书中介绍太绕,甚至是不清楚的,在此记录一下学习体会!
该例主要讲的是用户洗浴用水事件的识别问题(热水器数据),归结为0-1分类问题——这是全局观
按分析问题大的步骤:
数据探索性分析——>数据规约——>一次用水事件划分及阈值寻优——>特征工程/属性构造——>筛选洗浴事件(?)——>NN-Model
- (?)这一部分,没搞懂作者意图,问题一开始就说是要识别出独立用水事件中的洗浴事件,那到此步骤不就完了,~后面就是为了跑跑模型train-test,blabla~???
- 从该章标题看(?)及之前是家用电器用户行为分析,之后才是事件识别,这样才解释得通
- 最值得吐槽的是:自己说的数值规约,然而自己实现起来就跟本不存在什么数值规约哦
个人觉得本章最值得学习的点有:
- 问题的分析思路(先后该做些什么、如何做),见上面步骤
- 数据分析处理方法(见下方简要介绍)
- 特征工程/属性构造(涉及特定问题特定分析,结合问题的关注点,如选取了时长类指标、频率类指标、水量指标、用水变化/波动指标)
- 筛选洗浴事件方式方法:一次用水事件划分——>候选洗浴事件划分(一次用水量<yLitre、用水时长<100s、总用水时长<120s)
关于数据分析处理方法,文中介绍甚是模糊,个人理解记录于此:
时间的划分均是基于用水量数据来区分的
一次用水事件划分
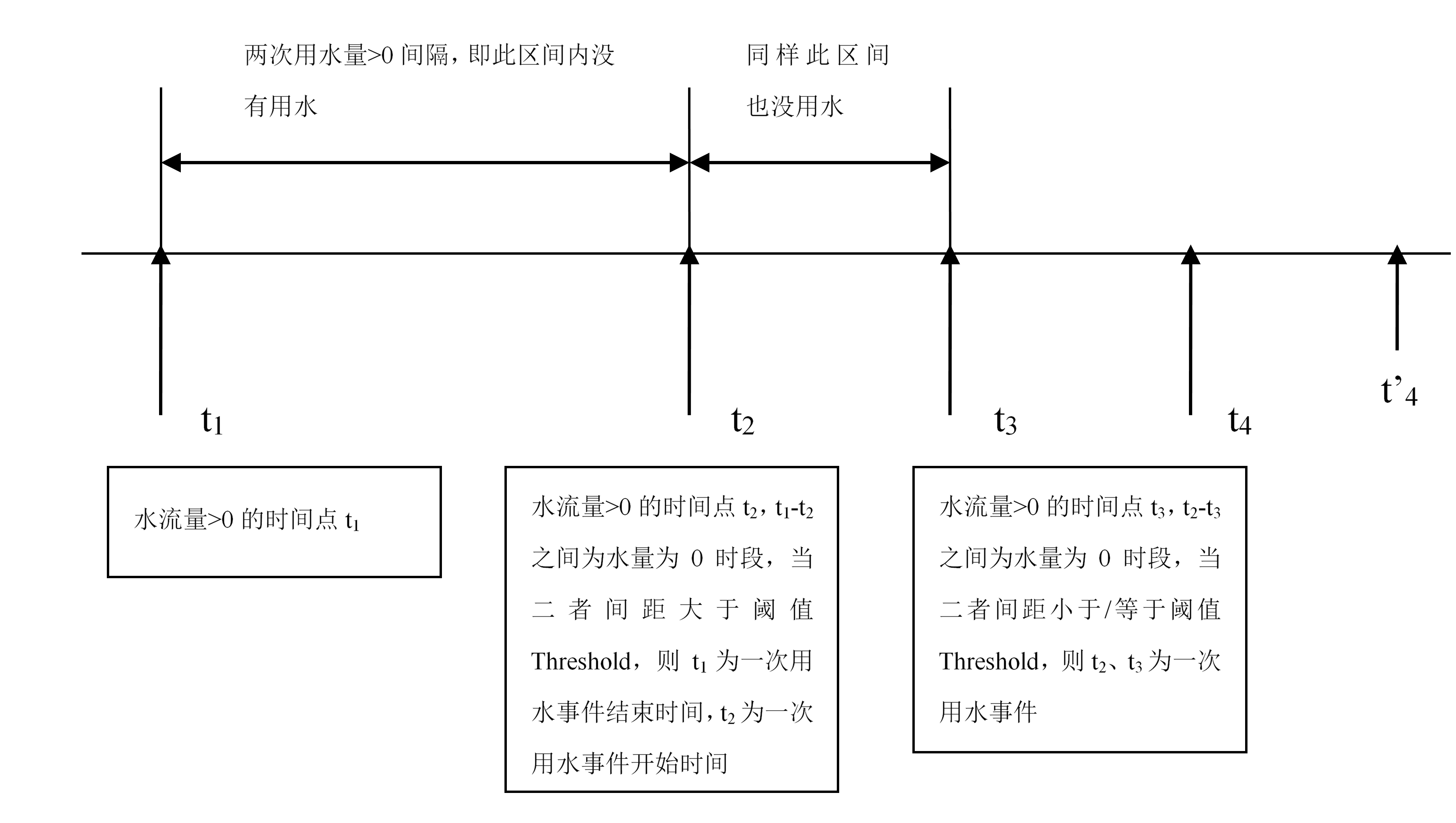
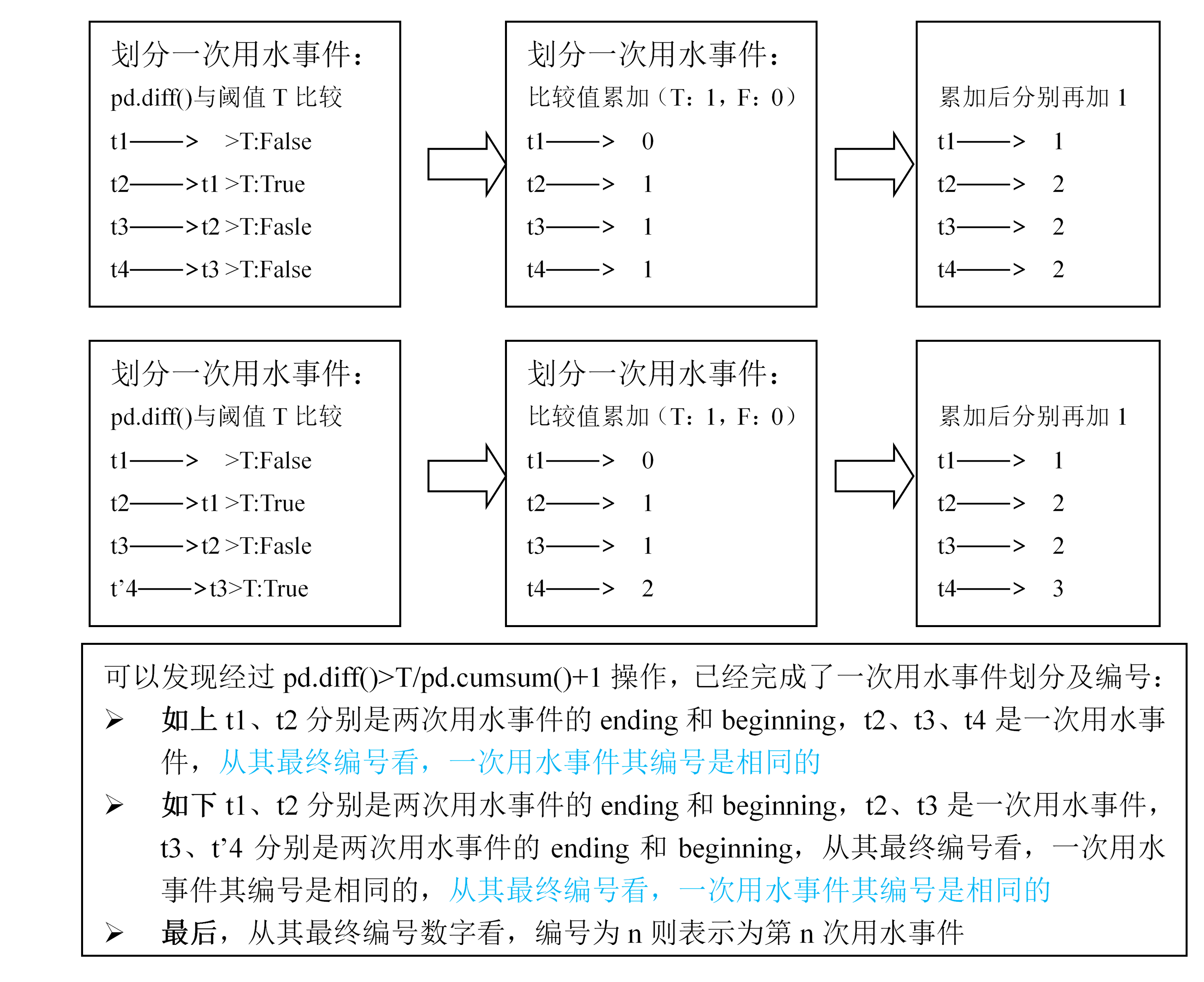
阈值寻优
阈值寻优区间1min——9min,step=0.25min=15s
计算原理:
以阈值及对应划分的用水事件数,作图,当n个相邻点斜率值(取最小的斜率对应的阈值,斜率小说明曲线平稳用户习惯比较趋于平稳)
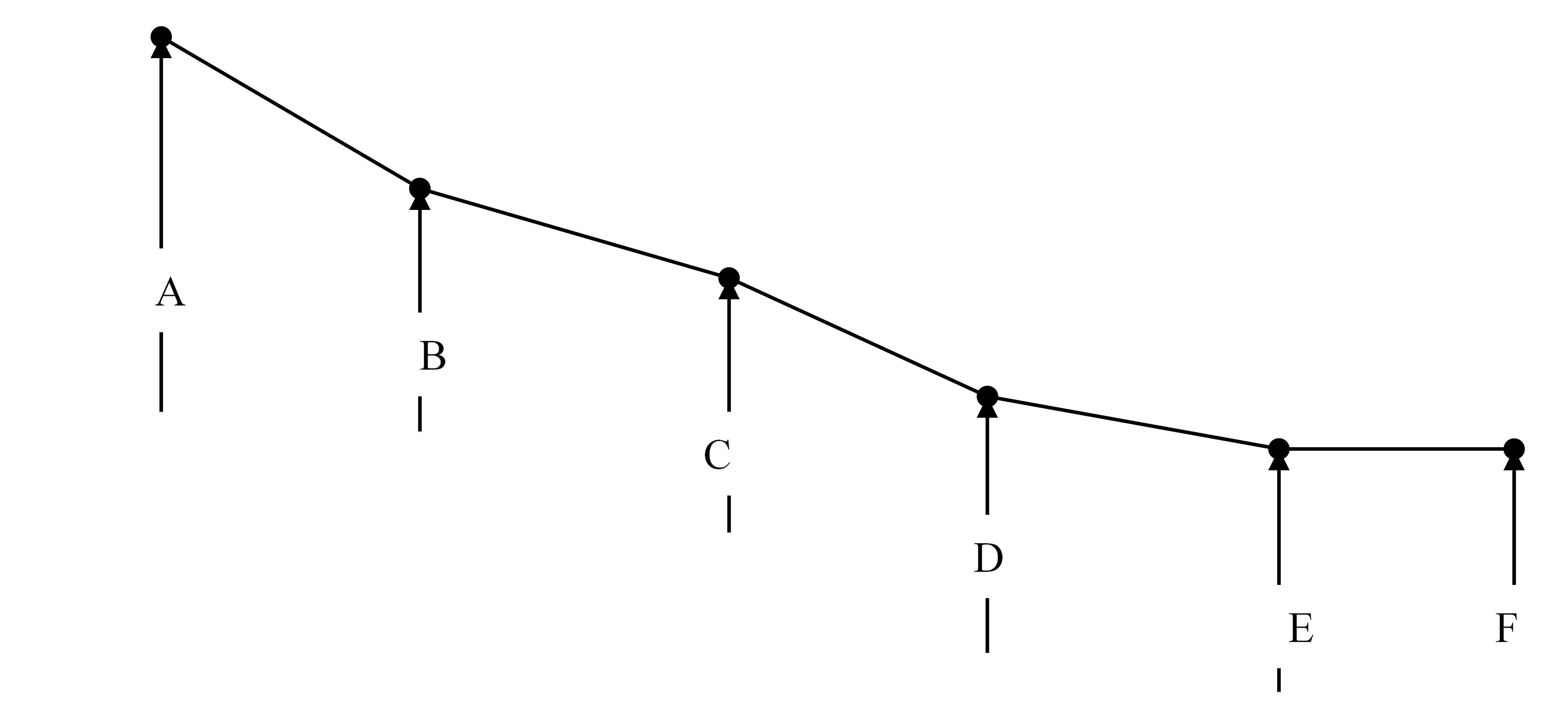

特征工程/ 属性构造
这类问题解构/组合需要经验和对应问题需要,多多学习~~
筛选候选洗浴事件
文中给出的是判定短暂用水事件,将其余的作为候选洗浴事件,可惜的是描述混乱+无代码
关于判定标准,个人感觉非常的主观呀(这里仅摘记文中标准,满足一个就算是短暂,或关系),希望大神留言讲一讲啊,thx~
- 一次用水事件总用水(总水量*热水量(%)=纯热水)<yLitre
- 用水时长<100s
- 总用水时长<120s
其中文中y的取值也很有意思,考虑了热水器不同设定温度下热水的使用量阈值y:
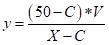
由一系列假设,说明当一次洗浴中热水温度越高热水量使用就越少,反之反是;
V表示热水器的水恒50度时洗浴最低用量,X当前水温,C注入的自来水每月平均温度(室温均值)
多层神经网络
1 from keras.models import Sequential 2 from keras.layers.core import Dense,Activation 3 4 net = Sequential() 5 #net.add(Dense(input_dim = 11, output_dim = 17))#keras 2.0之前版本 6 net.add(Dense(input_dim=11, units=17))#keras 2.0 ,推荐;添加输入层、隐藏层的连接 7 net.add(Activation('relu')) 8 net.add(Dense(input_dim=17, units=10)) 9 net.add(Activation('relu')) 10 #model.add(Dense(10, 1)) #添加隐藏层、输出层的连接 11 net.add(Dense(1)) # 输出层,同上 12 net.add(Activation('sigmoid')) 13 net.compile(loss='binary_crossentropy', optimizer='adam',metrics=['accuracy']) 14 15 #net.fit(x_train, y_train,epochs=10,batch_size=1)#keras 2.0之前版本 16 net.fit(x_train, y_train,epochs=1000,batch_size=1,verbose=1)#keras 2.0,推荐,verbose=0,不显示过程,默认等于1显示过程 17 r = pd.DataFrame(model.predict_classes(x_test), columns = [u'预测结果']) 18 pd.concat([data_test.iloc[:,:5], r], axis = 1).to_excel(testoutputfile) 19 net.predict(x_test)
REF:
《数据分析与挖掘实战》
源代码及数据需要可自取:https://github.com/Luove/Data