persons.xml文件内容:
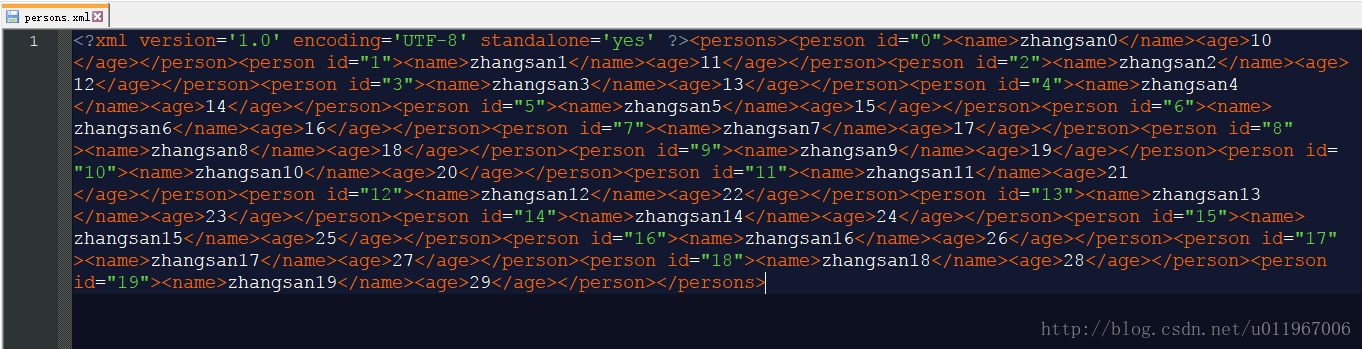
<?xml version='1.0' encoding='UTF-8' standalone='yes' ?><persons>
<person id="0"><name>zhangsan0</name><age>10</age></person>
<person id="1"><name>zhangsan1</name><age>11</age></person>
<person id="2"><name>zhangsan2</name><age>12</age></person>
<person id="3"><name>zhangsan3</name><age>13</age></person>
<person id="4"><name>zhangsan4</name><age>14</age></person>
<person id="5"><name>zhangsan5</name><age>15</age></person>
<person id="6"><name>zhangsan6</name><age>16</age></person>
<person id="7"><name>zhangsan7</name><age>17</age></person>
<person id="8"><name>zhangsan8</name><age>18</age></person>
<person id="9"><name>zhangsan9</name><age>19</age></person>
<person id="10"><name>zhangsan10</name><age>20</age></person>
<person id="11"><name>zhangsan11</name><age>21</age></person>
<person id="12"><name>zhangsan12</name><age>22</age></person>
<person id="13"><name>zhangsan13</name><age>23</age></person>
<person id="14"><name>zhangsan14</name><age>24</age></person>
<person id="15"><name>zhangsan15</name><age>25</age></person>
<person id="16"><name>zhangsan16</name><age>26</age></person>
<person id="17"><name>zhangsan17</name><age>27</age></person>
<person id="18"><name>zhangsan18</name><age>28</age></person>
<person id="19"><name>zhangsan19</name><age>29</age></person>
</persons>点击动作,去解析xml数据,并Log.d打印出来:
PullParser解析器是基于事件的,有开始文档,结束文档,开始标签,结束标签,当事件解析到那个节点的时候,是可以通过pullParser.getName();得到某个具体节点;
@Override
public void onClick(View v) {
try {
// 得到Android 提供的Xml解析器 PullParser
XmlPullParser pullParser = Xml.newPullParser();
// 指定文件流对象
InputStream is = openFileInput("persons.xml");
// 设置需要解析的文件流对象
pullParser.setInput(is, "utf-8");
// 开始解析
// 获取解析事件的类型
int eventType = pullParser.getEventType();
List<Person> persons = null;
Person person = null;
// 只要没有解析到文档的结尾,就继续往下不停的解析
while(eventType != XmlPullParser.END_DOCUMENT) {
switch (eventType) {
// 节点开始标记<xxx>
case XmlPullParser.START_TAG:
// 解析到根节点
if (pullParser.getName().equals("persons")) {
persons = new ArrayList<Person>();
}
// 解析到子节点
else if (pullParser.getName().equals("person")) {
person = new Person();
// 解析ID属性
// 因为我只有一个属性,所以是0
int id = Integer.parseInt(pullParser.getAttributeValue(0));
person.setId(id);
}
// 解析到子节点的name
else if (pullParser.getName().equals("name")) {
person.setName(pullParser.nextText());
}
// 解析到子节点的age
else if (pullParser.getName().equals("age")) {
person.setAge(Integer.valueOf(pullParser.nextText()));
}
break;
case XmlPullParser.END_TAG: // 节点结束标记</xxx>
// 当解析到</person>就代表解析一个完一个子节点了
if (pullParser.getName().equals("person")) {
persons.add(person);
person = null;
}
break;
default:
break;
}
// 更新解析的哪里了
eventType = pullParser.next();
}
// 把解析出来的Xml数据,进行日志打印
for (Person p : persons) {
Log.d(TAG, "解析出来的Xml数据:" + p.toString());
}
} catch (Exception e) {
e.printStackTrace();
}
}Log.d 打印结果:

解析出来的Xml数据:Person{id=0, name=’zhangsan0’, age=10}
解析出来的Xml数据:Person{id=1, name=’zhangsan1’, age=11}
解析出来的Xml数据:Person{id=2, name=’zhangsan2’, age=12}
解析出来的Xml数据:Person{id=3, name=’zhangsan3’, age=13}
解析出来的Xml数据:Person{id=4, name=’zhangsan4’, age=14}
解析出来的Xml数据:Person{id=5, name=’zhangsan5’, age=15}
解析出来的Xml数据:Person{id=6, name=’zhangsan6’, age=16}
解析出来的Xml数据:Person{id=7, name=’zhangsan7’, age=17}
解析出来的Xml数据:Person{id=8, name=’zhangsan8’, age=18}
解析出来的Xml数据:Person{id=9, name=’zhangsan9’, age=19}
解析出来的Xml数据:Person{id=10, name=’zhangsan10’, age=20}
解析出来的Xml数据:Person{id=11, name=’zhangsan11’, age=21}
解析出来的Xml数据:Person{id=12, name=’zhangsan12’, age=22}
解析出来的Xml数据:Person{id=13, name=’zhangsan13’, age=23}
解析出来的Xml数据:Person{id=14, name=’zhangsan14’, age=24}
解析出来的Xml数据:Person{id=15, name=’zhangsan15’, age=25}
解析出来的Xml数据:Person{id=16, name=’zhangsan16’, age=26}
解析出来的Xml数据:Person{id=17, name=’zhangsan17’, age=27}
解析出来的Xml数据:Person{id=18, name=’zhangsan18’, age=28}
解析出来的Xml数据:Person{id=19, name=’zhangsan19’, age=29}
谢谢大家的观看,更多精彩技术博客,会不断的更新,请大家访问,
刘德利CSDN博客, http://blog.csdn.net/u011967006