1. 看下面sql,重点有两个,一个是distinct ,一个是树形结构查询
select DISTINCT t.unit_code from t_unit_relation t where t.corp_tn='jiaozhougongan' start with t.unit_code='0001' connect by prior t.unit_code = t.unit_upcode
分析:
① distinct:去重复值
② 树形结构查询,这个博客:http://www.cnblogs.com/benbenduo/p/4588612.html,讲的很好
提出几句以作概括
start with 子句:遍历起始条件
connect by 子句:连接条件
prior: prior跟父节点列parentid放在一起,就是往父结点方向遍历;prior跟子结点列subid放在一起,则往叶子结点方向遍历,
parentid、subid两列谁放在“=”前都无所谓,关键是prior跟谁在一起。
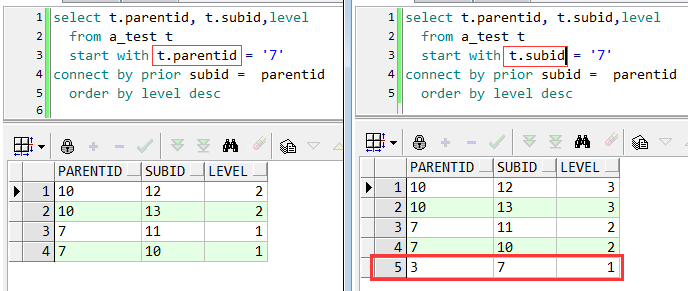
select t.parentid, t.subid, level from table t start with t.parentid='7' connect by prior subid = parentid order by level desc
--prior跟着subid 说明往叶子结点遍历,以7为父结点的子结点
select t.parentid, t.subid, level from table t start with t.subid='7' connect by prior subid = parentid order by level desc
--prior跟着subid 说明往叶子结点遍历,以7为子节点的父结点,往下遍历,所以图二会有 3
效果图,借用那个博客的:
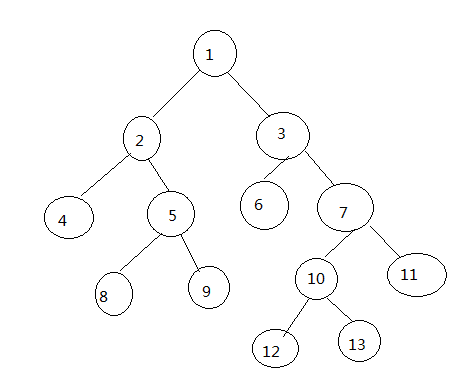
2. group by : 有一个原则,就是 select 后面的所有列中,没有使用聚合函数(如:count,sum,等函数)的列,必须出现在 group by 后面
--解释:按照某一个列进行分组,肯定这个列是有的(重复也会变为一个),其他的列是有可能重复的,显示多个就不对了
注意:①:group by,后面有两个字段或者多个字段,可以看这个链接:http://uule.iteye.com/blog/1569262,
总结一下:多个字段会先按照第一个进行分组,之后再第一个的分组后的基础之上进行按照第二个字段进行第二次分组,以此类推
3. 内连接:① 关联字段中肯定可以在关联表中查到
② 且只能查到一条
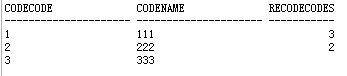
图1:aatest2 表

图2:aatest 表

select a1.codecode,a1.codename,a2.recodecodes from aatest2 a1 inner join (select codecode,count(recodecode) recodecodes from aatest group by codecode having count(recodecode)>1) a2 on a1.codecode=a2.codecode

4. 左连接:以左边表为基准,联合查询出左边表(所有数据),右边表相关联的数据
select a1.codecode,a1.codename,a2.recodecodes from aatest2 a1 left join (select codecode,count(recodecode) recodecodes from aatest group by codecode having count(recodecode)>1) a2 on a1.codecode=a2.codecode
5. 右连接:以右表为基准,查询出与右边表(所有数据),左边表相关联的数据
select a1.codecode,a1.codename,a2.recodecodes from aatest2 a1 right join (select codecode,count(recodecode) recodecodes from aatest group by codecode having count(recodecode)>1) a2 on a1.codecode=a2.codecode
6. nvl() : 如果 useryy.mc 等于 null,则显示 usergys.mc ; 如果userjd.mc等于null,则显示useryy.mc
select SYSUSER.id, nvl(userjd.mc, nvl(useryy.mc, usergys.mc)) sysmc from SYSUSER
left join userjd on SYSUSER.Sysid = userjd.id left join useryy on SYSUSER.Sysid = useryy.id left join usergys on SYSUSER.Sysid = usergys.id
7. decode(): 判断Groupid 如果等于1,则显示userjd.mc;如果Groupid等于2,则显示userjd.mc;如果Groupid等于3,则显示useryy.mc;如果Groupid等于4,则显示usergys.mc
select decode(SYSUSER.Groupid, '1', (select mc from userjd where id = sysuser.sysid), '2', (select mc from userjd where id = sysuser.sysid), '3', (select mc from useryy where id = sysuser.sysid), '4', (select mc from usergys where id = sysuser.sysid) ) sysmc from SYSUSER