存内存列表
info_result.append(info)
if save_mysql is True:
# 存mysql数据库
# 先检查数据库中是否已经存有,如果已存,则不再存入
sql_0 = "select url from article_list where url='%s'"
cursor.execute(sql_0 % url) # 生成增加sql语句
url_list = cursor.fetchall() # 获取查询结果
if len(url_list) > 0:
print("数据库已存在:%s " % url)
else:
# 增加数据操作
sql_1 = "INSERT INTO article_list(title,countView,countComment,url,datePublished,dateUpdated) VALUES ('%s','%s','%s','%s','%s','%s');"
data = tuple(info)
cursor.execute(sql_1 % data) # 生成增加sql语句
# cursor.execute(sql_1) # 生成增加sql语句
connect.commit() # 确认永久执行增加
return page_count, page_num, info_result
# 变量列表页,数据存mysql、txt
def get_cbs_list_data(page_count, save_cache=True):
for n in range(1, page_count + 1):
time.sleep(1) # 休息一秒钟,降低请求频率
one_page_data_list = get_per_page_data(n, save_mysql=True) # 请求一次第n页,并存mysql数据库
page_num = one_page_data_list[1]
info_result = one_page_data_list[2]
info_result_all.extend(info_result)
if save_cache is True:
# 将本页面数据写入缓存文件cache.txt
save_file_cache = CACHE_FILE_NAME
with open(save_file_cache, 'a', encoding="utf-8") as f:
f.write("## 第 %s/%s 页
" % (page_num, page_count)) # 缓存页面号
for line in info_result:
f.write("%s %s %s %s %s %s
" % tuple(line)) # 本页内容写入缓存
# 将数据写入excel
def save_excel():
save_file = EXCEL_FILE_NAME # 存入文件名称
sheet_name = WORKSHEET_NAME # 工作簿名称
wb = Workbook() # 新建工作簿
ws1 = wb.active # 获得当前活跃的工作页,默认为第一个工作页
ws1.title = sheet_name # 修改页名称。sheet名称
for row in info_result_all:
ws1.append(row)
wb.save(save_file) # Excel文件名称,保存文件
# 主函数
# 1、遍历所有页面
# 2、存入缓存文件cache.txt、存入mysql数据库
# 3、数据存入内存
# 4、存入xls电子表格中
def main():
# 尝试请求第一个列表页,获取总页数
try:
page_count = int(get_page_count()) # 获取总页面数。
except Exception:
print("请求无效,请替换为新Cookie值(COOKIE_STR)后重试")
sys.exit()
# 遍历所有页面。存mysql,存cache.txt文件
# get_cbs_list_data(page_count, save_cache=False)
get_cbs_list_data(2, save_cache=True) # 遍历前2页
# 最后:将数据写入excel
# save_excel()
# 启动测试
if __name__ == '__main__':
# 启动主程序
main()
建表语句
1、添加url的btree类型索引
/* Navicat MySQL Data Transfer Source Server : win7_local Source Server Version : 50717 Source Host : localhost:3306 Source Database : cbs Target Server Type : MYSQL Target Server Version : 50717 File Encoding : 65001 Date: 2020-05-27 11:35:19 */ SET FOREIGN_KEY_CHECKS=0; -- ---------------------------- -- Table structure for article_list -- ---------------------------- DROP TABLE IF EXISTS `article_list`; CREATE TABLE `article_list` ( `id` int(11) unsigned NOT NULL AUTO_INCREMENT, `title` varchar(255) DEFAULT NULL, `countView` varchar(10) DEFAULT NULL, `countComment` varchar(10) DEFAULT NULL, `url` varchar(100) DEFAULT NULL, `datePublished` datetime DEFAULT NULL, `dateUpdated` datetime DEFAULT NULL, PRIMARY KEY (`id`), KEY `url_index` (`url`) USING BTREE ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;