文章更新于:2020-06-09
- 一、TopN 常见错误
- 二、FileSort 常见错误
- 三、Secondary 常见错误
- 四、其他常见错误
- 4.1、sbt eclipse 打包错误:Not a valid command
- 4.2、sbt eclipse 打包错误:Could not create Eclipse project files
- 4.3、sbt eclipse 打包失败
- 4.4、导入项目到eclipse失败:No projects are found to import
- 4.5、导入项目到eclipse后,出现版本错误:Scala Version Problem
- 4.6、无法运行项目,无法: Run As scala application
- 4.7、代码出现红叉:not found: type SparkConf
- 4.8、程序运行失败:System memory not enough
一、TopN 常见错误
1.1、运行程序失败:Connection refused
当执行程序以后出现以下异常:
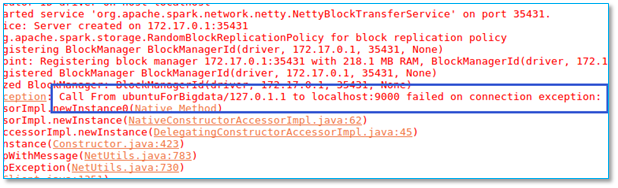
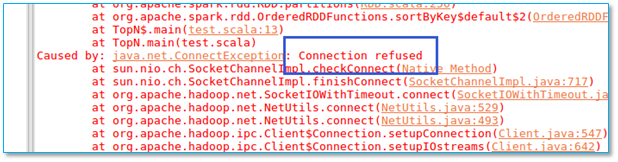
【问题所在】检查是否你程序使用 hdfs:// 地址而你的hadoop 又没有启动。
【解决方法】
你可以启动 hadoop 之后重试,
或者将 hdfs:// 换成 file:// 改用本地存储。
启动hadoop 命令:<hadoop 安装地址>/sbin/start-dfs.sh
查看已启动节点命令:jps
1.2、运行程序失败:Input path does not exist
当执行程序以后出现以下异常:
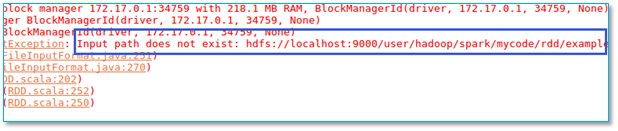
【问题所在】检查你程序中指定的数据输入地址是否已经创建。
【解决方法】
本地创建目录请使用命令:mkdir -p <目录>
hdfs 创建目录请使用命令:hdfs dfs -mkdir -p <目录>
注意:hdfs 创建目录时,如果指定的目录不以斜线”/”开头,则视其为相对地址,
hdfs 默认相对地址为 /user/<用户名>/ 开头
1.3、程序运行无结果:为啥没有输出?
当执行程序以后没有任何结果输出:

【问题所在】一般来讲,有输入才有输出。
【解决方法】
检查你的程序输入文件夹内是否存放了需要的数据文件。
上传本地文件到 hdfs 请使用命令:hdfs dfs -put <文件> <hdfs目录>
1.4、程序运行出错:For input string (600错误)
当执行程序以后出现以下异常:
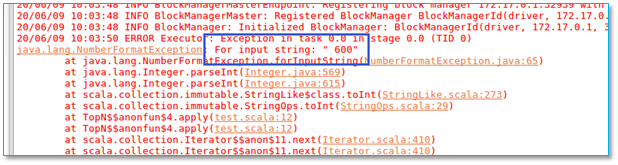
【问题所在】输入数据中600前面多了个空格:
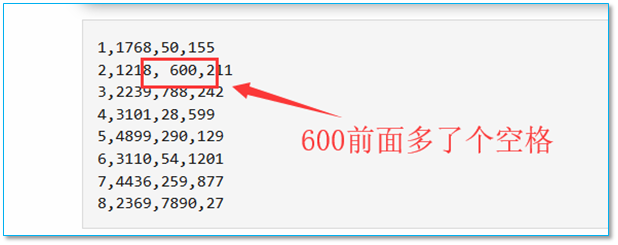
【解决方法】
如果你使用的是本地文件系统,直接修改文件后重新运行程序即可。
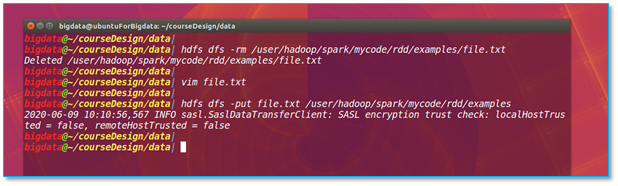
如果你使用的是hdfs文件系统,你需要先删除hdfs上的该文件。
执行命令:hdfs dfs -rm <hdfs文件地址>
然后在本地将600前面的空格删除后重新上传文件至hdfs。
执行命令:hdfs dfs -put <文件名> <hdfs 目录>
二、FileSort 常见错误
2.1、代码出现红叉:编码错误
粘贴代码以后出现红叉如图:
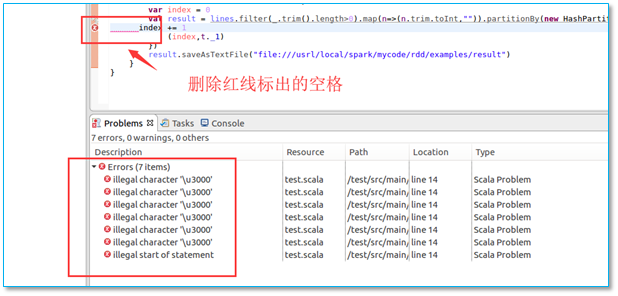
【问题所在】由于编码引起的错误
【解决方法】删掉红线标出的空格即可消除该错误。
2.2、程序运行失败:A master URL must be set in your configuration
当执行程序以后出现以下异常:
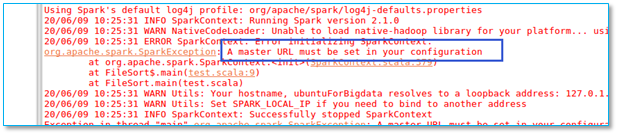
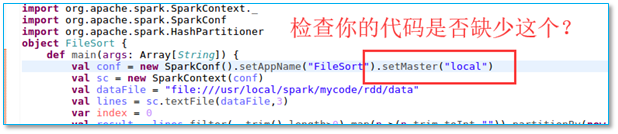
【问题所在】检查你程序的 val conf 行是否缺少指定spark 的启动模式
【解决方法】
在代码中指定spark 的启动模式,如图示。
2.3、程序结果保存失败:Mkdirs failed to create xxx

【问题所在】目测是由于拼写错误导致存储路径产生的权限问题。
【解决方法】指定一个不需要特权的目录

2.4、程序结果保存失败:Output directory already exists
当执行程序以后出现以下异常:
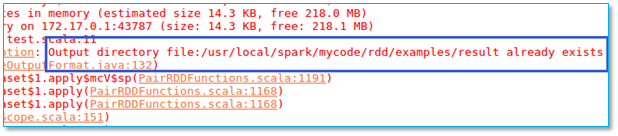
【问题所在】保存结果的文件夹不能提前存在,否则报错。
【解决方法】重复运行前,请先删除之前的结果文件夹。
三、Secondary 常见错误
3.1、程序无法运行:没有 run as scala application
首先,二次排序程序有两个文件,SecondarySort.scala 调用 SecondarySrotKey.scala 文件。
运行时只需运行 SecondarySort.scala 即可。
当执行程序以后出现以下异常:
【问题所在】好奇怪哦,是不是包名指定错误了。
【解决方法】删掉包名指定,或指定为正确的包名。
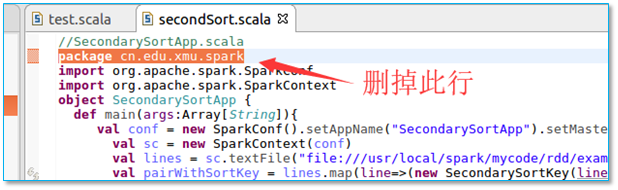
【注意】两个程序源文件都要删掉此行,不然会产生如下错误
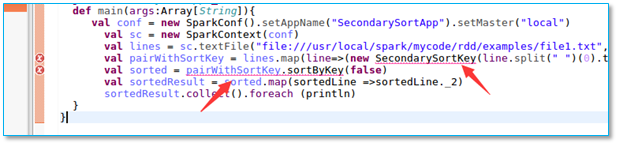
3.2、程序执行错误,空行错误
当执行程序以后出现以下异常:
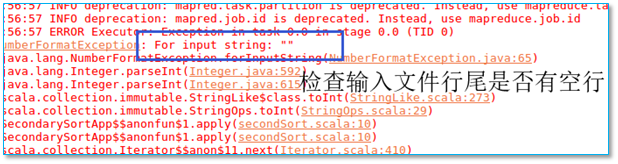
【问题所在】程序输入文件尾部有空行
【解决方法】删掉再行继续。
四、其他常见错误
4.1、sbt eclipse 打包错误:Not a valid command
当打包程序以后出现以下异常:
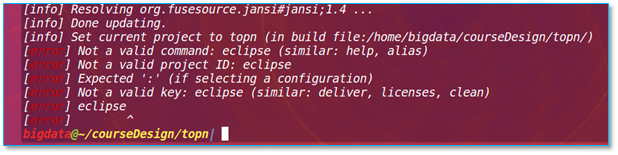
【问题所在】检查你项目目录下 <>/project/build.properties 文件是否存在并内容正确
【解决方法】此文件内写有你 sbt 的版本号,如你有两个sbt 版本比如 0.13 和 1.3.8 选择安装过插件的。
示例如下:
sbt.version=0.13.15
4.2、sbt eclipse 打包错误:Could not create Eclipse project files
当执行程序以后出现错误提示:Not found & Could not create Eclipse project files
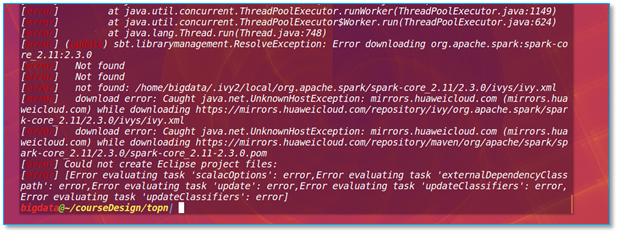
【问题所在】检查你的项目目录下 build.sbt 内各版本号是否写对。
【解决方法】
样例如下:
name := "topn"
version := "1.0"
scalaVersion := "2.11.8"
libraryDependencies += "org.apache.spark" %% "spark-core" % "2.1.0"
4.3、sbt eclipse 打包失败
当打包程序以后出现以下异常:
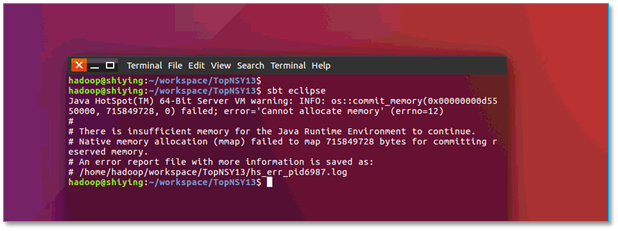
【问题所在】内存不够用了哒。
【解决方法】
如果你同时开启了eclipse,可以先关掉eclipse再行打包。
如果还是不行,考虑增加一下虚拟机的内存。
4.4、导入项目到eclipse失败:No projects are found to import
导入项目到eclipse出现以下异常:
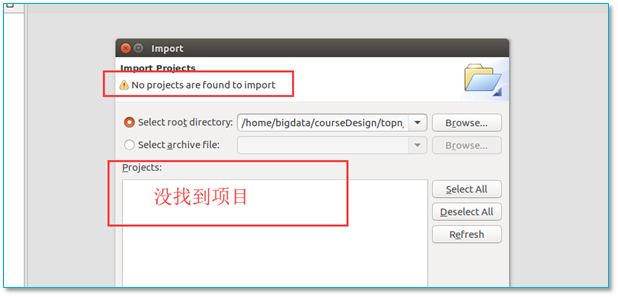
【问题所在】路径指定错误或项目没有打包成功。
【解决方法】先检查你的路径是否指定正确,再考虑其他问题。
路径指定到你打包项目的位置或上一级均可。
如果还是不行,考虑重新打包程序。
4.5、导入项目到eclipse后,出现版本错误:Scala Version Problem
当导入程序以后,出现以下异常:
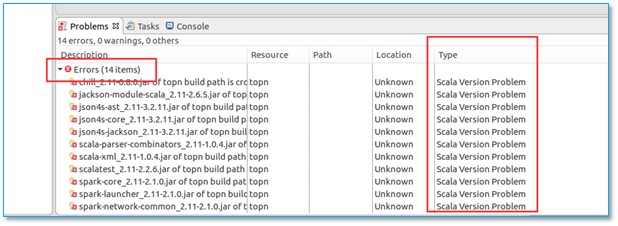
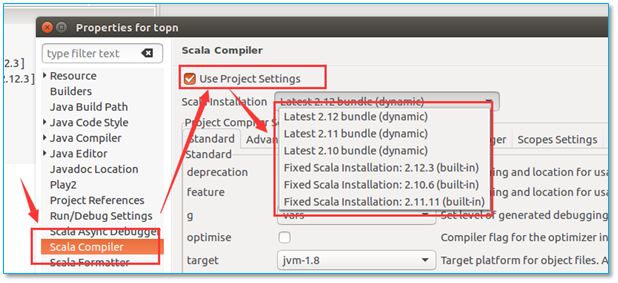
【问题所在】项目默认的scala版本与系统安装的不匹配。
【解决方法】更改你的scala 编译器版本为你机器上用的版本即可。
项目名上右键选择 properties ,然后更改。
4.6、无法运行项目,无法: Run As scala application
当意图运行程序时出现以下异常:
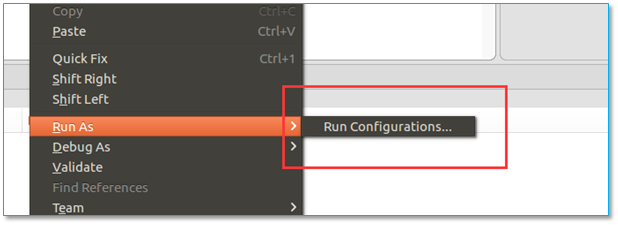
【问题所在】文件类型不对,或源代码中包名指定错误。
【解决方法】先检查你的源代码文件名是否以 .scala 为结尾。
再考虑代码中是否包名指定错误。
4.7、代码出现红叉:not found: type SparkConf
当编写好代码时,出现以下异常:
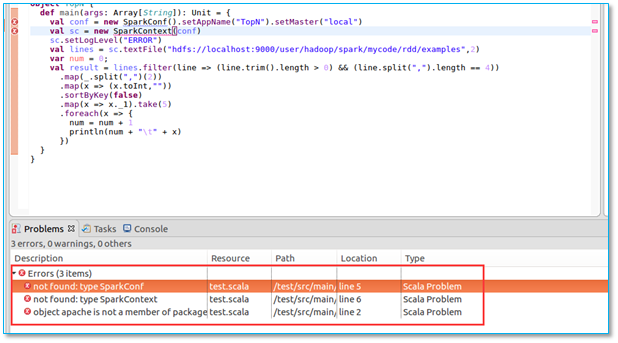
【问题所在】没有对应的库文件或其他依赖文件。
【解决方法】检查你的项目打包声明文件里面是否声明了 spark 依赖信息。
比如当你只声明以下信息的时候,依然可以打包成功,但是无法使用 SparkConf
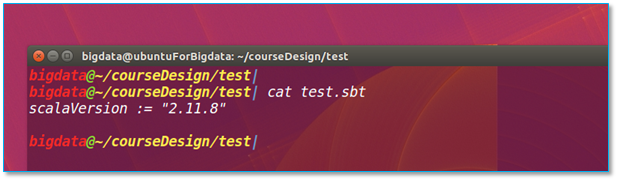
这种情况,需要你在声明文件中加入所需依赖信息,并重新打包。
然后eclipse 中刷新项目即可。
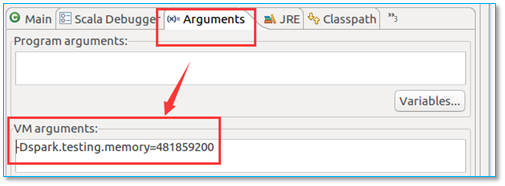
4.8、程序运行失败:System memory not enough
当你运行程序时,出现以下异常信息:
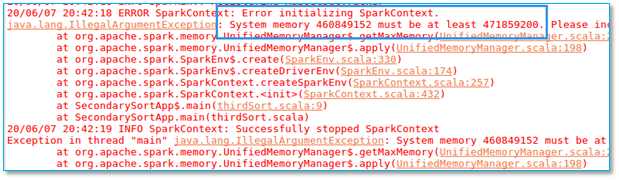
【问题所在】内存不够用哒。
【解决方法】
这种情况你可以在代码中加入:conf.set("spark.testing.memory", "477859200") 来解决。
数字比报错要求的大即可。
也可以在项目设置中添加参数:-Dspark.testing.memory=481859200 来解决。
如下图所示:
<全文完>