count 求这张表有多少行数据
max 获取某列的最大值
min 获取某列的最小值
sum 对某列进行求和
avg 对某列求平均值
Select配合聚合用到的关键字
Group by, Having
排序关键字
Order by
获取指定行数
Top
###count 常见三种写法:
- count(*)
- count(某列)
- count(1)
唯一要留意的就是count(某列),它们会忽略null值的数据(可以自己插入一笔某列为null数据测试一下)
count(*) 也有概率会,出现的情况根据表设计而定,如一张表只有一列,而这一列允许null,那么就会出现,不推荐用count(*)因为它会根据主键和索引选定列,容易踩坑
count(1)不会的原因是因为它是别名列,下面有例子助于你理解别名列的意思
水太深就不理那么多先,所以说了那么多,平常用count(1)就好了
插入一笔除Id外,其它为null的数据
insert into Student (Id) values(newId())
获取当前表的数量
select count(*) as Num from Student
select count(age) as Num from Student
所有列都会带上别名,所以别名的内容不会为null,就可以统计到所有行
select *, 1 as '别名' from Student
select count(1) as Num from Student
也不一定要1,也可以其它,但是大家都写1所以,随波逐流。。。
就像每次学不同的框架和语言都得写一次Hello World的意思一样
select count('就是不写1') as Num from Student
P.S:留意,一般用于计算某列的聚合函数都会对null进行处理,下面这几个都是如此
###max(求最大)
select max(age) as Num from Student
###min(求最小)
select min(age) as Num from Student
###sum(求和)
select sum(age) as Num from Student
###avg(求平均)
select avg(age)as Num from Student
P.S: 有没有发现,select Name from Student Name为什么是蓝色的,和我们的select,from关键字一样 因为Name在SqlServer里属于关键字,所以为什么会有这种写法的出现[Name] 中括号[],可以去关键字化
select [Name], '' as [select] from Student
##Select 当我们用聚合函数时,带上其它字段会报一个错误
P.S: Column 'Student.Name' is invalid in the select list because it is not contained in either an aggregate function or the GROUP BY clause. "Student.Name"列在选择列表中无效,因为它不包含在聚合函数或 GROUP BY 条款中。
为什么会有这个错误,因为当我们带上字段sqlserver是不知道你到底是想要求和,还是要正常查询,所以就引出后续的查询关键字group by分组
####Group by Group by的作用和Distinct(额外知识点)的共同点就是去重,但不同的是Group by可以配合聚合函数,对某列进行重复值进行统计计算
select Class from Student group by Class
| Class |
|---|
| NULL |
| 一年级 |
| 七年级 |
| 三年级 |
| 九年级 |
| 二年级 |
| 八年级 |
| 六年级 |
| 四年级 |
select Class, count(Class) as Num from Student group by Class
| Class | Num |
|---|---|
| NULL | 0 |
| 一年级 | 5 |
| 七年级 | 4 |
| 三年级 | 5 |
| 九年级 | 4 |
| 二年级 | 5 |
| 八年级 | 2 |
| 六年级 | 2 |
| 四年级 | 3 |
如果有多个字段,也是一样往group by后面加,核心要点就是重复值,根据这个理解可以出个小难题,我想统计七年级的男女有多少,并且进行从大到小排序 那么关键点是什么,班级,性别,也就这两个重复值,还有就是千万别忘了要计算的列
P.S:这是一个固定格式,where(条件)要在group by(分组)之前,order by(排序)一般都是放最后
select Class, Gender, count(Class) as Num from Student
where Class=N'七年级' --这里带N的原因是我的电脑编码问题,一般是不需要带的(额外知识点)
group by Class,Gender
order by Num desc
Class|Gender|Num| ----|----|----| 七年级| 女| 3| 七年级| 男| 1| ####Having 用来配合聚合函数group by(分组)统计后,再次需要进行对聚合函数算出来的结果进行条件的关键字 如果说Where是作为查询条件,那么Having就是作为Group by的Where 比如我想看所有年级的平均年龄大于20的班级,并且从大到小进行排序
select [Class], avg(Age) as Num from Student
group by Class
having avg(Age) > 20
order by Num desc
| Class | Num |
|---|---|
| 六年级 | 27 |
| 九年级 | 23 |
| 七年级 | 23 |
| 三年级 | 21 |
P.S:having只能跟在group by(分组)之后,order by(排序)还是老样子只能在最后,因为是根据结果进行排序 那配合上我们的Where是怎么样的呢
select [Class], avg(Age) as Num from Student
where Class=N'七年级'
group by Class
having avg(Age) > 20
order by Num
| Class | Num |
|---|---|
| 七年级 | 23 |
####Order by(排序关键字) desc 降序 从大到小 asc 升序 从小到大 记不清可以这么理解 降序:下降,那得有高度,才能降下来 升序:升上去,那得在平地才能往上走 如同电梯一样从一楼到5楼,上升,从5楼到1楼,下降 order by 默认是升序
-- 根据年龄降序
select top(5) * from Student order by Age desc
P.S: top用来指定获取多少行,top(3)就是获取三行 这里埋一个坑,order by 排序多个是怎样的呢,可以自己试一试,搜一搜
| Id | Name | Age | Gender | Area | Address | IdCard | Birthday | Class |
|---|---|---|---|---|---|---|---|---|
| 2A7ECE2E-080D-4EB9-8DB7-969C1D921FC9 | 蔚灵凡 | 33 | 女 | 广西 | 广西壮族自治区梧州市龙圩区 | 450406198802252403 | 1988-02-25 00:00:00.000 | 九年级 |
| 93E87057-340D-46E5-BEBA-3AF51C2DA7AD | 宦丹琴 | 29 | 女 | 河北 | 河北省石家庄市井陉矿区 | 13010719920206162X | 1992-02-06 00:00:00.000 | 三年级 |
| 36E6F1E0-110B-48B2-8B9D-DA1076CC0C21 | 唐金文 | 29 | 女 | 浙江 | 浙江省温州市鹿城区 | 330302199212126323 | 1992-12-12 00:00:00.000 | 三年级 |
| 3BF505B3-95EE-4B41-9DA6-845BA81488DB | 浦开济 | 28 | 男 | 江西 | 江西省赣州市信丰县 | 360722199304244477 | 1993-04-24 00:00:00.000 | 六年级 |
| 08373DD8-856F-41F7-9669-F102E38BFC1D | 隆水桃 | 28 | 女 | 辽宁 | 辽宁省沈阳市和平区 | 21010219930206800X | 1993-02-06 00:00:00.000 | 四年级 |
##更新(Update) 将刚才新增的数据进行修改
P.S:注意这里的Id,跟你的是不一样的请留意 P.S:注意每次更新要要成好习惯,先查询,确认条件,再更新,避免犯错,切记!


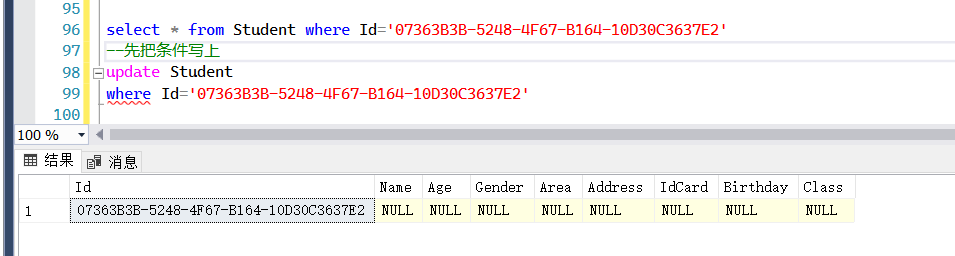
select * from Student where Id='07363B3B-5248-4F67-B164-10D30C3637E2'
--先把条件写上
update Student
where Id='07363B3B-5248-4F67-B164-10D30C3637E2'
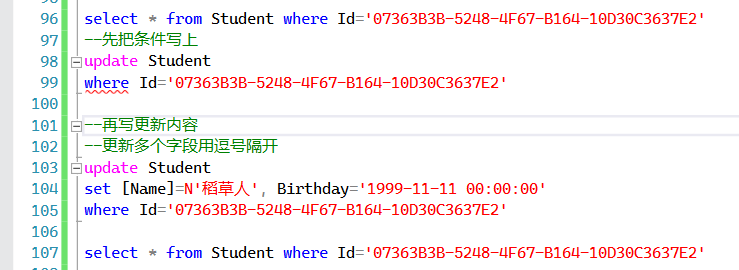
--再写更新内容
--更新多个字段用逗号隔开
update Student
set [Name]=N'稻草人', Birthday='1999-11-11 00:00:00'
where Id='07363B3B-5248-4F67-B164-10D30C3637E2'
select * from Student where Id='07363B3B-5248-4F67-B164-10D30C3637E2'
##删除(Delete) 将刚才新增的数据进行删除
P.S:注意这里的Id,跟你的是不一样的请留意 P.S:注意每次删除要要成好习惯,先查询,确认条件,再删除,避免犯错,切记!
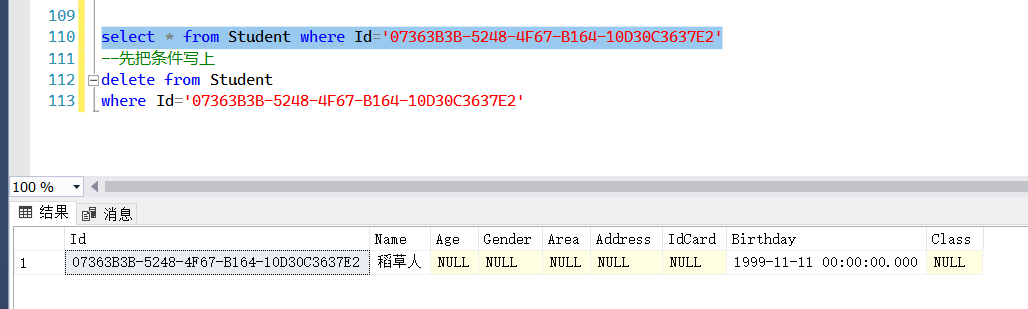
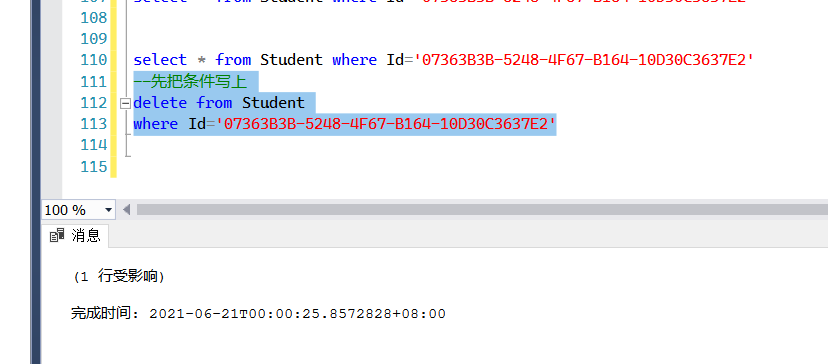
select * from Student where Id='07363B3B-5248-4F67-B164-10D30C3637E2'
--先把条件写上
delete from Student
where Id='07363B3B-5248-4F67-B164-10D30C3637E2'
到这里就算结束了 总结: 需要养成良好的习惯,聚合函数的计算列记得要给名字 聚合函数计算时,会过滤掉Null值数据 更新和删除切记一定要先查询确认条件再进行操作,因为这是不可逆的 下一节表设计一,联接查询 ##题目
--1、 计算这批学生中男女各多少,从大到小进行排序
--2、 计算这批学生,男女的平均年龄是多少,并且要大于10
--3、 计算各地区的班级一共有多少人,并且人数大于1
--4 计算各地区的平均年龄,并且查询出大于该平均年龄的学生,最后结果按按年龄升序(子查询)
--5 计算各地区最小年龄,并且查询出该地区是最小年龄的学生信息,最后结果按按年龄降序(子查询)