staff_table
1,Alex Li,22,13651054608,IT,2013-04-01 2,Jack Wang,30,13304320533,HR,2015-05-03 3,Rain Liu,25,1383235322,Saies,2016-04-22 4,Mmck Cao,40,1356145343,HR,2009-03-01
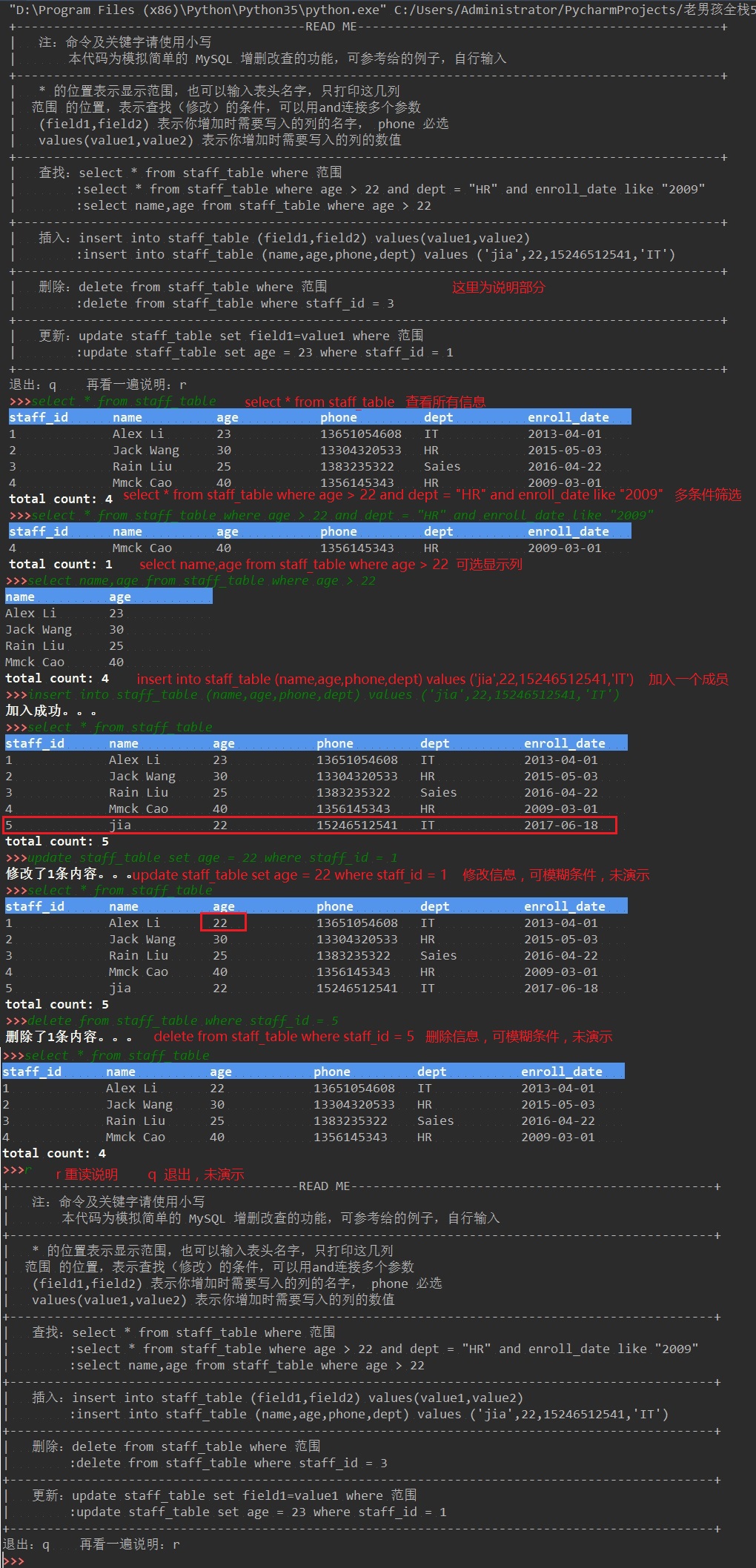
+---------------------------------------READ ME-------------------------------------------------+ | 注:命令及关键字请使用小写 | 本代码为模拟简单的 MySQL 增删改查的功能,可参考给的例子,自行输入 +-----------------------------------------------------------------------------------------------+ | * 的位置表示显示范围,也可以输入表头名字,只打印这几列 | 范围 的位置,表示查找(修改)的条件,可以用and连接多个参数 | (field1,field2) 表示你增加时需要写入的列的名字, phone 必选 | values(value1,value2) 表示你增加时需要写入的列的数值 +-----------------------------------------------------------------------------------------------+ | 查找:select * from staff_table where 范围 | :select * from staff_table where age > 22 and dept = "HR" and enroll_date like "2009" | :select name,age from staff_table where age > 22 +-----------------------------------------------------------------------------------------------+ | 插入:insert into staff_table (field1,field2) values(value1,value2) | :insert into staff_table (name,age,phone,dept) values ('jia',22,15246512541,'IT') +-----------------------------------------------------------------------------------------------+ | 删除:delete from staff_table where 范围 | :delete from staff_table where staff_id = 3 +-----------------------------------------------------------------------------------------------+ | 更新:update staff_table set field1=value1 where 范围 | :update staff_table set age = 23 where staff_id = 1 +-----------------------------------------------------------------------------------------------+ 退出:q 再看一遍说明:r
low_B的代码


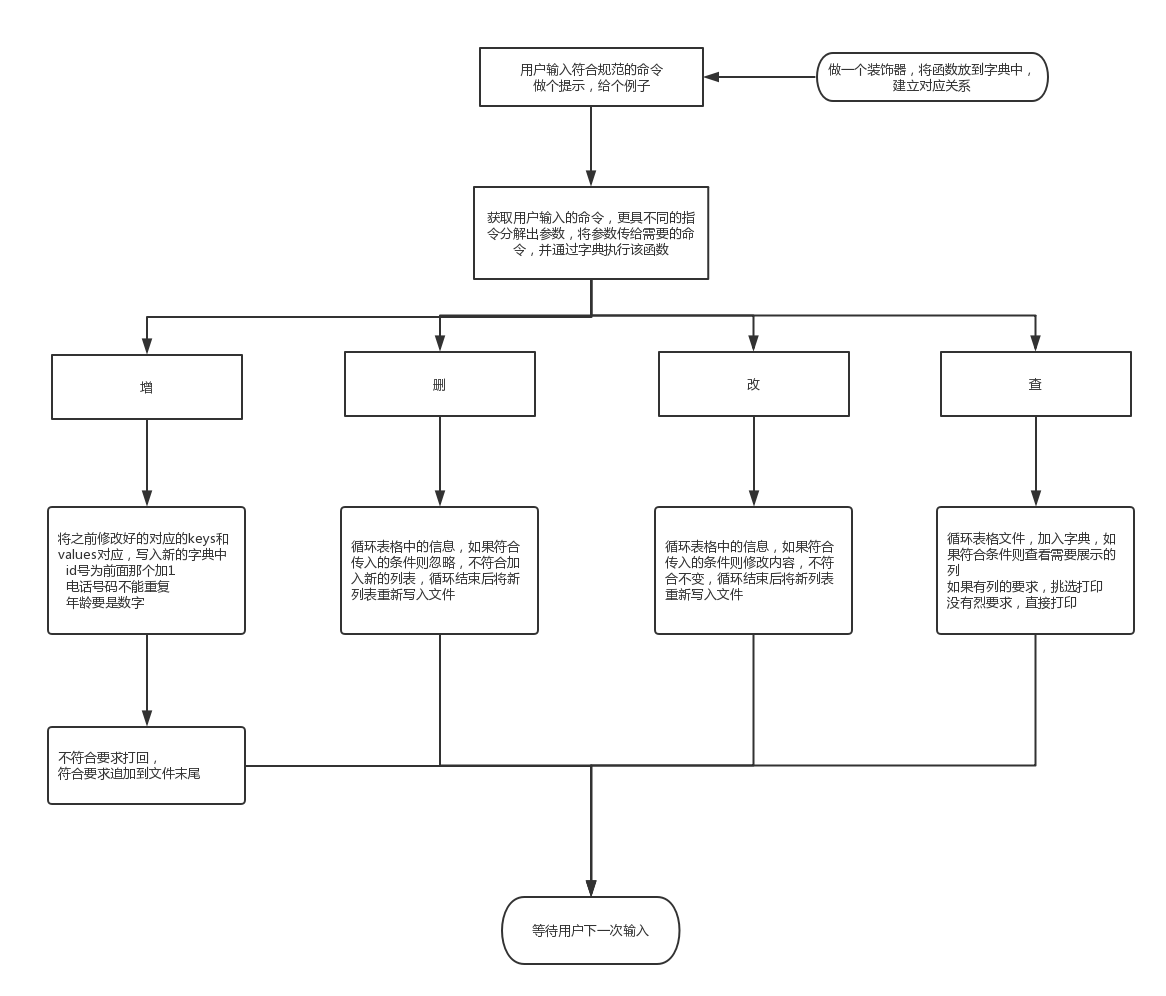
1 #! /usr/bin/env python 2 # -*- coding: utf-8 -*- 3 # __author__ = "Always" 4 # Date: 2017/6/16 5 import time 6 7 file_path = r'staff_table' 8 readme_path = r'readme.txt' 9 all_tittle = ['staff_id', 'name', 'age','phone', 'dept', 'enroll_date'] 10 func_dic = {} 11 12 def add_func_dic(keys): 13 def deco(func): 14 func_dic[keys] = func 15 return deco 16 17 def resolve_cmd(cmd): 18 """ 19 分解命令 20 这个函数,主要是用来处理接收的 select 命令,将各个参数提取出来,放到一个字典中 21 :param cmd: 这个参数是用户输入的,命令,格式为字符串形式 22 :return: 23 """ 24 cmd_dict = {'show_tittle':None, 'file_name':None, 'select_condetion':None, 'cmd':None} 25 cmd_deal = cmd.split('from')[0].split() 26 cmd_dict['cmd'] = cmd_deal.pop(0).strip() 27 cmd_deal = ''.join(cmd_deal).split(',') 28 cmd_dict['show_tittle'] = all_tittle if cmd_deal[0].strip() == "*" else cmd_deal 29 filename_select = cmd.split('from')[1].strip().split('where') 30 cmd_dict['file_name'] = filename_select[0].strip() 31 if len(filename_select) > 1: 32 cmd_dict['select_condetion'] = filename_select[1].strip() 33 return cmd_dict 34 35 def deal_select_condetion(select_condetion): 36 """ 37 主要用来处理后面的条件有 like 的情况,为筛选的条件重新排序 38 :param select_condetion: 39 :return: 40 """ 41 select_condetion = select_condetion.split('and') 42 for i in range(len(select_condetion)): 43 if 'like' in select_condetion[i]: 44 select_condetion[i] = select_condetion[i].split() 45 select_condetion[i].reverse() 46 select_condetion[i] = ' '.join(select_condetion[i]) 47 return ' and '.join(select_condetion).replace('like', 'in') 48 49 50 def return_select_result(total_count, all_tittle, show_tittle, d): 51 """ 52 这个函数主要用来处理打印满足条件的行数和列数 53 :param total_count: 用来计算一共打印了多少行 54 :param all_tittle: 所有的表头,用来固定打印顺序 55 :param show_tittle: 代表需要打印的列 56 :return: 用来计算一共打印了多少行 57 """ 58 for tittle in all_tittle: 59 if tittle in show_tittle: 60 print('%-14s' % d[tittle], end='') 61 print() 62 total_count += 1 63 return total_count 64 65 @add_func_dic('select') 66 def what_a_funck(cmd): 67 cmd_dict = resolve_cmd(cmd) 68 select(cmd_dict['file_name'], cmd_dict['select_condetion'], cmd_dict['show_tittle']) 69 70 def select(file_name, select_condetion, show_tittle): 71 """ 72 这个功能用来查找,并打印符合要求的字段 73 :param file_name 74 :param select_condetion 75 :param show_tittle 76 :return: 77 """ 78 file_info_list = get_file_info_to_list(file_name) 79 80 for tittle in all_tittle: # 打印表头 81 if tittle in show_tittle: 82 print('�33[44;1m%-14s' % tittle, end='') 83 print('�33[0m') 84 total_count = 0 85 86 if select_condetion: # 如果有筛选条件的话,按条件打印,没有的话,全部打印 87 select_condetion = select_condetion.replace('=', '==') # 如果判断条件有一个 ’=‘ 就把他变成两个,方便后面 eval 计算 88 if 'like' in select_condetion: # 如果判断条件有 like 就把 enroll_date like "2013" 改成 “2013” in enroll_date ,方便后面 eval 计算 89 select_condetion = deal_select_condetion(select_condetion) 90 91 92 for d in file_info_list: # 遍历 用户信息 列表 93 globals().update(d) # 将字典中所有内容变为变量,用来处理条件 94 show_table_tittle = False 95 if eval(select_condetion): # 如果满足输入的条件,那么打印信息 96 97 total_count = return_select_result(total_count,all_tittle,show_tittle, d) 98 else: # 如果用户没有输入筛选条件,执行这里 99 for d in file_info_list: 100 total_count = return_select_result(total_count, all_tittle, show_tittle, d) 101 print('�33[1mtotal count: %s�33[0m'%total_count) 102 103 def get_file_info_to_list(file_path): # 将文件内容取出来,放入 [{},{}] 中 104 with open (file_path,encoding='utf-8') as f: 105 return [{'staff_id':int(line.strip().split(',')[0]), 'name':line.strip().split(',')[1], 'age':int(line.strip().split(',')[2]), 'phone':line.strip().split(',')[3], 'dept':line.strip().split(',')[4], 'enroll_date':line.strip().split(',')[5]} for line in f] 106 107 108 def insert_split(cmd): # 插入功能的前戏 109 """ 110 插入功能的命令分解。。。 111 :param cmd: 用户输入的命令 112 :return: 包含分解的命令的字典 113 """ 114 cmd_dict = {} 115 cmd_split = cmd.split() 116 if cmd_split[1] != 'into': 117 return 118 cmd_dict['file_name'] = cmd_split[2] 119 cmd_split = ''.join(cmd_split[3:]).split('values') 120 cmd_dict['keys'] = cmd_split[0].strip('(').strip(')').split(',') 121 cmd_dict['values'] = cmd_split[1].strip('(').strip(')').split(',') 122 return cmd_dict 123 124 @add_func_dic('insert') 125 def insert(cmd, all_tittle = all_tittle, file_path = file_path): # 插入功能的开始 126 """ 127 插入功能,新增一个用户 128 :param cmd: 传入命令行的输入,进行分解调用 129 :param all_tittle: 默认为全局变量,用来判断需要写入那些内容,以及位置排序 130 :param file_path: 默认为全局变量,用来标记需要修改的文件名 131 :return: 132 """ 133 if not insert_split(cmd): 134 print('输入错误。。。') 135 return 136 cmd_dict = insert_split(cmd) 137 globals().update(cmd_dict) 138 file_info_list = get_file_info_to_list(file_path) 139 new_people_info = {'staff_id':file_info_list[-1]['staff_id'] + 1} 140 if 'phone' not in keys: 141 print('哥,我也不想的,老师指定 phone 为唯一键,不输入不行啊。。。。') 142 return 143 144 for i in file_info_list: # 如果号码重复,重新输入 145 if i['phone'] == values[keys.index('phone')]: 146 print('那啥,号码已注册,换一个吧。。亲。。。。') 147 return 148 if 'age' in keys and not values[keys.index('age')].isdigit(): # 判断年龄是不是数字 149 print('年龄需要为数字。。。') 150 return 151 152 for i in all_tittle[1:]: # 准备加入 新人物 的信息 153 if i in keys: 154 new_people_info[i] = values[keys.index(i)].strip("'").strip('"') 155 else: 156 new_people_info[i] = None 157 new_people_info = [new_people_info] 158 add_new_people(all_tittle, new_people_info, file_path, open_with='a') 159 print('�33[1m加入成功。。。�33[0m') 160 161 162 def add_new_people(all_tittle,new_people_info, file_path, open_with = 'r'): 163 """ 164 主要用来写入或增加 staff_table 的内容 165 :param all_tittle: 存放表头信息 166 :param new_people_info: 需要加入,或重新写入的任务信息 167 :param file_path: 文件路径 168 :param open_with: 打开方式 169 :return: 1 170 """ 171 with open(file_path, open_with, encoding='utf-8') as f: 172 new_people_info_str = '' 173 if new_people_info[0]['enroll_date'] == None: 174 new_people_info[0]['enroll_date'] = time.strftime("%Y-%m-%d") 175 176 for d in new_people_info: 177 for i in all_tittle: 178 new_people_info_str += '%s,'%d[i] 179 new_people_info_str = new_people_info_str.strip(',') + ' ' 180 f.write(new_people_info_str) 181 return 1 182 183 184 @add_func_dic('delete') 185 def delete(cmd1): 186 """ 187 处理删除命令,通过匹配符合条件的方法,不符合的加入新的列表中,等待重新写入 188 :param cmd1: 用户输入的命令 189 :return: 1 190 """ 191 cmd_dic = resolve_cmd(cmd1) 192 cmd, file_name, select_condetion = cmd_dic['cmd'], cmd_dic['file_name'], cmd_dic['select_condetion'] 193 194 if select_condetion: 195 select_condetion = select_condetion.replace('=', '==') 196 if 'like' in select_condetion: # 如果判断条件有 like 就把 enroll_date like "2013" 改成 “2013” in enroll_date ,方便后面 eval 计算 197 select_condetion = deal_select_condetion(select_condetion) 198 else: 199 print("请输入条件。。。。") 200 return 201 202 file_info_list = get_file_info_to_list(file_name) # 获取文件相关参数 203 new_file_list = [] # 筛选出新信息后重新写入 204 total_count = 0 205 for d in file_info_list: 206 globals().update(d) 207 if not eval(select_condetion): 208 new_file_list.append(d) 209 else: 210 total_count += 1 211 add_new_people(all_tittle,new_file_list,file_name,open_with='w') 212 print('�33[1m删除了%s条内容。。。�33[0m' % total_count) 213 return 1 214 215 216 def update_split(cmd): 217 """ 218 处理用户更新信息时候的命令,将它分割开 219 :param cmd: 用户输入的信息 220 :return: 分割好的内容 file_name, change_thing, select_condetion 221 """ 222 cmd_dic={} 223 cmd_dic['file_name'] = cmd.split('set')[0].split('update')[1].strip() 224 cmd_dic['change_thing'] = cmd.split('where')[0].split('set')[1].strip().split('=') 225 if 'staff_id' in cmd_dic['change_thing'][1]: 226 print('哥,为了方便程序运行,我禁止了修改 ID 。。。。') 227 return 228 if 'where' not in cmd: 229 print('没有输入范围(where)。。。') 230 return 231 cmd_dic['select_condetion'] = cmd.split('where')[1].strip() 232 if 'age' in cmd_dic['change_thing']: 233 if not cmd_dic['change_thing'][1].isdigit(): 234 print('年龄要是个数字。。。。') 235 return 236 return cmd_dic['file_name'], cmd_dic['change_thing'], cmd_dic['select_condetion'] 237 238 @add_func_dic('update') 239 def update(cmd): 240 """ 241 这个程序用来修改数据库信息 242 :param cmd: 用户输入的命令 243 :return: 1 244 """ 245 cmd_dic = update_split(cmd) 246 if not cmd_dic: 247 return 248 file_name, change_thing, select_condetion = update_split(cmd) 249 select_condetion = select_condetion.replace('=','==') 250 if 'like' in select_condetion: # 如果判断条件有 like 就把 enroll_date like "2013" 改成 “2013” in enroll_date ,方便后面 eval 计算 251 select_condetion = deal_select_condetion(select_condetion) 252 file_info_list = get_file_info_to_list(file_name) 253 total_count = 0 254 for i,d in enumerate(file_info_list): 255 globals().update(d) 256 if eval(select_condetion): 257 file_info_list[i][change_thing[0].strip()] = change_thing[1].strip() 258 total_count += 1 259 260 add_new_people(all_tittle,file_info_list, file_name, open_with = 'w') 261 print('�33[1m修改了%s条内容。。。�33[0m' % total_count) 262 263 264 def main(): 265 while True: 266 with open(readme_path,encoding='utf-8') as f: 267 for i in f: 268 print(i.strip()) 269 while True: 270 cmd = input("�33[31;1m>>>�33[0m").strip() 271 if cmd.upper() == 'Q': 272 exit('谢谢使用') 273 elif cmd.upper() == 'R': 274 break 275 try: 276 func_dic[cmd.strip().split()[0]](cmd) 277 except Exception: 278 print('输入错误。。。') 279 time.sleep(0.3) 280 281 if __name__ == "__main__": 282 main()