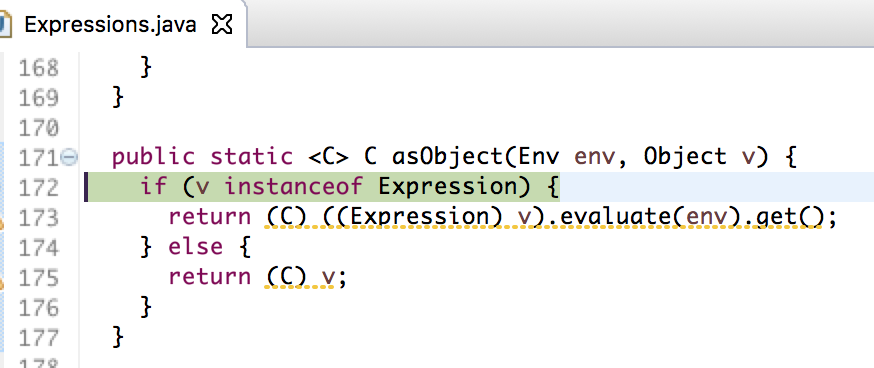
总结:
这个javacc感觉比较复杂,在于stanfordnlp中
CoreMapExpressionExtractor这个太过复杂,只需要搞清楚如何写正则就行了
格式就是
$DAYOFWEEK = "/monday|tuesday|wednesday|thursday|friday|saturday|sunday/"
$TIMEOFDAY = "/morning|afternoon|evening|night|noon|midnight/"
ENV.defaults["ruleType"] = "tokens"
{
ruleType: "tokens", #类型
pattern: ( $DAYOFWEEK ), #正则本身
result: "TIME" #如果匹配后如何生成nlg
}
一、javacc说明文档

- >>>红色部分
parser_begin 和 parser_end
但是这也是一个声明实例变量的好场所,该实例变量将由您结果中的 Java 语句引用。如果您喜欢,甚至可以在这里插入 Java main() 过程,并且使用它来构建独立的应用程序,以启动和测试您正在生成的解析器
- >>>绿色部分
绿色部分直接调用黄色函数
该操作作为方法 Parser_1.integerLiteral() 的一部分产生。每当解析器遇到整数时,都执行该操作
- >>>黄色部分函数
声明了类型 Token (JavaCC 的内置类)的局部变量 t 。当在输入流中遇到整数时会 触发 该规则,该整数(象文本一样)的值被赋给实例变量 t.image 。
- >>>黑色部分
举个例子
TOKEN : { < NUMBER : ([”0”-”9”])+ > }
说明([”0”-”9”])+. The [”0”- ”9”] part is a regular expression that matches any digit, that is, any character whose unicode encoding is between that of 0 and that of 9. A regular expression of the form (x)+ matches any sequence of one or more strings, each of which is matched by regular expression x. So the regular expression ([”0”-”9”])+ matches any sequence of one or more digits.
- >>>执行流程
1. 最上面的方法 simpleLang() 调用 integerLiteral() 。
2. integerLiteral() 希望在输入流中立即遇到一个整数,否则该表达式将无效。为了验证这一点,它调用记号赋予器(Tokenizer.java)以返回输入流中的下一个记号。记号赋予器穿过输入流,每次检查一个字符,直到它遇到一个整数或者直至文件结束。如果是前者,则以 <INT> 记号将值“包”起来;如果是后者,则当作 <EOF> ;并将记号返回给 integerLiteral() 做进一步处理。如果记号赋予器未遇到这两个记号,则返回词法错误。
3. 如果记号赋予器返回的记号不是整数记号或 <EOF> ,那么 integerLiteral()抛出 ParseException ,同时解析完成。
4. 如果它是整数记号,表达式仍然可能是有效的, integerLiteral() 再次调用记号赋予器以返回下一个记号。如果返回 <EOF> ,则由单个整数构成的整个表达式都是有效的,解析器将控制返还给调用应用程序。
5. 如果记号赋予器返回加号或减号记号,则表达式仍然是有效的,integerLiteral() 将最后一次调用记号赋予器,以寻找另一个整数。如果遇到一个整数,则表达式是有效的,解析器将完成工作。如果下一个记号不是整数,则解析器抛出异常。
二、stanfordnlp TokenSequenceParser.jj
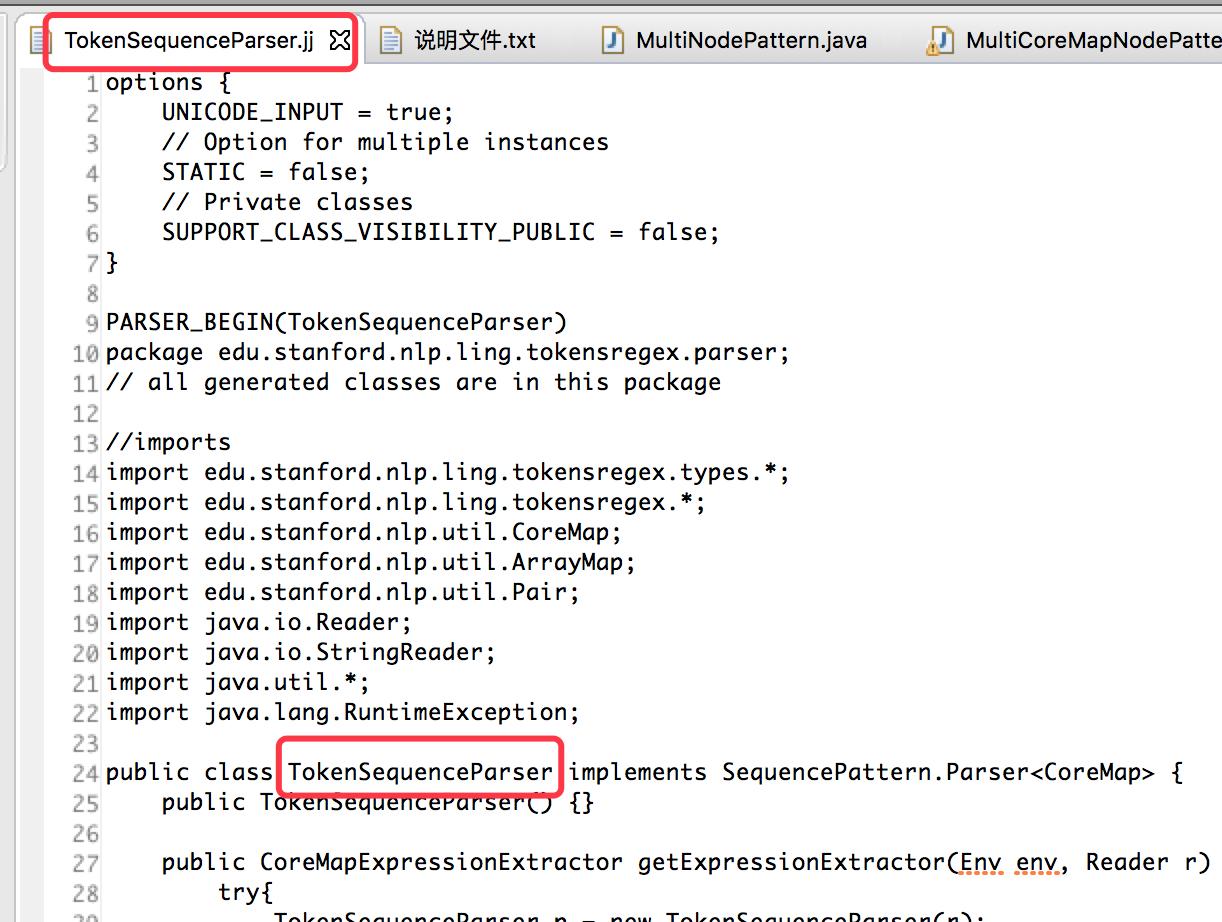
然后直接调用 new TokenSequenceParser
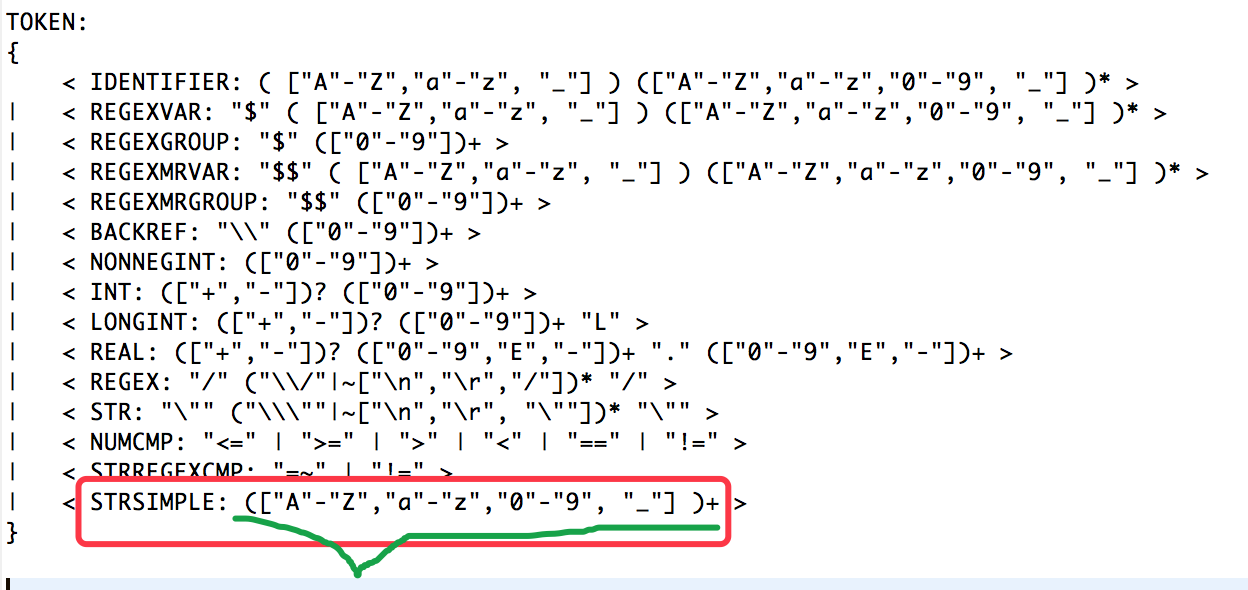
看看上面定义的规则如何使用呢?如下
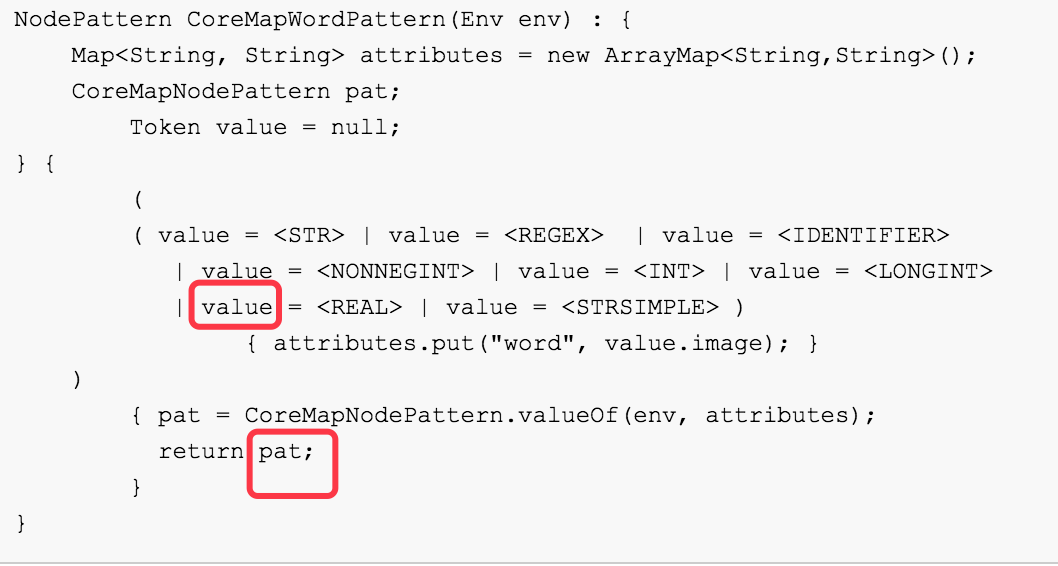
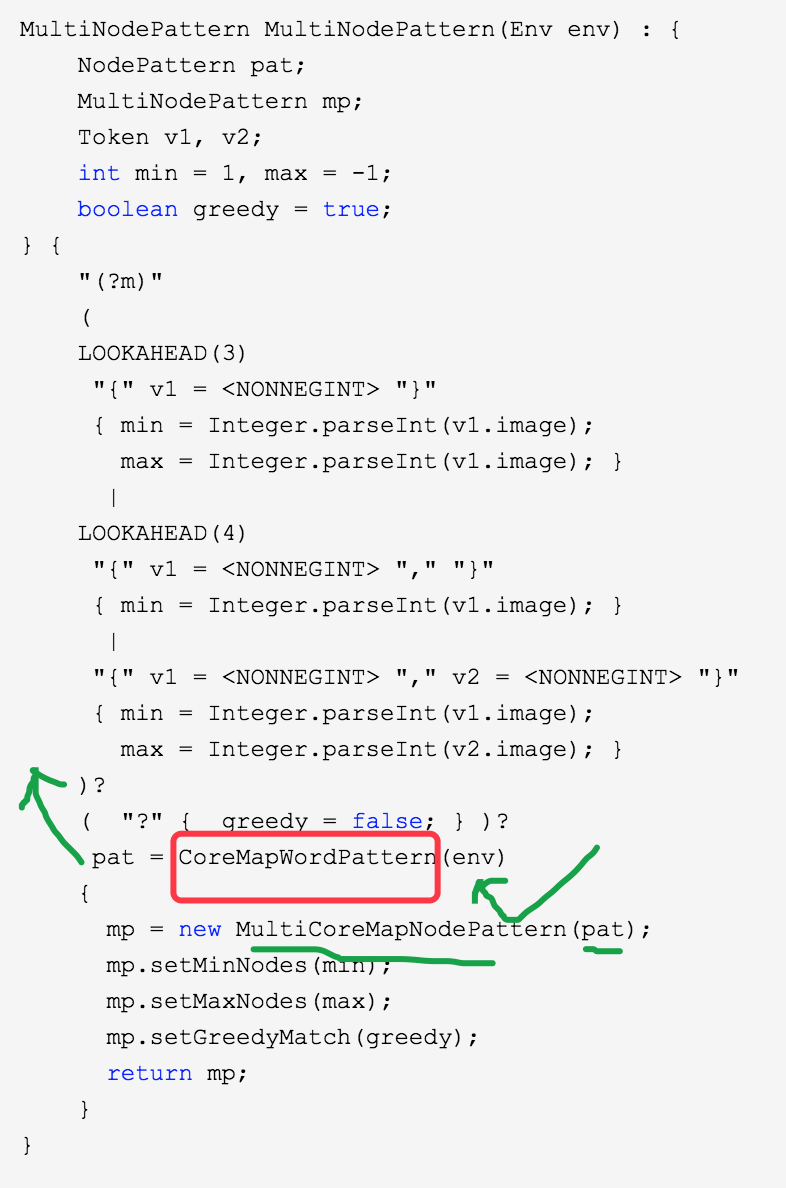
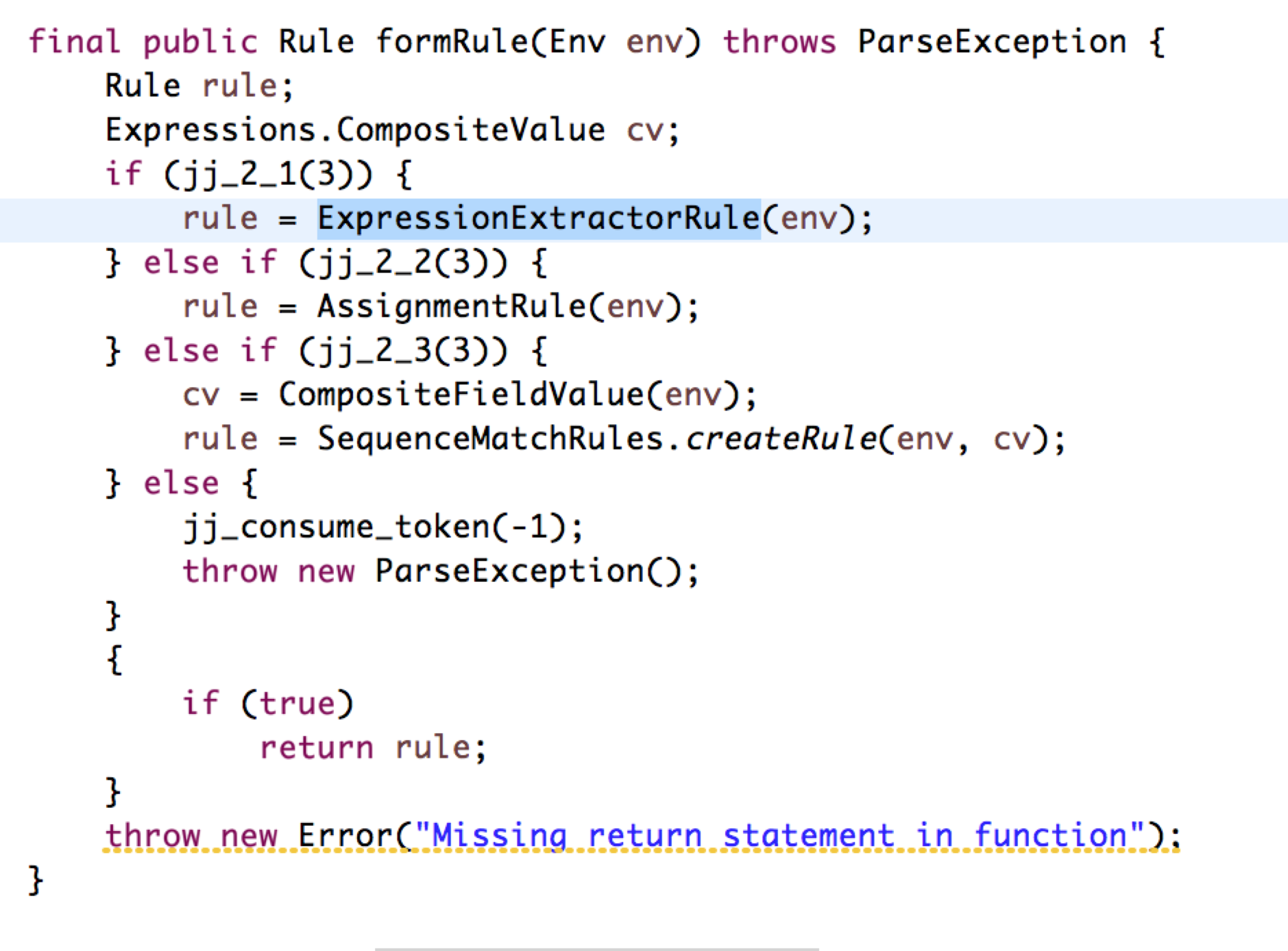
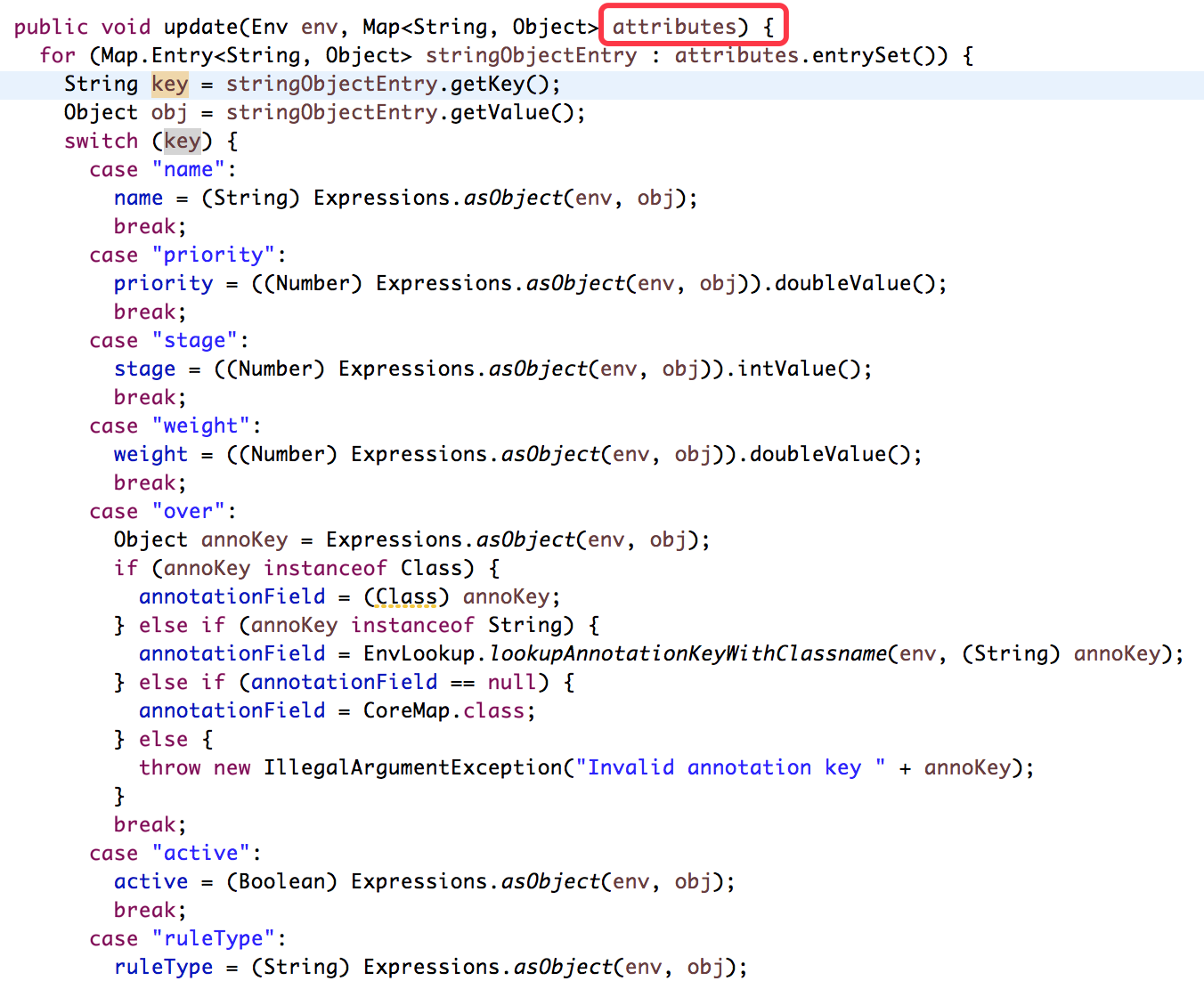
最关键的函数是如下