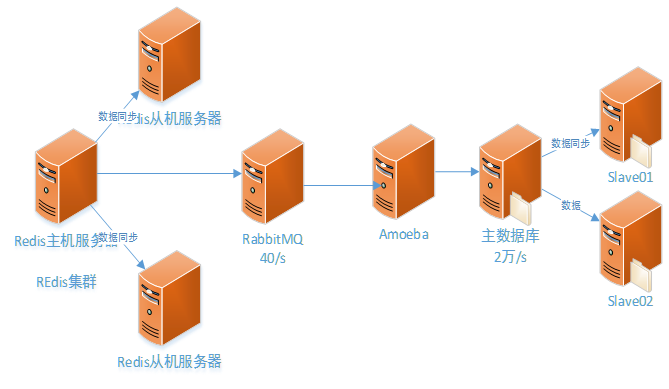
虽然后台使用了读写分离技术,能够在一定程度上抗击高并发,但是如果并发量特别巨大时,主数据库不能同时处理高并发的请求,这时数据库容易宕机.
问题:
现在的问题是如何既能保证数据库正常运行,又能实现用户数据的入库操作?
解决方案:
引入rabbitMQ技术:
说明:
当数据库的访问压力过载时,这时会将过载以后的数据先保存到rabbitMQ中.其中的数据结构是队列的形式,先进先出.这时数据库从队列中取数据执行.一直到队列中的数据全部操作完成为止.
RabbitMQ就是消息的中间件.
RabbitMQ介绍:
RabbitMQ性能分析:

1.MSMQ:是微软的产品 应用于.net框架
2.ActiveMQ:是apache的产品 做业务用图广泛
3.RabbitQM:是爱立信的产品(早期手机生产厂商)基于erlang语言(函数式编程大数据 scala语言)
4.ZeroMQ:大数据中应用广泛,缺点容易丢失数据.但是业务系统中使用率较少
5.KafkaMQ:大数据项目中使用,50万/秒 现在主流
5.RabbitMQ环境搭建:
1.配置JDK:
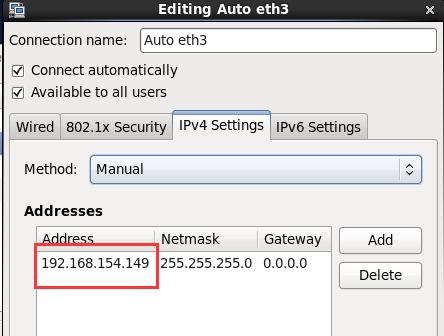
2.固定虚拟机IP地址:
3.连接虚拟机:
编辑文件跳转路径:
Vim go
Cd /usr/local/src
2.安装rabbitMQ:
1.新建文件rabbitmq
/usr/local/src/rabbitmq
2.将安装文件导入

3.安装rabbitMQ

4.开启远程用户访问:
将文件复制到指定目录下:
cp /usr/share/doc/rabbitmq-server-3.6.1/rabbitmq.config.example /etc/rabbitmq/rabbitmq.config
修改新复制的文件64行
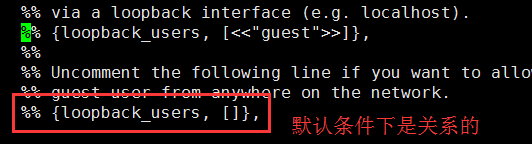
1.将%%去掉
2.将,号去掉
修改为:

5.开启rabbitMQ:
执行命令:
rabbitmq-plugins enable rabbitmq_management
表示启动成功
6.开放端口15672和5672
iptables -I INPUT -p tcp --dport 15672 -j ACCEPT
访问rabbitMQ的控制台
iptables -I INPUT -p tcp --dport 5672 -j ACCEPT
程序连接rabbitMQ的端口
或者关闭防火墙
7.启动/停止服务
service rabbitmq-server start 启动
service rabbitmq-server stop 停止
service rabbitmq-server restart 重启

1、服务器启动与关闭
启动:service rabbitmq-server start
关闭:service rabbitmq-server stop
重启:service rabbitmq-server restart
2、用户管理
新增 rabbitmqctl add_user admin admin
删除 rabbitmqctl delete_user admin
修改 rabbitmqctl change_password admin admin123
用户列表 rabbitmqctl list_users
设置角色 rabbitmqctl set_user_tags admin administrator monitoring policymaker management
设置用户权限 rabbitmqctl set_permissions -p VHostPath admin ConfP WriteP ReadP
查询所有权限 rabbitmqctl list_permissions [-p VHostPath]
指定用户权限 rabbitmqctl list_user_permissions admin
清除用户权限 rabbitmqctl clear_permissions [-p VHostPath] admin
8.远程登录:
访问:
用户名和密码都是guest

9.视图解析:
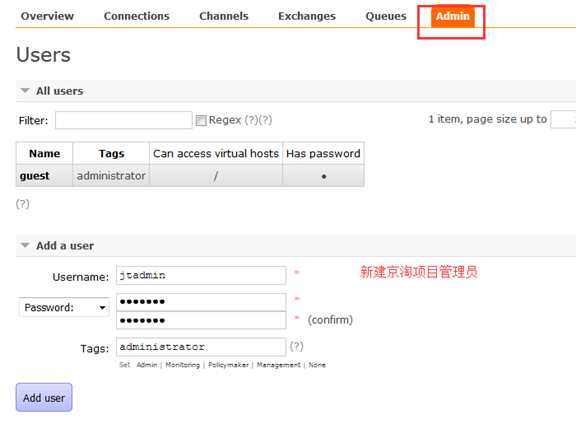
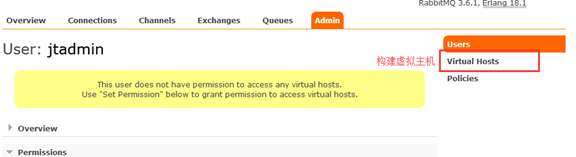
10.建立管理员:
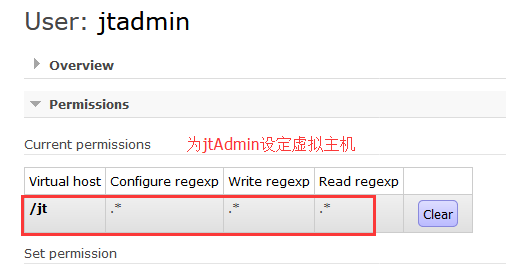
11.构建虚拟主机:

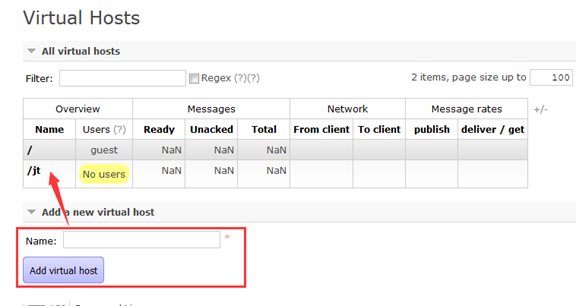
11.构建虚拟主机:

6.rabbitMQ的工作模式:
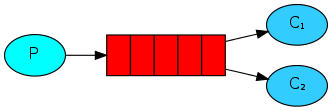
1.简单模式:

p:proverder 生产者
c:consumer 消费者
红色部分:队列 先进先出
原理说明:
生产者负责向队列中添加消息.消费者负责消费队列中的消息.
消费者通过监听器,实时监控消息队列.如果消息队列中有消息则消费,如果没有消息 则等待消息.
2.测试代码:
1.定义Connection
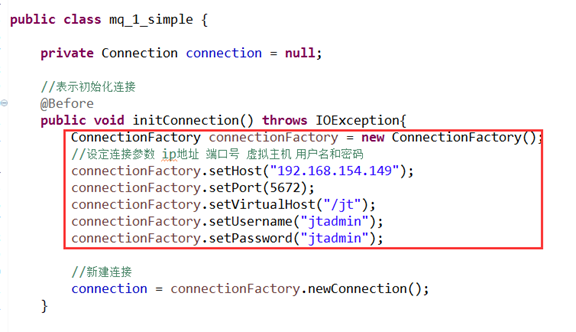
1.1.定义生产者
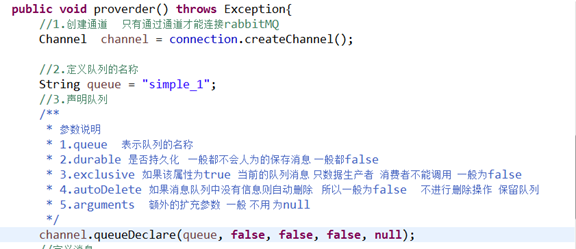

3.定义消费者:
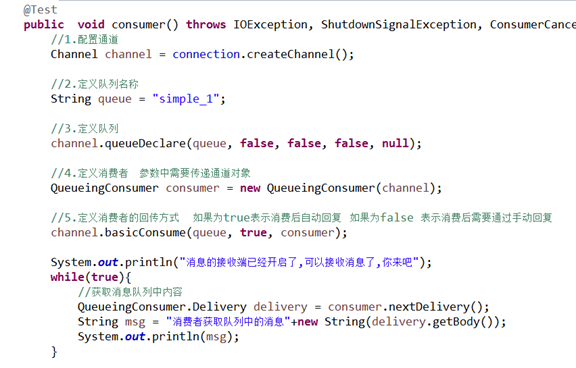
2.工作模式:
原理说明:
生产者为消息队列中生产消息,多个消费者争抢执行权利,谁抢到谁执行.
实用场景:秒杀业务 抢红包等
测试代码:

3.发布订阅模式:
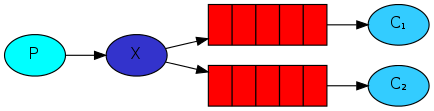
x:exchange 交换机
P:表示生产者
C1-2:表示多个消费者
原理说明:
当生产者生产消息后,先将消息发往交换机.交换机再将消息发往订阅了当前消息的队列,再次有各个队列的消费者执行.
类似于 广播
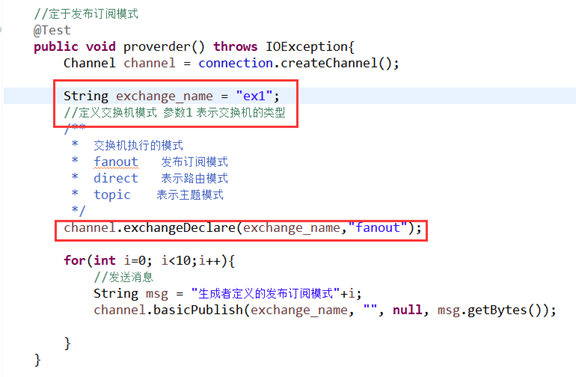
定义消费者::
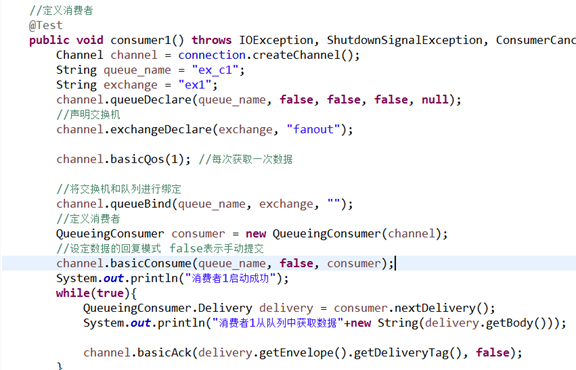
4.路由模式:

x:表示交换机 type=direct 表示路由
路由模式中,需要定义路由key
原理说明:
1.当生产者发布消息时,会定义指定的路由key 例如 key:error
2.这时交换机会根据路由key发往满足条件的队列中.如果队列中没有符合条件的路由key将不能执行该消息.
5.主题模式:
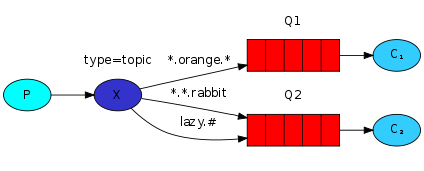
Type:topic 表示主题模式
- * (star) can substitute for exactly one word.
- # (hash) can substitute for zero or more words.
- 有坑 效果一样
7.订单实现RabbitMQ
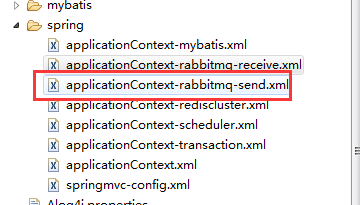
1.引入配置文件:
classpath:jdbc.propertiesclasspath:env.properties /hp月n、 口山闰廷比二曰站叩四瞿二月当“习 classpath:rabbitmq.properties IUe> /value>" v:shapes="图片_x0020_42">
2.引入生产者
1.引入配置文件
2.定义发送端
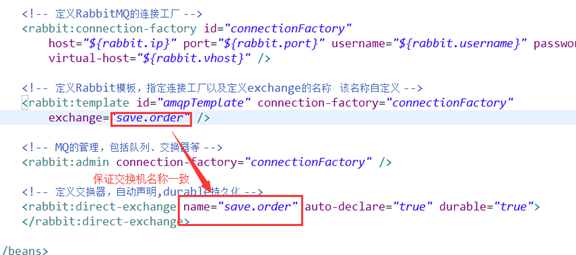
3.发送端代码
通过代码相rabbitmq中发送数据

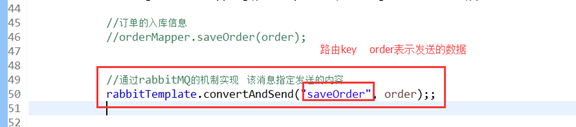
4.定义接收端:
引入配置文件

5.定义接收端:

6.测试成功