MetaPoison: Practical General-purpose Clean-label Data Poisoning “MetaPoison:通用的干净标签投毒”
written by:W. Ronny Huang * 1 Jonas Geiping * 1 2 Liam Fowl 1 Gavin Taylor 3 Tom Goldstein 1
abstract
目前存在的投毒攻击主要依赖于启发式的手工制作。本文将制作中毒点看做一个双层优化问题:(1)内层使用被投毒的数据集训练网络 (2)外层通过更新投毒点使模型达到攻击者预期的行为。提出了MetaPoison(一种干净标签攻击),具有如下优点:(1)健壮性:中毒点可转移至不同的未知超参数和结构的受害模型(2)通用性:不仅适用于微调学习的情况,对于端到端的学习也表现出较高的攻击成功率(3)可以实现任意目标攻击:使用来自同一类别的poisons,可以让目标被误分类到攻击者所选择的任意一个类别中(4)在现实世界中有效:本文在Google Cloud AutoML Vision中成功实现投毒攻击。
introduction
干净标签攻击:无需同时修改输入和标签,仅对输入进行改动(添加一些扰动),仍可被正确标注。被扰动的图像会使目标分类器对某一特定的目标样本进行错误分类,但对其他的输入样本保持其行为的正确性,使得这种攻击难以被检测。
comparison
FCA(特征碰撞攻击):FC是一种适用范围有限的启发式方法,攻击者需要已知受害模型所使用的的特征提取器,且其参数无法被添加的poison修改。所以FCA只能在微调和转移学习的管道内进行,无法在端到端的学习中进行。同时,FCA不是通用的,仅导致单个目标实例被错误地按照poison的标签分类。
process
(1)本文提出的MetaPoison,在对预先训练好的受害模型进行微调的既定环境(transfer learning & fine-tuning)中,比FC方法有很大的优势。
(2)当受害模型使用随机初始化从头开始训练(end-to-end learning)时,可以实施成功的攻击。
(3)将MetaPoison攻击转移到“黑盒”设置中,即受害模型使用攻击者不知道的训练超参数和网络架构。
(4)通过在谷歌云自动视觉平台上成功地建立中毒模型来验证其实用性,表明这种攻击在现实世界中可行。
(5)MetaPoison能够实现一系列的任意目标攻击,为完全、任意地控制受害模型铺平道路。
method
xt:攻击者的目标样本
yadv:将目标样本错误预测为yadv类别
n:中毒样本数 Xp∈[0,255]n*m
m:像素数
Xc:干净的训练数据集 Xc∈[0,255]N*m ,N >> n
首先,将优化Xp*问题归结为如下的式子,Ladv代表“对抗损失”的损失函数,θ*(Xp)为在Xp∪Xc上训练的模型的网络权重:
![]()
最小化Xp涉及到θ*(Xp),而θ*(Xp)本身也是一个最小化训练问题,Ltrain为标准交叉熵损失函数,Y∈ZN+n,是Xp∪Xc对应的正确标签空间:
![]()
本文要做的就是先找到一个投毒样本集Xp,再在被训练的模型基础上,对Xp进行优化。
对于xp的定义:xp = fg(x)+δ 其中,fg是一个扰动函数ReColorAdv perturbation function(像素级颜色重新映射:C -> C , C是三维色彩空间),该函数以图像x为基准,g为参数。δ是一个可添加的扰动。为确保扰动最小化,可以对每个xi,设置||fg(xi)-xi||∞ < εc,||δ||∞ < ε(本实验中取 ε=8,εc=0.04)
然而,对上述两个式子完全展开计算是不太现实的,计算量过大,且在深度足够的图形中,可能会导致梯度的消失或爆炸。本文采取的办法是先对内层训练进行展开,允许在训练过程中“向前看”,以探究当前对毒药的干扰将如何影响到未来几步后的Ladv。例如,展开内层两个步骤再去计算对外层的影响:

其中,α和β分别代表学习率和制作率。内层降低Ltrain,外层降低Ladv。
一旦可以成功投毒,意味着Ltrain和Ladv都已降至攻击所要求的范围内,尽管我们主要对Ltrain进行训练。

当然,这种训练方式也存在着一些问题:(1)训练过程依赖于初始权值和批量的顺序,这对于攻击者来说是随机且未知的(2)同时对网络权值和中毒样本进行训练会导致过拟。
本文也提出了解决的办法:多个网络集成&网络重新初始化。在每一轮训练中使用不同的模型制作中毒样本,一旦这个模型被使用过一定次数,就对它初始化并重新训练。因此,每一轮更新可以表示为以下形式,θj对应着公式(3)中的θ0:

(3)同步问题:使用不同的模型制作的中毒样本也许并不适用于其它模型,公式(4)中需要用到所用中毒样本进行更新。且每一批次中可能有多个中毒样本,也可能根本不生成样本。这里的解决办法是一旦生成一个新的中毒样本,立即对网络进行一次完整训练。
具体算法如下:
experiment
数据集:CIFAR-10
(1)在替代模型上制作中毒样本以等待评估
(2)在受害模型上投毒并对攻击进行评估
一次成功的攻击被定义为:xt被分类为yadv(这不包括xt被误分类为其他类别)
基准图像x:为yadv中的前n个样本,用以添加扰动
Xc:数据集中其余数据
xt:从测试集中选取
外层进行60轮迭代,初始lr = 200,没20次降低10
内层展开数 K=2 SGD steps 批大小 125 lr=0.1 用于集成的网络数 24 默认使用 6层 ConvNet结构
注:受害模型也使用上述内层设置,对其进行200迭代,在第100和150次迭代时使lr递减10。
comparison
FCA & MetaPoison
FCA:白盒,在干净数据集上预训练,在中毒数据集上微调。在添加扰动之前将30%不透明度的xt作为水印投入中毒样本。随机选取30个yadv进行测试,并对中毒数据集的大小进行改变。
MetaPoison:对上述情况进行复现,εc = 0,也添加了30%不透明度的水印。100次迭代以预训练模型并固定网络参数。
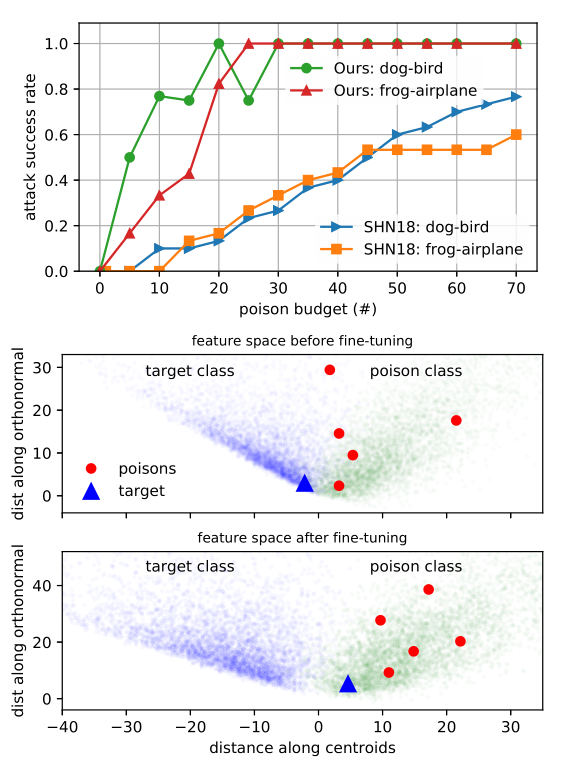
微调情况下,本文尝试对攻击机制做出解释。对于FCA来说,所有的中毒样本都被精心制作,以与网络倒数第二层中的目标共享相同的特征表示。当倒数第二层的特征被可视化时,毒物与目标发生重叠或碰撞。而MetaPoison的中毒样本不会与目标碰撞,甚至不需要存在于目标分类中,这意味着这种攻击方法使用其他机制来达到攻击目的。如图所示,元操作导致特征提取层将目标推向poison类的方向,而不依赖于基于特征碰撞的机制。这里注意到,MetaPoison的中毒机制是机器后天习得的,而不是手工制作的,所以我们可能无法简单的解释其背后机制。
接下来的部分是对从0开始训练的模型,展示攻击可行性。实验表明,由于训练的随机性和感知差异,对不同的xt进行投毒会显示不同的攻击成功率。
这部分训练了6个受害模型,每个模型进行10中不同类别的投毒。

注:超过5%的poison budget可能会导致模型的过拟,降低成功率。

在这种学习方式下,继续尝试对MetaPoison做出解释。上图查看了多个迭代中的倒数第二层特征。在epoch 0中,由于网络是从零开始训练的,所以这些类并没有很好地分开。随着训练的发展,较早的层特征提取器学会了识别倒数第二层中的类。接下来,它们并不分离xt,相反,稳步引导xt从它自己的分布到中毒点的的分布中,随着训练的进展到199次迭代,xp和xt的分布趋于一致。此外,注意到中毒点的分布似乎对于xt是非对称的,这表明其采用了与特定目标图像相似的特征,以至于网络不再有能力将二者区分开来。
Robustness and transferability
本部分用于分析MetaPoison的健壮性和可转移性。

第一个图对不同参数设置下,与基准(前文提到的lr = 0.1 批大小125 为正则化)攻击成功率进行对比。结果说明,攻击表现效果较稳定,但也许在训练集数据变化较大的时候,成功率会有明显变化。
第二个图表明在替代模型和攻击模型不同使,攻击的可转移性。攻击成功率仍是较高的,注意到26%,分析其原因:可能是VGG13没有对批大小进行标准化,对中毒样本的制作产生了影响。
本实验也在真实世界-- Google Cloud AutoML Vision中,成功进行了投毒攻击。
explore more
最后,作者对攻击方案提供了一下两种不同的思路。
正常情况下,对于一个目标样本(xt,yt),在使用(x,yp)投毒后,会变成(xt,yp),即yadv=yp。而攻击可能还有不同的方案:
1.自我隐藏式:这种方案的目标是让yt=yp≠yadv,即对本类进行投毒,使其被错误归为其他类别。对于这种攻击,定义对抗损失函数
Ladv(Xp) = −log[1 − pθ ∗ (Xp) (xt,yt)] 此时,越高的误分类率意味着越小的损失
2.多分类毒药式:当数据集有较多的类别时,假设所有的中毒样本来自一个单一类别时困难的。本文提出的解决方案是选择多个类别中的样本制作毒药以投毒同一个目标(最终定义xt被误分类为被投票最多的类别)。
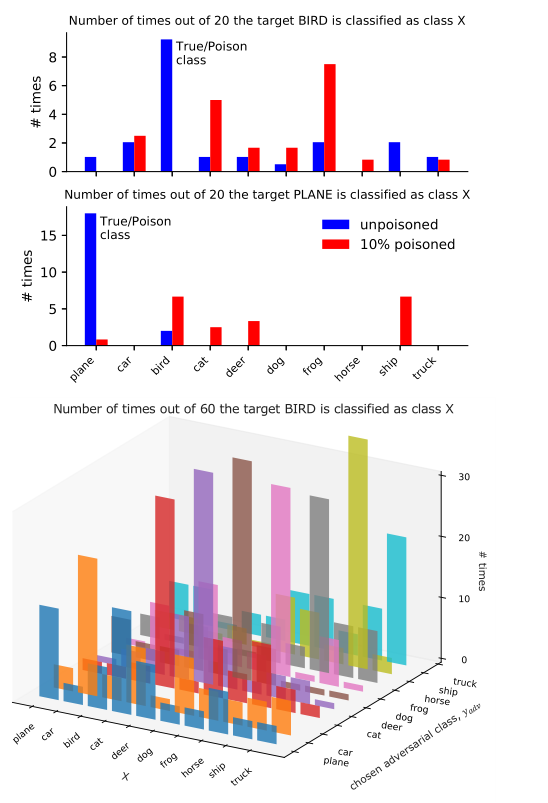
上述两个方案都是成功的。对于方案2,由于poisons无需来自特定分类,表明投毒来控制标签分配是可能的。