1.背景
作为国内领先的出行大数据公司,高德地图拥有众多的用户和合作厂商,这为高德带来了海量的出行数据,同时通过各个渠道,这些用户也在主动地为我们提供大量的反馈信息,这些信息是需要我们深入挖掘并作用于产品的,是高德地图不断进步和持续提升服务质量的重要手段。
本文将主要介绍针对用户反馈的文本情报,如何利用机器学习的方法来提高大量用户数据的处理效率、尽可能实现自动化的解题思路。
先来解释一下重点名词。
情报:是一种文本、图片或视频等信息,用来解决高德地图生产或者导航中的具体问题,本质上是指与道路或交通相关的知识或事实,通过一定空间和时间通知给特定用户。
用户反馈:是指用户借助一定的媒介,对所使用的软件等提供一些反馈信息,包括情报、建议和投诉等。
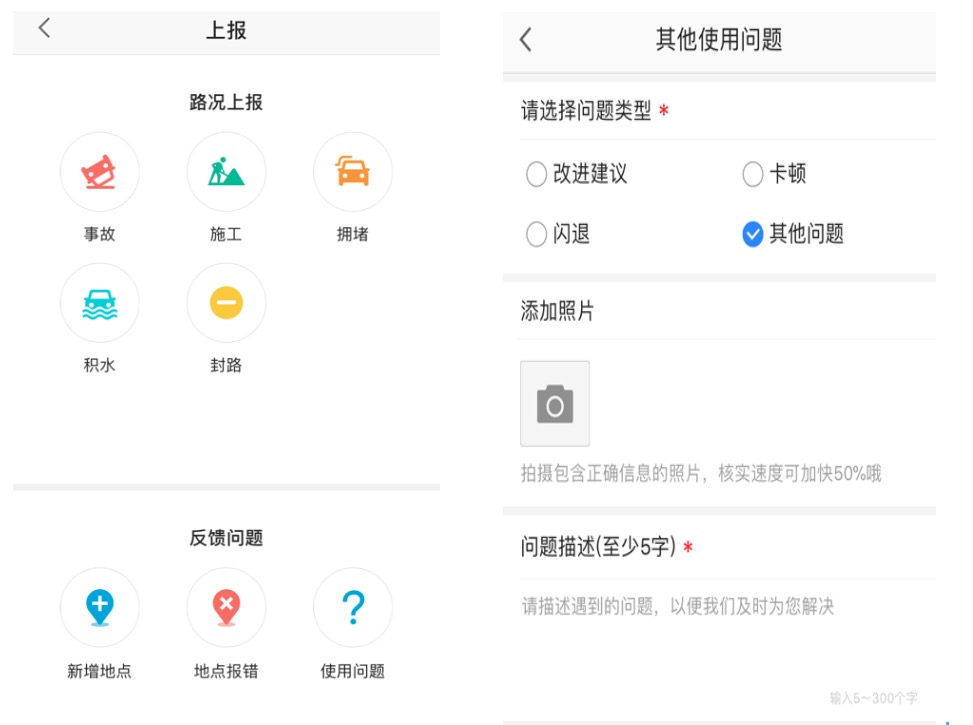
典型的用户反馈类型和选项如下图所示:
2.问题及解法
用户反馈的方式可以通过手机的Amap端、PC端等进行上报,上报时选择一些选择项以及文本描述来报告问题,以下是一个用户反馈的示例,其中问题来源、大类型、子类型和道路名称是选择项,用户描述是填写项,一般为比较短的文本。这些也是我们可以使用的主要特征。

每个用户在上报了问题之后,均希望在第一时间内问题能够得到解决并及时收到反馈。但是高德每天的用户反馈量级在几十万,要想达到及时反馈这个目标非常的不容易。
针对这些用户反馈信息,当前的整体流程是先采用规则进行分类,其中与道路相关的每条反馈都要经过人工核实,找到用户上报的问题类型和问题发生的地点,及时更新道路数据,作用于导航。
针对一条反馈的操作需要经过情报识别、情报定位、情报验证等环节:
1) 情报识别主要是判断问题类型即给情报打标签:①分析用户上报的信息包括问题来源、大类型、子类型和用户描述等,②查看上传的图片资料,包括手机自动截图和用户拍照;
2) 情报定位主要是找到问题发生的位置信息即定位坐标:①分析用户反馈问题时戳的位置点即戳点的有效性,②查看用户上报问题时车辆行驶的位置即自车位置,③分析用户使用高德软件过程中的规划和实走轨迹等日志信息;
3) 情报验证:通过以上两步确定了情报标签和位置坐标,此环节需要验证情报标签(含道路名称):①分析影像和大数据热力图或路网基础数据,②查看用户上传的资料和采集的多媒体图片资料。
整个业务处理流程如下图所示:
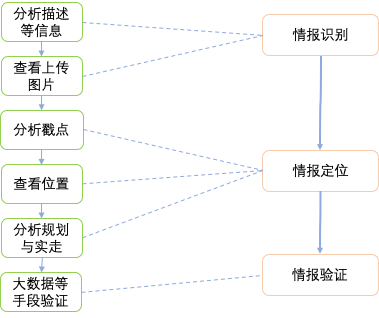
在处理用户反馈问题整个过程秉持的原则是完全相信用户的问题存在。若用户上报的信息不足以判断问题类型和问题发生地点,则会尽量通过用户规划和实走轨迹等日志信息进行推理得出偏向用户的结论。
目前整个用户反馈问题处理流程存在的主要问题有:规则分发准确率低,人工核实流程复杂、技能要求高且效率低,去无效误杀严重等。
为了解决以上问题,我们希望引入机器学习的方法,以数据驱动的方式提高作业能力。在进行机器学习化的探索过程中,我们首先对业务进行了拆解及层级化分类,其次使用算法来替代规则进行情报分类,再次工程化拆解人工核实作业流程为情报识别、情报定位和情报验证等步骤,实现单人单技能快速作业,最后将工程化拆解后的情报识别步骤使用算法实现其自动化。
3.机器学习解题
3.1 业务梳理与流程层级化拆解
原始的用户反馈问题经由规则分类后,再进行人工情报识别、定位和验证,最终确认问题及其所在是属于近百种小分类项中的哪一个,进而确定上一级分类以及整个层级的对应关系。
由此可以看出,整个问题处理流程只有一个步骤,处理过程相当复杂,对人工的技能要求很高,且效率低下。而且一千个人眼中就有一千个哈姆雷特,个人的主观性也会影响对问题的判断。
针对这种情况,我们对原有业务流程进行梳理和拆解,希望能够利用机器学习和流程自动化等方式解决其中某些环节,提升整体问题处理的效率。
首先进行有效情报和无效情报的分类即去无效,接着将整个流程拆解为六个层级,包括业务一级、业务二级、业务三级、情报识别、情报定位和情报验证。
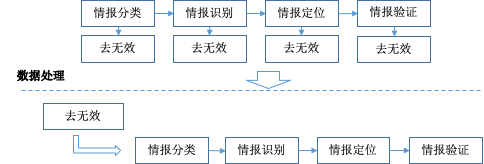
如上图所示,拆解后的前三个级别为情报分类环节,只有后三个级别需要部分人工干预,其他级别均直接自动化处理。这样通过层级化、自动化和专人专职等方法极大地简化了问题同时提高了效率。
3.2 业务与模型适配
我们可以看到用户反馈中既有选择项又有输入项,其中选择项如问题来源等都是有默认值的,需要点击后选择相应细分项,用户不一定有耐心仔细选择,有耐心的用户可能会由于不知道具体分类标准而无法选择正确的分类。而用户描述,是需要用户手动输入的内容,是用户表达真实意图的主要途径,是一条用户反馈当中最有价值的内容。
用户描述一般分为三种情况:无描述、有描述但无意义的、有描述且有意义的。前两种称之为无效描述,后一种称之为有效描述。
根据业务拆解结果,业务流程第一步即为去无效,在这之后,我们将有效、无效描述的用户反馈进行区分,分别建立相应的流程进行处理。
1) 有效描述的用户反馈,逐级分类,第一级分为数据、产品、转发三类,其中产品和转发两类直接进行自动化处理,数据类别会在第二级中分为道路和专题,专题是指非道路类的限行、步导、骑行等。
2) 无效描述的用户反馈,进行同样的分类,并走一样的流程,但是样本集和模型是不同的,并且最后没有算法处理的步骤,直接走人工或者规则处理。
3) 最终根据实际业务需要进行层层拆解后形成了下图所示的业务与模型适配的结构。
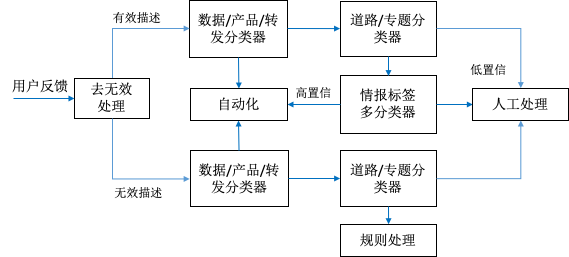
由以上分析可见,情报分类和情报识别均为多分类的文本分类问题,我们针对各自不同的数据特点,进行相应的操作:
情报分类,每一级类别虽不同,但是模型架构却是可以复用的,只需要有针对性的做微小改动即可。且有以前人工核实过(包含情报识别、情报定位、情报验证等过程)具有最终结果作为分类标签的历史数据集作为真值,样本集获得相对容易。
情报识别,其分类标签是在情报验证之前的中间结果,只能进行人工标注,并且需要在保证线上正常生产的前提下,尽量分配人力进行标注,资源非常有限。所以我们先在情报分类数据集上做Finetuning来训练模型。然后等人工标注样本量积累到一定量级后再进行情报识别上的应用。
3.3 模型选择
首先,将非结构化的文本用户描述表示成向量形式即向量空间模型,传统的做法是直接使用离散特征one-hot表示,即用tf-idf值表示词,维度为词典大小。但是这种表示方式当统计样本数量比较大时就会出现数据稀疏和维度爆炸的问题。
为了避免类似问题,以及更好的体现词语之间的关系如语义相近、语序相邻等,我们使用word embedding的方式表示,即Mikolov提出的word2vec模型,此模型可以通过词的上下文结构信息,将词的语义映射到一个固定的向量空间中,其在向量空间上的相似度可以表示出文本语义上的相似度,本质上可以看作是语境特征的一种抽象表示。
其次,也是最重要的就是模型选择,相对于传统的统计学习方法复杂的特征工程步骤,深度学习方法更受青睐,NLP中最常用的是循环神经网络RNN,RNN将状态在自身网络中循环传递,相对于前馈神经网络可以接受更广泛的时间序列结构输入,更好的表达上下文信息,但是其在训练过程中会出现梯度消失或梯度爆炸等问题,而长短时记忆网络LSTM可以很好的解决这个问题。
3.4 模型架构
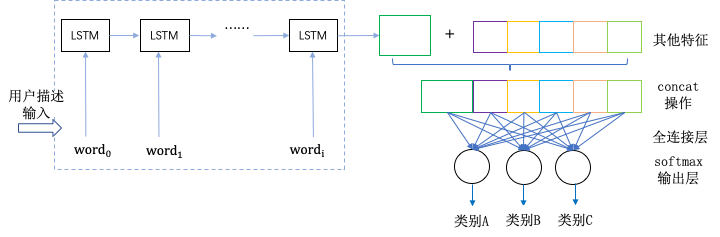
将每个用户反馈情报的词向量结果作为LSTM的输入,接着将LSTM的最后一个单元的结果作为文本特征,与其他用户选择项问题一起merge后作为模型输入,然后经过全连接层后使用softmax作为输出层进行分类,得到的0~1之间的实数即为分类的依据。多分类的网络架构如下图所示:
4.实战经验总结
理清业务逻辑、确定解题步骤、确认样本标注排期并跑通了初版的模型后,我们觉得终于可以松一口气,问题应该已经解决过半了,剩下的就是做做模型调参和优化、坐等样本积累,训练完模型就可以轻松上线了。
但实际情况却是面临着比预想更多的问题和困难,训练数据量不够、单个模型效果不好、超参设置不理想等问题接踵而至,漫长而艰难的优化和迭代过程才刚刚开始。
4.1 Fine-tuning
选定了模型之后,情报识别首先面临的问题是样本量严重不足,我们采用Fine-tuning的办法将网络上已经训练过的模型略加修改后再进行训练,用以提升模型的效果,随着人工标注样本逐渐增加,在不同大小的数据集上都可以取得大约3个百分点的提升。
4.2 调参
模型的调参是个修炼内功炼制金丹的过程,实际上取得的效果却不一定好。我们一共进行了近30组的调参实验,得出了以下饱含血泪的宝贵经验:
1)初始化,一定要做的,我们选择 SVD初始化。
2) dropout也是一定要用的,有效防止过拟合,还有Ensemble的作用。 对于LSTM,dropout的位置要放到LSTM之前,尤其是bidirectional LSTM是一定要这么做的,否则直接过拟合。
3) 关于优化算法的选择,我们尝试了Adam、RMSprop、SGD、AdaDelta等,实际上RMSprop和Adam效果相差不多,但基于Adam可以认为是RMSprop 和 Momentum 的结合,最终选择了Adam。
4) batch size一般从128左右开始调整,但并不是越大越好。对于不同的数据集一定也要试试batch size为64的情况,没准儿会有惊喜。
5) 最后一条,一定要记住的一条,尽量对数据做shuffle。
4.3 Ensemble
针对单个模型精度不够的问题,我们采用Ensemble方式解决,进行了多组试验后,最终选定了不同参数设定时训练得到的最好模型中的5个通过投票的方式做Ensemble,整体准确率比单个最优模型提高1.5个百分点。
另外为了优化模型效果,后续还尝试了模型方面的调整比如双向LSTM和不同的Padding方式,经过对比发现在情报识别中差异不大,经分析是每个用户描述问题的方式不同且分布差异不明显所致。
4.4 置信度区分
当情报识别多分类模型本身的结构优化和调参都达到一定瓶颈后,发现模型最终的效果离自动化有一定的差距,原因是特征不全且某些特征工程化提取的准确率有限、类别不均衡、单个类别的样本数量不多等。
为了更好的实现算法落地,我们尝试进行类别内的置信度区分,主要使用了置信度模型和按类别设定阈值两种办法,最终选择了简单高效的按类别设定阈值的方法。
置信度模型是利用分类模型的标签输出结果作为输入,每个标签的样本集重新分为训练集和验证集做二分类,训练后得到置信度模型,应用高置信的结果。
在置信度模型实验中,尝试了Binary和Weighted Crossentropy、Ensemble的方式进行置信度模型实验,Weighted Crossentropy的公式为:
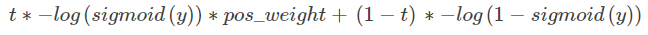
为了避免溢出,将公式改为:
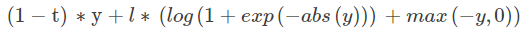
其中,表示:
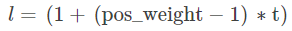
实验的结果是Binary方式没有明显效果提升,Ensemble在95%置信度上取得了较高的召回率,但是没有达到98%置信度的模型。
借鉴了情报分类算法模型落地时按照各个类别设定不同softmax阈值的方式做高置信判断即按类别设定阈值的方式,在情报识别中也使用类似的方法,取得的效果超过了之前做的高置信模型效果,所以最终选择了此种方式,这部分可以很大地提高作业员的作业效率。同时为了减少作业员的操作复杂性,我们还提供了低置信部分的top N推荐,最大程度节省作业时间。
5.算法效果及应用成果
5.1 情报分类
算法效果:根据实际的应用需求,情报分类算法的最终效果产品类准确率96%以上、数据类召回率可达99%。
应用成果:与其他策略共同作用,整体自动化率大幅提升。在通过规则优化后实际应用中取得的效果,作业人员大幅度减少,单位作业成本降低4/5,解决了用户反馈后端处理的瓶颈。
5.2 情报识别
算法效果:根据使用时高置信部分走自动化,低置信走人工进行标注的策略,情报识别算法的最终效果是有效描述准确率96%以上。
应用成果:完成情报标签分类模型接入平台后通过对高低置信标签的不同处理,最终提升作业人员效率30%以上。
6.总结与展望
通过此项目我们形成了一套有效解决复杂业务问题的方法论,同时积累了关于NLP算法与业务紧密结合解题的实战经验。目前这些方法与经验已在其他项目中很好的付诸实施,并且在持续的积累和完善中。在不断提升用户满意度的前提下尽可能的高效自动化的处理问题,是我们坚持不懈的愿景和目标。
