第三讲:Loss Functions and Optimization
上一个lecture留的问题:如何选择W
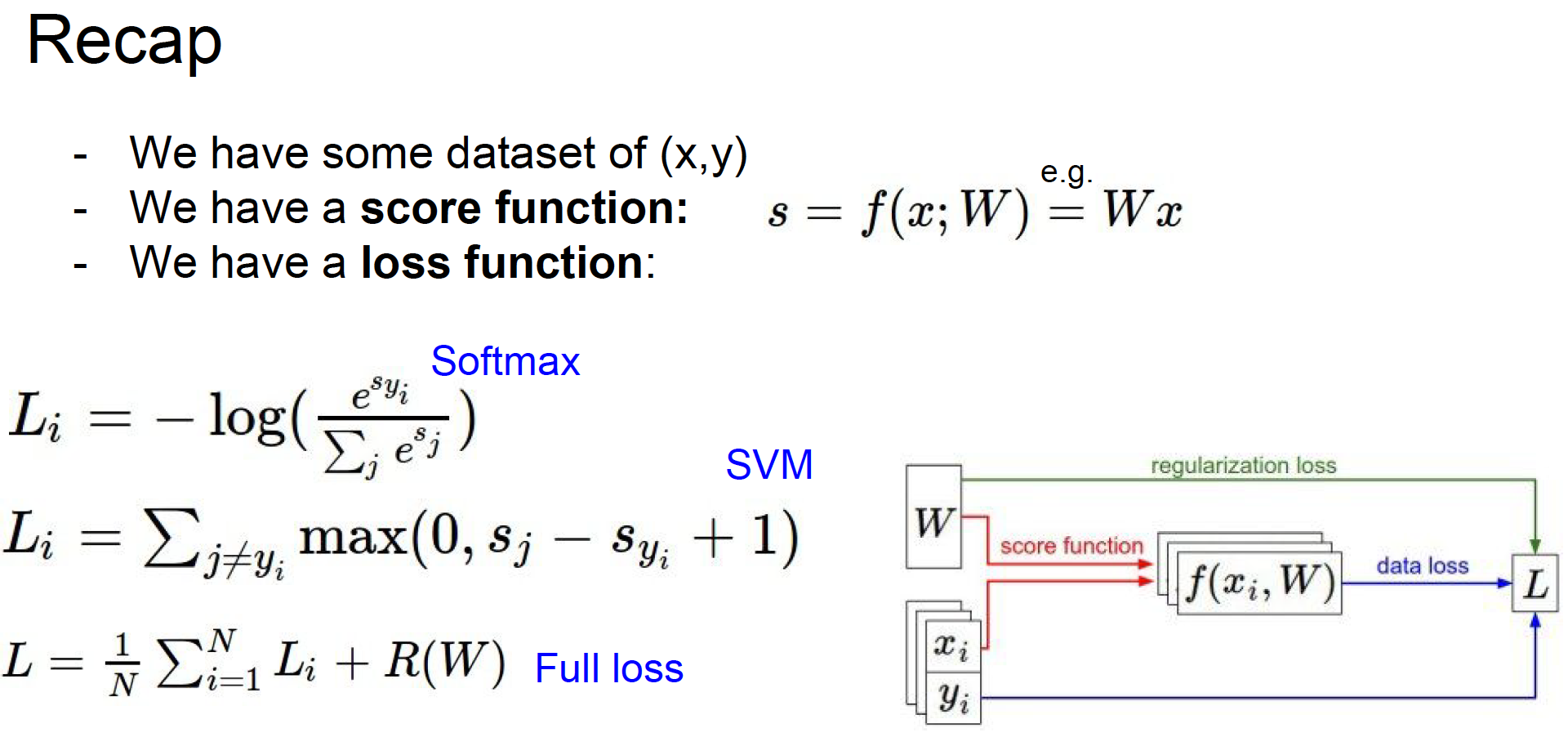
Loss function:对比结果和真正结果,判断W的好坏
optimization procedure:从W矩阵所有可行域中选择使得结果最好的值的过程
Loss function
different loss functions for image classification problem

x其实是图片每个像素点构成的数据集
上图final LOSS的公式其实算一个通用公式,适用于包括CV以及其他许多领域。
GOAL:find the W matrix that minimizes the LOSS on your training data
-
multi-class SVM loss

multi-class SVM loss公式解释:
* Syi是正确分类的标签,代表第i个样本真实分类的分数。
* 对于某一个example,对于所有错误分类,如果正确分类分数-错误分类分数 > defined security margin --> loss = 0
* 将该example的每个错误分类的loss求和就得到这个example的final loss
* 该分类器的final loss是每个example final loss求平均
* Final loss 我们的分类器对这个dataset训练的多号的一个量化衡量指标
* 又叫做hinge loss
(这边我理解的margin对应SVM的硬间隔,因为目前还没有懂为什么叫SVM loss)
Q1:what happens to loss if car scores change a bit?
A :不变,除非超过defined security margin
Q2:what is the min/max possible loss?
A :min = 0, max=infinity
Q3:An initialization W is small so all s≈0. what is the loss?
A :loss = N -1,N is number of class
Q4:what if the sum was over all classes?(including j = y_i)
A :loss + 1
Q5:what if we used mean instead of sum?
A :不会改变,只是整个损失函数缩小了一个倍数
Q6: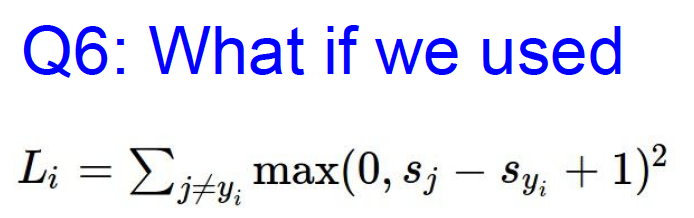
A :会变成different loss function,用一种非线性的方法。

* little summary
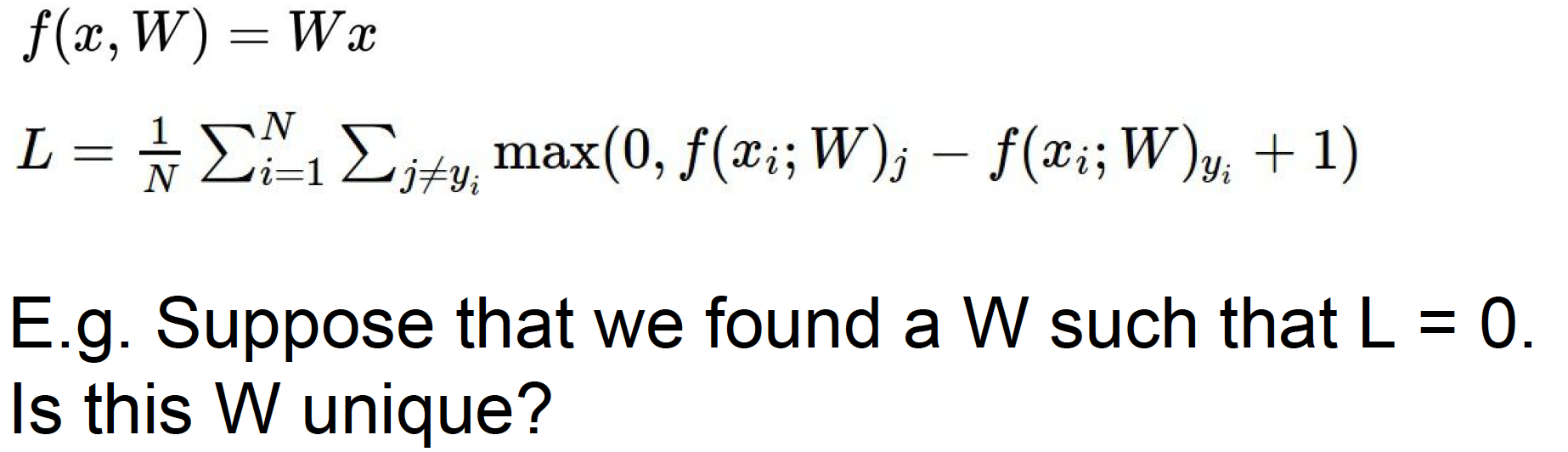
对于图中问题,W不是唯一的,2W也可以使得L=0。 -
Regularization
对于所有Loss符合要求的分类器,我们应该如何选择?
问题1:过度关注data loss的数值会容易出现过拟合。
解决方法就是引入正则化,目的使得模型更简单,选择更简单的W。这也提现了Occam's Razor理论。
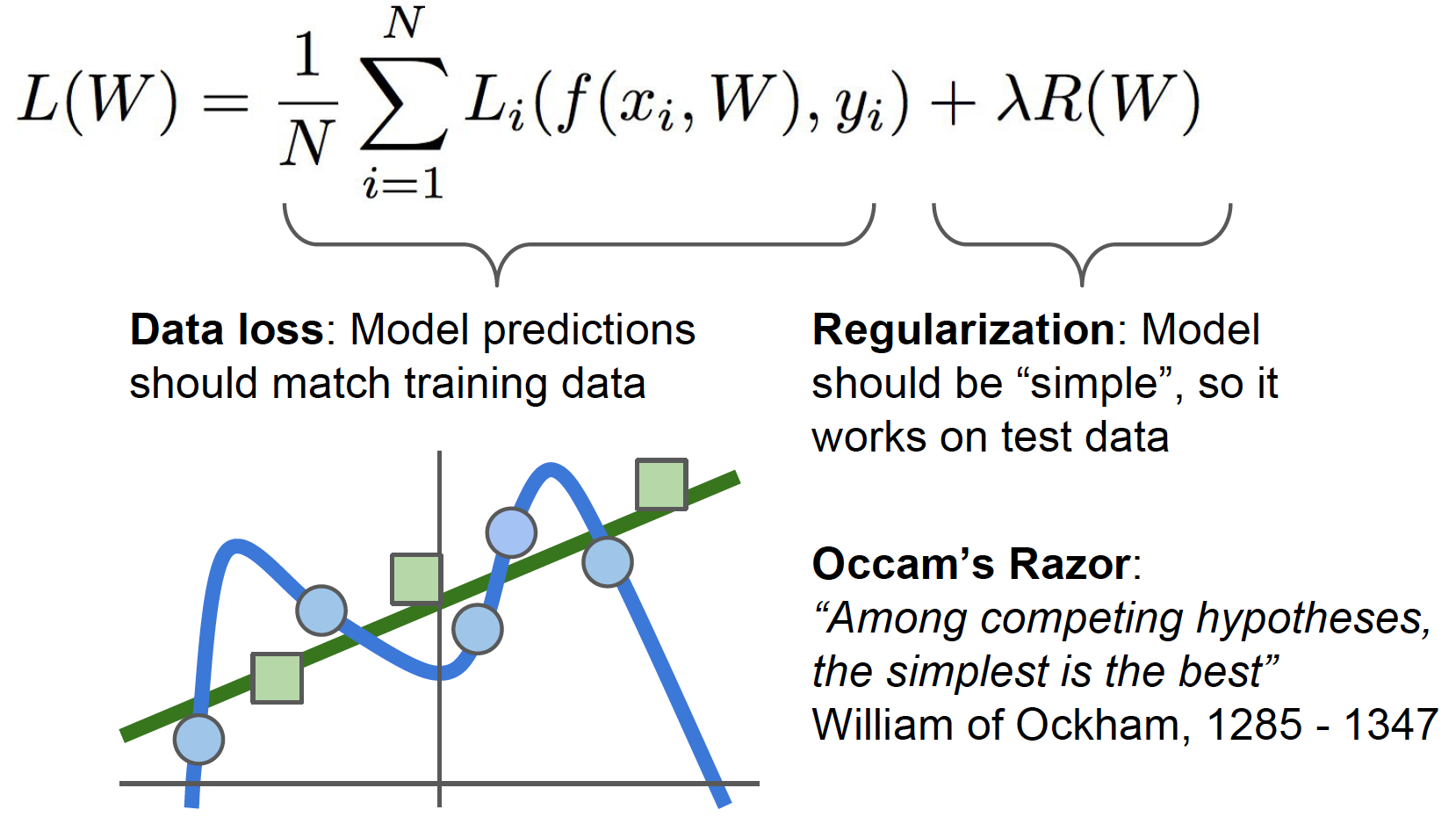
下面是加入正则化的loss function,包括一个超参数。常见的是L2正则或权重衰减(weight decay)

Q:L2如何衡量模型复杂度?
L2正则的作用是更好的传递出x中不同元素值的影响,更好的robust
但是L1正则有完全相反的作用,在这个情况的选择的W也不同,L1更喜欢稀疏解一些 -
Softmax classifier(Multinomial logistic regression)
SVM classifier中并没有解释那些得分是什么意思,在这个分类器中将用到score计算概率分布。
target概率分布式正确的分类概率为1,其他分类概率为0。这个分类器的目的是将概率分布尽量匹配目标概率分布,即尽量为1。
在这边选择了最大似然的方法,等同于最小化loss function。

Q1:what is the min/max possible loss L_i?
A :min=0,max=infinite
Q2:Usually at initialization W is small so all s ≈ 0. What is the loss?
A :ln(C),这是一个纠错机制,应该在第一次迭代的时候就检查 -
Softmax VS. SVM
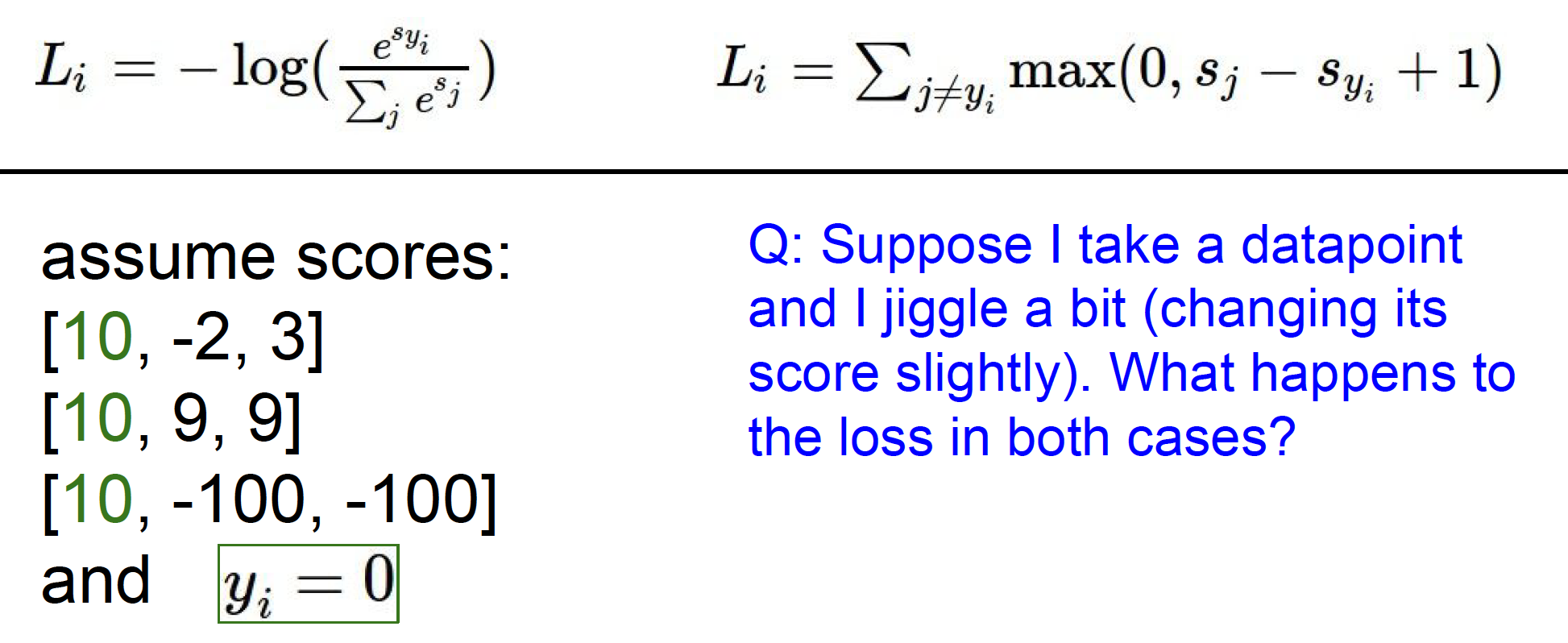
SVM只要得到这个数据点超过阙值并且正确分类,Softmax一直试图不断提高每个数据点。
Optimization
- strategy 1: random search, very bad idea
- strategy 2: Follow the slope
gradient: the vector of partial derivative along each dimension in the multi-variable setting, has the same shape as x。指向函数增长最快的方向
slope:dot product of gradient with the unit vector describing this direction
梯度就是计算当前点的每个方向上的斜率,如果斜率为负,就沿这个方向- 有限差分法 finite differences,属于数值梯度(numerical gradient)。
approximate, 非常慢,因为要计算每个维度上的gradient, easy to write - 微积分,属于解析梯度(analytic gradient)

exact, fast but error-prone(容易出错)
在实际操作中,通常使用analytic gradient计算梯度,使用numerical gradient来做unit检查-->叫做gradient check。
- 有限差分法 finite differences,属于数值梯度(numerical gradient)。
Gradient Descent
<img src="https://images2018.cnblogs.com/blog/919889/201802/919889-20180219223359900-848494689.png" width=400 height=300 />
梯度下降算法:首先初始化W为随机值,然后就算loss和gradient,向负梯度方向更新权重,一直迭代直到收敛。就是用每一步的梯度决定下一步的方向
step-size(learning rate):步长,是个超参数
Stochastic Gradient Descent (SGD)
 前面我们定义了整体数据集的loss是总体loss的平均,但是实际中样本数N有可能很大,这时由于计算成本太高,所以实际中常常采用SGD
SGD并非计算整个数据集的loss和graident,而是在每一次迭代中取一小部分训练样本-->minibatch(小批量)
前面我们定义了整体数据集的loss是总体loss的平均,但是实际中样本数N有可能很大,这时由于计算成本太高,所以实际中常常采用SGD
SGD并非计算整个数据集的loss和graident,而是在每一次迭代中取一小部分训练样本-->minibatch(小批量)
Image Features
实际应用中不会直接将图片像素的原始像素数据传入分类器,而是使用two-stage:计算图片中的各种特征代表(feature-transform),得到图像特征描述,这个会作为线性分类器的输入源。
why?可以适用于无法线性分类的数据集
point:找到正确的feature transform
* color histogram
* histogram of Oriented Gradients(HoG)
测量图片中边缘的局部方向
* bag of words
Step1:Build codebook
Step2:Encode images