(定义,举例,实例,问题,扩充,采样,人造,改变)
一、不平衡数据集
1)定义
不平衡数据集指的是数据集各个类别的样本数目相差巨大。以二分类问题为例,假设正类的样本数量远大于负类的样本数量,这种情况下的数据称为不平衡数据
2)举例
在二分类问题中,训练集中class 1的样本数比上class 2的样本数的比值为60:1。使用逻辑回归进行分类,最后结果是其忽略了class 2,将所有的训练样本都分类为class 1
在三分类问题中,三个类别分别为A,B,C,训练集中A类的样本占70%,B类的样本占25%,C类的样本占5%。最后我的分类器对类A的样本过拟合了,而对其它两个类别的样本欠拟合
3)实例
训练数据不均衡是常见并且合理的情况,比如:
a)在欺诈交易识别中,绝大部分交易是正常的,只有极少部分的交易属于欺诈交易
b)在客户流失问题中,绝大部分的客户是会继续享受其服务的(非流失对象),只有极少数部分的客户不会再继续享受其服务(流失对象)
4)导致的问题
如果训练集的90%的样本是属于同一个类的,而我们的分类器将所有的样本都分类为该类,在这种情况下,该分类器是无效的,尽管最后的分类准确度为90%。所以在数据不均衡时,准确度(Accuracy)这个评价指标参考意义就不大了
实际上,如果不均衡比例超过4:1,分类器就会偏向于大的类别
二、不平衡数据集常用的处理方法
(1)扩充数据集
首先想到能否获得更多数据,尤其是小类(该类样本数据极少)的数据
(2)对数据集进行重采样
a)过采样(over-sampling):对小类的数据样本进行过采样来增加小类的数据样本个数
from imblearn.over_sampling import RandomOverSampler ros=RandomOverSampler(random_state=0) #采用随机过采样(上采样) x_resample,y_resample=ros.fit_sample(trainset,labels)
b)欠采样(under-sampling):对大类的数据样本进行欠采样来减少大类的数据样本个数
from imblearn.under_sampling import RandomUnderSampler #通过设置RandomUnderSampler中的replacement=True参数, 可以实现自助法(boostrap)抽样 #通过设置RandomUnderSampler中的ratio参数,可以设置数据采样比例 rus=RandomUnderSampler(ratio=0.4,random_state=0,replacement=True) #采用随机欠采样(下采样) x_resample,y_resample=rus.fit_sample(trainset,labels)
(3)人造数据
a)属性值随机采样
在该类下所有样本的每个属性特征的取值空间中随机选取一个组成新的样本,即属性值随机采样。此方法多用于小类中的样本,但是该方法可能会产生现实中不存在的样本
b)SMOTE(Synthetic Minority Over-sampling Technique)
SMOTE是一种过采样算法,它构造新的小类样本而不是产生小类中已有的样本的副本
原理简单来说:
原始数据分布(需要增加红色样本来平衡数据集)

Smote算法的思想其实很简单,先随机选定n个少类的样本,如下图:
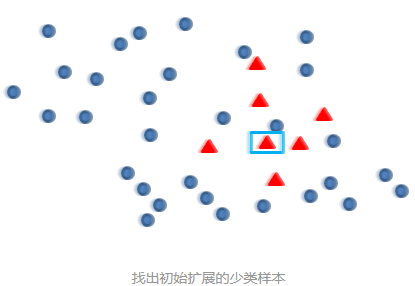
再找出最靠近它的m个少类样本,如下图:

再任选最临近的m个少类样本中的任意一点:
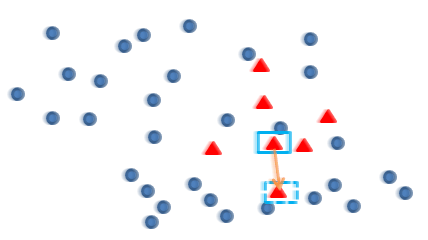
在这两点连线上任选一点(对二维数据来说),这点就是新增的数据样本:

对于高维数据来说,从m个最邻近样本点中随机选出一个点后(即上面图中的虚框中的点),求出两个方框中点的距离(如欧式距离),再从([0, 1])中随机选择一个数,乘以距离差得到新的数据点:

(4)改变分类算法
a)使用代价函数时,可以增加小类样本的权值,降低大类样本的权值(这种方法其实是产生了新的数据分布,即产生了新的数据集),从而使得分类器将重点集中在小类样本身上。刚开始,可以设置每个类别的权值与样本个数比例的倒数
b)可以把小类样本作为异常点(outliers),把问题转化为异常点检测问题(anomaly detection)。此时分类器需要学习到大类的决策分界面,即分类器是一个单个类分类器(One Class Classifier)
三、参考
本文参考:https://blog.csdn.net/asialee_bird/article/details/83714612
感谢!