导读:高德地图拥有几千万的POI兴趣点,例如大厦、底商、学校等数据,而且每天不断有新的POI出现。为了维持POI数据的鲜度,高德会通过大量的数据采集来覆盖和更新。现实中POI名称复杂,多变,同时,名称制作工艺要求严格,通过人工来制作POI名称,需要花费大量的人力成本。
因此,POI名称的自动生成就显得格外重要,而机器对商户挂牌的语义理解又是其中关键的一环。本文主要介绍相关技术方案在高德的实践和业务效果。
一、背景
现实世界中,商户的挂牌各式各样,千奇百怪,如何让机器正确的理解牌匾语义是一个难点。商户挂牌的文本种类有很多,如下图所示,我们可以看到一个商户牌匾的构成。
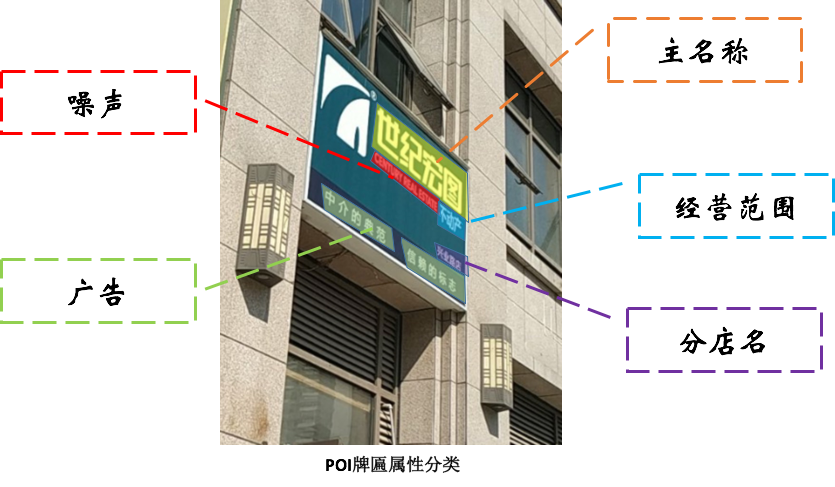
结合POI的名称制作工艺,我们目前将POI的牌匾的文本行分为4大类:主名称、经营性质(包括经营范围,具体的进行项目)、分店名、噪声(包括非POI文字,地址,联系方式),前面3个类别会参与到POI名称制作中。如上图所示的牌匾,它输出的规范名称应该是“世纪宏图不动产 (兴业路店)”。其中“世纪宏图”是主名称,“不动产”是经营范围,而“兴业路店”是分店名。
从牌匾中找出制作名称所需要的文字,不仅仅需要文本行自身的一些特征,还需要通过结合牌匾上下文,以及图像的信息进行分析。单纯的文本行识别会遇到下面的问题,如下图,在两个牌匾中都提到了“中国电信”,但是它们的意义是不一样的,这时必须结合上下文的理解。

二、技术方案
单纯从文本的语义理解的角度出发,那么这个应该是一个文本分类问题。但是直接的分类效果不佳。现实中在理解牌匾文本行语义的时候,需要结合图形,位置,内容,以及上下文关系综合来判断。为此,我们将商户挂牌理解的这个问题分解成两个子问题来解决,1.如何结合图像、文本、以及空间位置;2.如何结合上下文关系。因此,我们提出了Two-Stages级联模型。
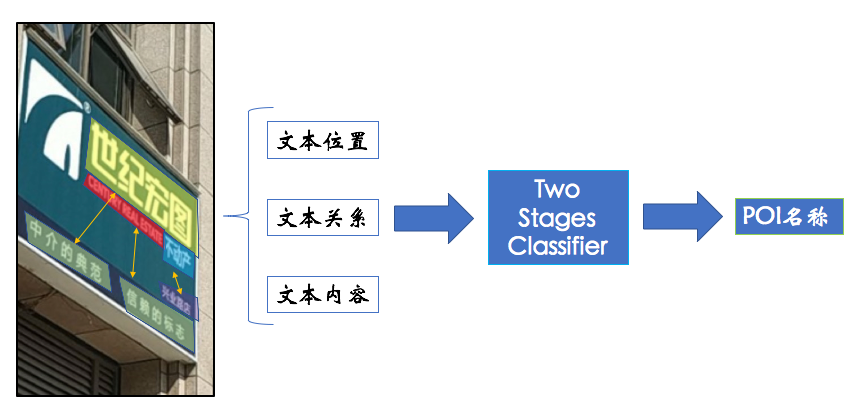
2.1 Two-Stages 级联模型
Two-stages级联模型分为两个主要的阶段:第一阶段提取单文本信息特征,包括文本位置和文本内容等,第二阶段提取牌匾中文本行上下文关系特征,消除只用单个文本识别容易造成的歧义,准确识别出该文本属性。
2.1.1 Stage One 单文本行特征提取
单文本行特征可以分为词性结构(token level)特征和句子语义(sentence level)特征。除此之外,位置信息(PV)也是比较重要的信息,需要进行特征提取和编码。将以上特征进行融合,得到了单文本行特征。
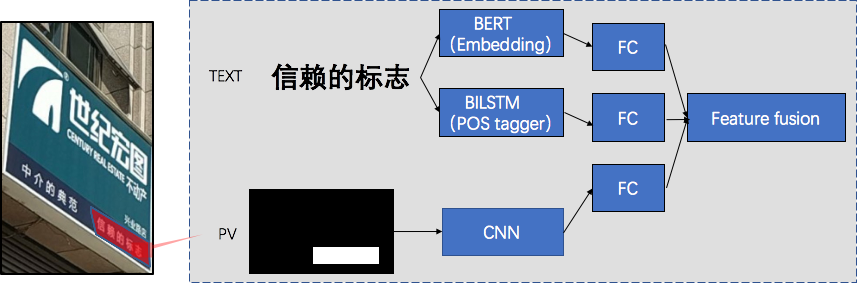
token level层的特征提取方面,结合名称的构成以及名称工艺,我们定义了三种词性: 核心词(C)、通用词(U)、结尾词(T)。在这里我们使用LSTM网络来学习名称的词性序列。

sentence leve层的特征提取方面,由于我们的标注量相对比较少,采用了具有大量先验知识的BERT模型。同时,为了更好的符合当前业务场景的需求,我们结合业务中POI的数据集合,在原来Google官方提供的预训练模型基础上继续pre-training,得到新的模型BERT-POI。
预训练的POI文本语料没有太多的上下文环境,在构造样本时,我们将两个POI名称串起来或是同一个POI随机切分,中间都用SEP隔开,进行多任务学习:缺字补全和预测两个文本行是否属于同一POI。经过实验发现,在POI数据上预训练模型BERT-POI 比Google发布模型BERT-Google,缺字补全和同一POI判定两项任务上名,正确率高20%左右。
此外,将预训练的模型用于下游属性识别任务上,BERT-POI与BERT-Google相比,提升主名称,分店名,营业范围的召回3%~6%。
下图展示了我们预训练的过程图:

随后,我们对预训练好的BERT-POI在进行了finetune,提取出sentence leve层的特征。
2.1.2 Stage-Two 文本相互关系提取
Stage One提取到了单文本行的特征,那如何去实现上下文的关联,我们加入了Stage Two的模块,模型结构如下:
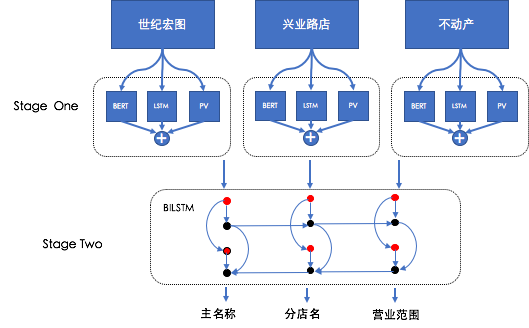
Stage Two最主要是用BILSTM(Bidirectional LSTM)处理stage one输出特征,能够将当前文本特征和牌匾内其他文本特征进行学习,消除歧义。
三、业务效果
牌匾通过语义理解后,会根据具体的输出类型来制定名称生成的策略。例如:对于单主+噪声牌匾,我们直接将主名称作为POI名称,而对于单主+分店名+经营性质+噪声的牌匾,我们会分析主名称的结构,看是否需要拼接经营性质。
下图展示了当前我们牌匾语义理解和名称的部分拼接策略:

图3.1单主+噪声场景
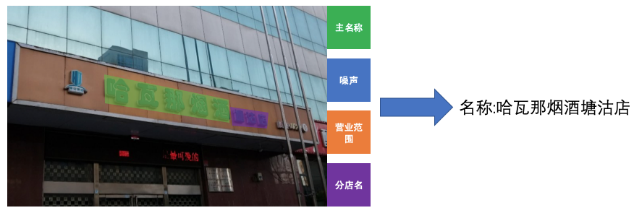
图3.2 单主+分店名场景

图3.3单主+经营性质场景(主名称中有经营性质)

图3.4 单主+经营性质场景(主名称中无经营性质)
四、小结
目前商户牌匾语义理解模块的准确率在95%以上,在POI的名称自动生成中起到的重要的作用。商户牌匾的语义理解模块只是POI名称自动化的一部分内容,在POI名称自动化中还会涉及到噪声牌匾过滤、牌匾是否依附建筑物、敏感类别、文本的缺失、名称生成、名称纠错等模块。我们会在图文多模态这块更深入的探索,更多地应用于我们现实场景中,生产更多、更高质量的数据。
