文章伪原创工具制作
什么是伪原创?
简单点来说,就是将原创文章进行加工后得到一篇意思和原文章相近的原创文章。常见于网站发文,自媒体创作,媒体搬运等。因为个体用户创作经历有限,而为了达到目的需要采取伪原创手法
常见伪原创平台
- 5118
- 奶盘
- 小发猫
有付费平台也有免费的,效果可能差强人意吧
伪原创原理
最为正途的,当然就是AI中,自然语言处理分支。利用语言模型进行 分词,计算词义相似度,DNN语言模型(句子通顺度)等等一系列功能整合之后而达到目的。
核心特点:
- 近义词,同义词替换
- 保证句子通顺度
实际应用
有意思的是,我用了两种方式各研究了一下。
- 第一种,自然语言处理,通过使用百度AI的NLP开发了一个开源项目。项目地址:language-ai , 这种可以达到目的,但很快我就发现了问题,分词,DNN语言模型倒还好,但是同义词,近义词替换这个太影响性能,而且对于同义词库的要求比较高。简单来说,就是伪原创速度慢
- 第二种,采用语言翻译,我们学习过英语都知道,一次多义很正常 ,这就是同义词最常见的地方。所以我们将中文翻译成英文,就会得到意思相近的文章,而且可能每篇都会不一样。然后将英文再翻译会中文,就能完成同义词,近义词替换了,并且效率很高,几千字的文章也不用多久。
第二种方式虽然有点投机取巧,但在文章伪原创上却是殊途同归
工具开发
素材:
- Python3.8
- PyQt5
- 其他依赖包
实操
- 先用PyQt5的designer画一个界面
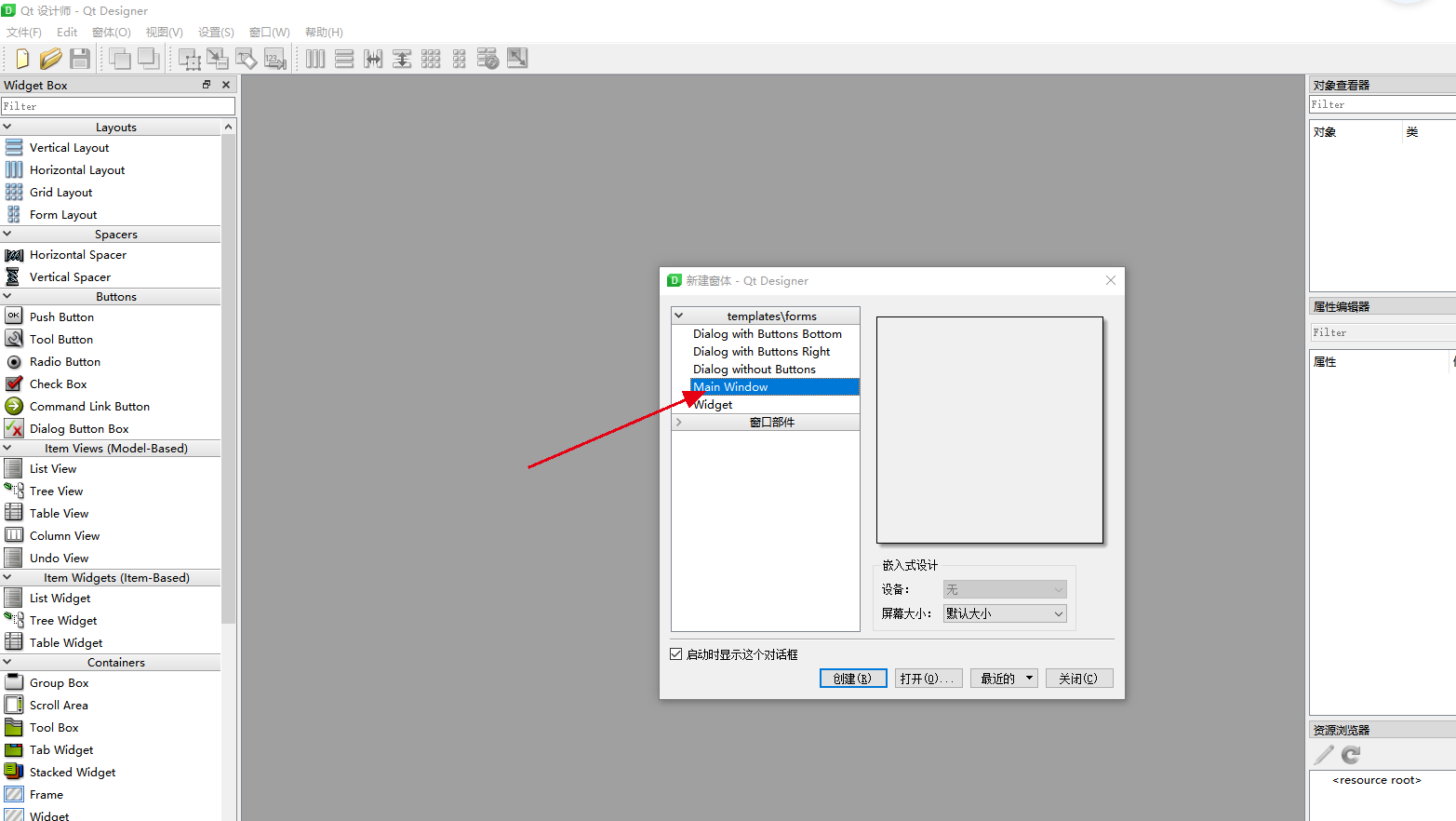
这里大致画一下界面
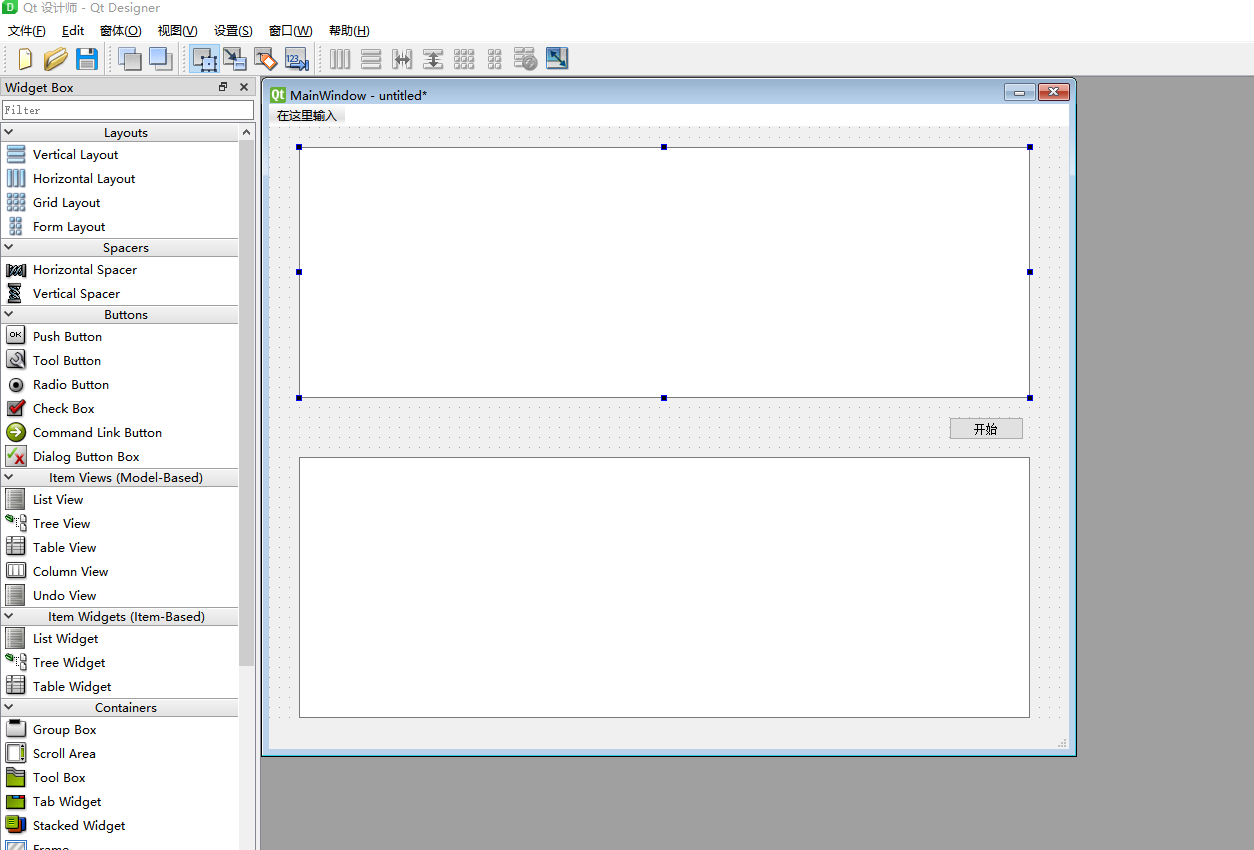
成品效果如下

- 生成py文件
画好之后,按Ctrl + s 保存成 **.ui文件
在ui文件在所在目录打开cmd, 输入生成.py文件命令: pyuic5 -o fast-artcile.py fast-article.ui
这样就会看到一个同名称的py文件,这时候将py拷贝到项目工程中
- 调用谷歌翻译
初始化请求头,设置tkk值等
def __init__(self):
self.url = 'https://translate.google.cn/translate_a/single'
self.TKK = "434674.96463358" # 随时都有可能需要更新的TKK值
self.header = {
"accept": "*/*",
"accept-language": "zh-CN,zh;q=0.9",
"cookie": "NID=188=M1p_rBfweeI_Z02d1MOSQ5abYsPfZogDrFjKwIUbmAr584bc9GBZkfDwKQ80cQCQC34zwD4ZYHFMUf4F59aDQLSc79_LcmsAihnW0Rsb1MjlzLNElWihv-8KByeDBblR2V1kjTSC8KnVMe32PNSJBQbvBKvgl4CTfzvaIEgkqss",
"referer": "https://translate.google.cn/",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36",
"x-client-data": "CJK2yQEIpLbJAQjEtskBCKmdygEIqKPKAQi5pcoBCLGnygEI4qjKAQjxqcoBCJetygEIza3KAQ==",
}
self.data = {
"client": "webapp", # 基于网页访问服务器
"sl": "auto", # 源语言,auto表示由谷歌自动识别
"tl": "vi", # 翻译的目标语言
"hl": "zh-CN", # 界面语言选中文,毕竟URL都是cn后缀了,就不装美国人了
"dt": ["at", "bd", "ex", "ld", "md", "qca", "rw", "rm", "ss", "t"], # dt表示要求服务器返回的数据类型
"otf": "2",
"ssel": "0",
"tsel": "0",
"kc": "1",
"tk": "", # 谷歌服务器会核对的token
"q": "" # 待翻译的字符串
}
with open('token.js', 'r', encoding='utf-8') as f:
self.js_fun = execjs.compile(f.read())
翻译, 需要注意,返回的内容是个数组,需要将数组拼接回字符串
def query(self, q, lang_to=''):
self.data['q'] = urllib.parse.quote(q)
self.data['tk'] = self.js_fun.call('wo', q, self.TKK)
self.data['tl'] = lang_to
url = self.construct_url()
req = urllib.request.Request(url=url, headers=self.header)
response = json.loads(urllib.request.urlopen(req).read().decode("utf-8"))
# 拼接数据
targetText = []
results = response[0]
for result in results:
if result[0]:
targetText.append(result[0])
# 将数组转成字符
str = '
'.join(targetText)
originalText = response[0][0][1]
originalLanguageCode = response[2]
print("翻译前:{},翻译前code:{}".format(originalText, originalLanguageCode))
print("翻译后:{}, 翻译后code:{}".format(str, lang_to))
return originalText, originalLanguageCode, str, lang_to
- 给界面中的按钮添加事件
# 绑定 开始 事件
self.pushButton.clicked.connect(self.startTrans)
- 添加事件处理方法
def startTrans(self):
# 这里写处理逻辑
# 1. 获取用户输入的源文本
# 2. 将文本 中 译 英, 然后 英 译 中
# 3. 将伪原创之后的内容设置回结果输入框即可
pass
这样,一个伪原创工具就完成啦
项目源码
项目源码,托管于github, 部份谷歌翻译内容,参考GitHub中的项目
项目成品
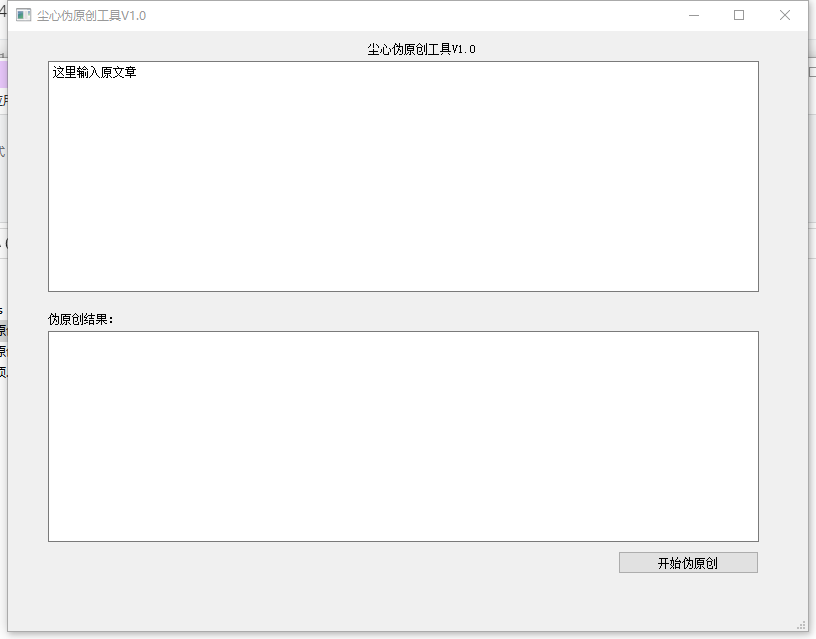

如果有一闪而过的黑窗口,那应该是打包成exe的时候,参数没填好
成品下载
方式一:关注vx公~号, GitHub严选 , 回复 “伪原创”即可下载,不限次数,永久免费。如果tkk失效,可回来看项目更新。
方式二:可自己根据源码包进行打包
温馨提示
如果报毒,很正常,只要没有发布在360,安全管家等安全平台就会报毒。大家添加信任,或者暂时关闭杀毒软件即可