CABaRet:利用推荐系统进行移动边缘缓存
本文为SIGCOMM 2018 Workshop (Mobile Edge Communications, MECOMM)论文。
笔者翻译了该论文。由于时间仓促,且笔者英文能力有限,错误之处在所难免;欢迎读者批评指正。
本文及翻译版本仅用于学习使用。如果有任何不当,请联系笔者删除。
本文作者包含4位,Savvas Kastanakis@University of Crete and FORTH, Greece;Pavlos Sermpezis@FORTH, Greece; Vasileios Kotronis@FORTH, Greece; Xenofontas Dimitropoulos@University of Crete and FORTH, Greece.
ABSTRACT (摘要)
Joint caching and recommendation has been recently proposed for increasing the efficiency of mobile edge caching. While previous works assume collaboration between mobile network operators and content providers (who control the recommendation systems), this might be challenging in today’s economic ecosystem, with existing protocols and architectures. In this paper, we propose an approach that enables cache-aware recommendations without requiring a network and content provider collaboration. We leverage information provided publicly by the recommendation system, and build a system that provides cache-friendly and high-quality recommendations. We apply our approach to the YouTube service, and conduct measurements on YouTube video recommendations and experiments with video requests, to evaluate the potential gains in the cache hit ratio. Finally, we analytically study the problem of caching optimization under our approach. Our results show that signifcant caching gains can be achieved in practice; 8 to 10 times increase in the cache hit ratio from cache-aware recommendations, and an extra 2 times increase from caching optimization.
最近,联合缓存和推荐被提出,以提升移动边缘缓存的效率。尽管前期工作假设移动网络操作者和内容提供商(管理推荐系统)之间相互协作,在今天的经济生态系统中,使用现有的协议和架构,这种相互协作是具有挑战的。本文中,我们提出一种缓存感知的推荐方法,而不需要网络和内容提供商的协作。我们使用推荐系统提供的公开信息,构建了一种缓存友好的和高质量的推荐系统。我们将该方法应用于YouTube服务,对YouTube视频推荐进行测量,使用视频请求进行试验,从而评估缓存命中率方面的可能收益。最后,我们分析研究了我们方法中的缓存优化问题。试验结果表明:可以取得显著的缓存收益;缓存感知的推荐有8-10倍的缓存命中率提升,且缓存优化可以带来额外的2倍的缓存命中率提升(即10-12倍)。
1 INTRODUCTION (引言)
Mobile Edge Caching (MEC) is one of the key technologies for 5G networks [7] that can reduce latency of service delivery and offload traffic from backhaul links. In MEC, caches are located at the edge of the mobile network (e.g., base stations), and thus have limited capacity and serve small –and frequently changing– user populations [10]. These factors, despite the advances in caching policies [10] or delivery techniques [5], limit the possible gains from MEC: capacity is a tiny fraction of today’s content catalogs, and traffic is highly variable; hence, a large number of user requests is for non-cached contents, i.e., not served in the edge.
移动边缘缓存(MEC)是5G网络的关键技术之一[7],可以降低服务交付延迟并卸载回程链路的流量。MEC中,缓存位于移动网络的边缘(如,基站),因此能力有限且服务少数(且频繁变化的)用户[10];这些因素限制了MEC(MEC的缓存能力只是当今内容目录的一小部分,且流量高度变化)的可能增益,尽管缓存策略[10]和交付技术[5]取得进步。因此,大量用户请求的是非缓存内容,即不是由边缘提供服务。
A recently proposed solution for increasing the efficiency of MEC is jointly caching and recommending content [2, 4, 13]. Recommendation Systems (RS) are integrated in many popular services (e.g., YouTube, Netflix) and signifcantly affect the user demand [6, 14]. Therefore, steering recommendations towards cached contents, can signifcantly increase the cache hit ratio, even with small caches or populations.
最近提出的一种提升MEC效率的方法是联合缓存和推荐内容[2,4,13]。推荐系统(RS)是众多流行服务(如YouTube和Netflix)的一部分,并且显著影响用户需求[6,14]。因此,将推荐内容引导到缓存的内容,可以显著提升缓存命中率,即使在缓存容量和数量较少时。
However, joint caching and recommendation requires collaboration between network operators and Content Providers (CPs). This might be challenging, due to the different scope of these entities, and the constraints of current network protocols and architectures. For example, CPs encrypt traffic (e.g., https) and do not typically share user-related information [11].
然而,联合缓存和推荐需要网络操作员和内容提供商(CPs)的协作,这是具有挑战的,因为这些实体的范围不同,以及当前网络协议和架构的限制。例如,CPs加密数据流,并且不共享用户相关的信息[11]。
To bridge this gap, we propose an approach that is applicable in today’s networks: the network operator leverages the information made available by the RS, and, based on this, provides independently of the CP high-quality and cache-friendly recommendations that increase the efficiency of MEC. Specifcally, we consider the YouTube service, and design a system/application that (i) obtains video relations from the YouTube API, based on which (ii) it builds extended lists of directly and indirectly related videos, and (iii) carefully steers initial recommendations –and thus user demand– towards cached videos. These operations can take place without any tight collaboration with the CP, thus facilitating the application of joint caching and recommendation approaches by network operators (or other entities), without any need for modifcations in architectures or protocols.
为了弥补这一鸿沟,我们提出一种适用于当前网络的方法:网络操作员使用RS公开的信息,并基于此提供独立于CP的高质量和缓存友好的推荐内容,以提高MEC的效率。具体地,我们考虑YouTube服务,并设计一种系统/应用来(i)从YouTube API获取视频关系,基于此(ii)构建直接相关和间接相关的扩展视频列表,并且(iii)仔细地引导初始推荐(和用户需求)到缓存的视频。这些操作无需与CP的任何紧密协作,因此促进联合缓存和推荐方法的应用,而不需要修改协议和架构。
Our contributions are summarized as follows:
我们的贡献总结如下:
- We propose an approach that enables joint caching and recommendation, without requiring collaboration between network operators and CPs (Sec. 2).
- 我们提出一种联合缓存和推荐方法,而不需要网络操作员和CPs之间的协作(第2部分)。
- We design an algorithm (named CABaRet) that leverages available information provided by a RS, and returns cache-aware recommendations (Sec. 3) .
- 我们设计了一种算法(称为CABaRet),使用RS提供的公开信息,返回缓存感知的推荐(第3部分)。
- We perform extensive measurements over the YouTube service. Our results show that signifcant caching gains can be achieved in practice; even in conservative scenarios, our approach increases the cache hit ratio by a factor of 8 to 10 (Sec. 4) .
- 我们在YouTube服务上进行深入的测量,结果表明:可以取得显著的缓存增益;即使在保守情形下,我们的方法可以将缓存命中率增加8到10倍(第4部分)。
- We analytically study the problem of caching optimization under recommendations from CABaRet, and propose an approximation algorithm. We show that when caching is controlled by the network operator, an extra 2 times increase in the cache hit ratio can be achieved (Sec. 5).
- 我们分析研究了CABaRet推荐下的缓存优化问题,并提出一种近似算法。我们指出,当由网络操作员控制缓存时,可以取得额外的2倍的缓存命中率的增加。
Finally, while in this paper we focus on the YouTube service, which provides a public API, our approach can be extended to other video/radio services (e.g., Neflix, Vimeo, Spotify, Pandora) as well, e.g., using offline crawling processes (in case APIs are not available) for discovering content relations.
最后,尽管本文我们关注于YouTube服务(提供公开API),我们的方法可以扩展应用于其它视频/音频服务(如Netflix、Vimeo、Spotify和Pandora);比如,使用离线爬虫进程(API不可用的情形下)发现内容关系。
2 SYSTEM OVERVIEW (系统概览)
The proposed approach can be implemented in a lightweight system/application that runs on mobile devices, and is triggered either by the network operator or by the user. The system is composed of the user interface (UI), the back-end, and the recommendation module, as depicted in Fig. 1.
本文提出的方法可以实现为运行在移动设备的轻量级系统/应用,并由网络操作者和用户触发。该系统由用户接口(UI)、后端和推荐模块组成,如图1所示。
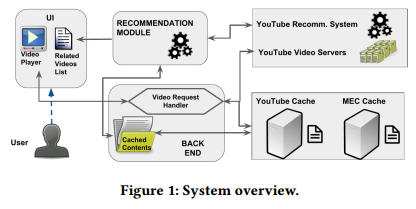
图1:系统概览。
User Interface (UI). The UI resembles the original content service UI. For instance, in the YouTube case, the UI contains a search bar, a video player, and a list of related videos. The users search, browse, and watch videos through the UI.
用户接口(UI)。用户接口类似于原始的内容服务UI。以YouTube为例,UI包含搜索条,视频播放器,和相关视频列表。用户通过UI搜索,浏览并观看视频。
Back-end. The back-end is responsible for (i) retrieving the list of cached video IDs (e.g., in the form of a text file), and (ii) streaming videos to the UI. Depending on the scenario, the list of cached video IDs can be already known to the network operator, e.g., in the case of network-controlled caching. Alternatively, they can be requested from the content provider directly, or discovered through offline network measurements (e.g., latency [9], or DNS resolution [1]) by the network operator. The video requested by the user is delivered/streamed from the CP’s (e.g., YouTube’s) origin server, or the CP’s cache, or an edge cache. In case the caches are controlled by the content provider (which is the most prevalent scenario today), the user-service communication can be encrypted (e.g., https requests directly to YouTube) and remain transparent to the network operator.
后端。后端负责(i)获取已缓存的视频ID(例如,以文本文件的形式),并且(ii)将视频流式传播到UI。根据场景,已缓存视频ID的列表可以是网络操作员已知的(如,在网络控制缓存的情形)。可选地,该列表可以是直接由服务提供商获取的,或者网络操作员通过离线网络测量(如,延迟[9],或DNS解析[1])发现的。用户请求的视频可以由CP(如YouTube)的原始服务器、CP的缓存或者边缘缓存提供。在缓存被内容提供商控制的情形下(当前最流行的情形),用户到服务的通信可能被加密(例如,直接到YouTube的https请求),并且对网络操作员透明。
Recommendation Module. The recommendation module is triggered upon each content request, and (i) receives as input the video v that the user currently watches, (ii) retrieves from the YouTube API a list of video IDs directly/indirectly related to v, (iii) extracts from the back-end the list of cached video IDs, and (iv) builds a list of related and cached video IDs and recommends it to the user, according to the cache-aware recommendation algorithm of Sec. 3. This recommendation process is lightweight and can return the list of recommendations very fast (e.g., ∼1sec. in our prototype), without affecting the user experience.
推荐模块。推荐模块由每次内容请求触发,并且(i)接收用户正在观看的视频v作为输入,(ii)通过YouTube API获取与v直接相关/间接相关的视频ID列表,(iii)由后端获取已缓存的视频ID列表,(iv)构建相关的和已缓存的视频ID列表,并将其推荐给用户(根据第3部分介绍的缓存感知的推荐算法)。推荐过程是轻量级的,并且可以非常快速地返回推荐列表(例如,小于1秒),而不影响用户体验。
3 CACHE-AWARE RECOMMENDATIONS (缓存感知的推荐)
In existing approaches, e.g., [2, 4, 13], the “most related” contents that are also cached, are recommended to users. However, this requires the system to be aware of the content relations (e.g., similarity scores, user preferences/history, trending videos), i.e., information owned by the content provider. Such data are unlikely to be disclosed to third parties, due to privacy and/or economic reasons (e.g., advertising).
现有方法中(如[2,4,13]),最相关的且缓存的内容被推荐给用户。然而,这要求系统能够感知内容的相关性(如,相似度分数,用户偏好/历史,趋势视频),即内容提供商拥有的信息。因为隐私和/或经济原因(如广告),这类数据不太可能对第三方公开。
In our approach, the system leverages information about content relations that is made publicly available by the RS of the content service (i.e., YouTube in this paper). In particular, when a user watches a video v, the system requests from the YouTube API a list of video IDs L related to v, i.e., the videos that YouTube would recommend to the user. Then it requests the related video IDs for every video in L and adds them in the end of L, and so on, in a Breadth-First Search (BFS) manner. In the end of the process, the list L contains IDs of videos directly and indirectly related to v, from which the top N cached and/or highly related to v videos are fnally recommended to the user. The list L is (i) much larger than the list of videos recommended by YouTube, and thus it is more probable to contain cached videos that are related to v, and (ii) built based on video relations provided by YouTube itself, which satisfes a high quality of recommendations.
我们的方法中,系统使用关于内容相关的信息(这些信息由内容服务的RS公开,如本文采用的YouTube)。特别地,当用户观看视频v时,系统通过YouTube API请求与v相关的视频ID列表L,即YouTube将推荐给用户的视频。然后,系统请求L中每个视频的相关视频IDs,并将其添加到L的尾端;以广度优先搜索的方式进行。该进程结束时,列表L包含视频v的直接相关和间接相关视频IDs;前面N个缓存的和/或与视频v高度相关的视频被最终推荐给用户。列表L(i)比YouTube的推荐视频列表大得多,因此具有更高的包含视频v相关的已缓存视频的可能,且(ii)基于YouTube自身提供的视频关系构建,满足高质量推荐的目标。
We detail our recommendation algorithm (CABaRet) in Sec. 3.1, and discuss the related design implications in Sec. 3.2.
我们在3.1节详细介绍推荐算法(CABaRet),在3.2节讨论相关的设计内涵。
3.1 The Recommendation Algorithm (推荐算法)
Input. The recommendation algorithm receives as input:
输入。推荐算法接收如下输入信息:
- v: the video ID (or URL) which is currently watched
- v:正在观看的视频ID(或URL)
- N : the number of videos to be recommended
- N:推荐视频的数量
- C: the list with the IDs of the cached videos
- C:已缓存视频的ID列表
- DBFS: the depth to which the BFS proceeds
- DBFS:BFS处理的深度
- WBFS: the number of related videos that are requested per content from the YouTube API (i.e., the “width” of BFS)
- WBFS:每次由YouTube API请求的相关视频的数量(即,BFS的宽度)
Output. The recommendation algorithm returns as output:
输出。推荐算法的输出为:
- R: ordered list of N video IDs to be recommended.
- R:推荐的N个视频ID的有序列表
Workflow. CABaRet searches for videos related to video v in a BFS manner as follows (line 1 in Algorithm 1). Initially, it requests the WBFS videos related to v, and adds them to a list L in the order they are returned from the YouTube API. For each video in L, it further requests WBFS related videos, as shown in Fig. 2, and adds them in the end of L. It proceeds similarly for the newly added videos, until the depth DBFS is reached; e.g., if DBFS = 2, then L contains WBFS video IDs related to v, and WBFS · WBFS video IDs related to the related videos of v.
工作流。CABaRet以如下方式搜索与视频v相关的视频(算法1的行1)。初始时,请求与视频v相关的WBFS个视频,并将它们添加到列表L(按照YouTube API返回的顺序)。对于L中的每一个视频,进一步请求WBFS个相关视频,如图2所示,并将他们添加到L的尾端。对于新添加的视频也做类似处理,直到达到深度DBFS;例如,如果DBFS=2,那么L包含WBFS个和v相关的视频ID,以及WBFSxWBFS个与视频v相关视频的相关视频。
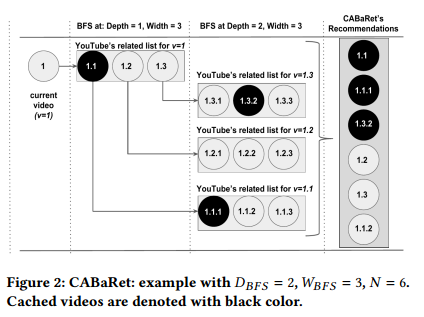
图2:CABaRet:例子中DBFS=2,WBFS=3,N=6.已缓存的视频使用黑色表述。
Then, CABaRet searches for video IDs in L that are also included in the list of cached videos C and adds them to the list of video IDs to be recommended R, until all IDs in L are explored or the list R contains N video IDs, whichever comes frst (lines 4–9). If after this step, R contains less than N video IDs, N - |R| video IDs from the head of the list L are added to R; these IDs correspond to the top N - |R| non-cached videos that are directly related to video v (lines 10–15).
然后,CABaRet搜索存在于L中和已缓存视频列表C中的视频ID,并将它们添加到视频ID列表R(待推荐列表),直到L中的所有ID均被探索,或者列表R中包含N个视频IDs(行4-9)。如果此骤之后,R中包含少于N个视频ID,列表L中的前N-|R|个视频ID被添加到列表R中;这些IDs是与视频v直接相关的但未被缓存的前N-|R|个视频ID(行10-15)。

3.2 Implications and Design Choices (内涵和设计选择)
High-quality recommendations. Using the YouTube recommendations ensures strong relations between videos that are directly related to v (i.e., BFS at depth 1). Moreover, while the YouTube RS finds hundreds of videos highly related to v, only a subset of them are recommended to the user [3]. The rationale behind CABaRet is to explore the related videos that are not communicated to the user. To this end, based on the fact that related videos are similar and have high probability of sharing recommendations (i.e., if video a is related to b, and b to c, then it is probable that c relates to a), CABaRet tries to infer these latent video relations through BFS. Hence, videos found by BFS in depths > 1 are also (indirectly) related to v and probably good recommendations as well.
高质量推荐。使用YouTube推荐内容确保与v相关的视频之间的强相关(即,深度为1的BFS)。此外,尽管YouTube RS查找到数百个与v高度相关的视频,只有一部分被推荐给用户[3]。CABaRet背后的合理性是探索不与用户通信的相关视频。为此,基于事实:相关视频是相似的并且具有很高的共享推荐内容的概率(即,如果视频a与b相关,且b与c相关,那么c很可能与a也相关),CABaRet试图使用BFS推测潜在的视频相关性。因此,BFS中深度大于1的视频与v也是相关的(间接相关)并且可能是好的推荐。
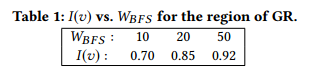
To further support the above claim, we collect and analyze datasets of related YouTube videos. Specifcally, we consider the set of most popular videos, let P, in a region, and for each v ∈ P we perform BFS by requesting the list of related videos (similarly to line 1 in CABaRet). We use as parameters WBFS = {10, 20, 50} and DBFS = 2, i.e., considering the directly related videos (depth 1) and indirectly related videos with depth 2. We denote as R1(v) and R2(v), the set of videos found at the frst and second depth of the BFS, respectively. We calculate the fraction of the videos in R1(v) that are also contained in R2(v), i.e., I(v) = |R1(v)∩R2(v)| |R1(v)| . High values of I(v) indicate a strong similarity of the initial content v with the set of indirectly related contents at depth 2.
为了进一步支持上述表述,我们收集并分析了YouTube相关视频的数据集。具体地,我们考虑某一区域最流行的视频集合P,且对于每个v ∈ P我们执行BFS(通过请求相关视频列表)。我们使用WBFS = {10, 20, 50} 和DBFS = 2作为参数,即考虑直接相关视频(深度为1)和深度为2的间接相关视频。我们以R1(v) and R2(v)表示BFS中深度为1和深度为2的视频集合。我们计算在集合R1(v) 和R2(v)中的视频的比率,即 I(v) = |R1(v)∩R2(v)| /|R1(v)|。较高的I(v)值表明初始内容v和深度为2的间接相关的视频集合高度相似。
Table 1 shows the median values of I(v), over the |P| = 50 most popular contents in the region of Greece (GR), for different BFS widths. As it can be seen, I(v) is very high for most of the initial videos v. For larger values of WBFS , I(v) increases, and when we fully exploit the YouTube API capability, i.e., for WBFS =50, which is the maximum number of related videos returned by the YouTube API, the median value of I(v) becomes larger than 0.9. Finally, we measured the I(v) in other regions as well, and observed that even in large (size/population) regions, the I(v) values remain high, e.g., in the United States (US) region, I(v)=0.8 for WBFS =50.
表1给出希腊(GR)地区|P| = 50个最流行内容的I(v)中间值(对不同的BFS宽度)。对于大多数初始视频v来说,I(v)的值很高。对于较大的WBFS值,I(v)增加;当我们完全利用了YouTube API的能力,即对于WBFS=50(YouTube API返回的相关视频的最大值),I(v)的中间值大于0.9。最后,我们测量了其它区域的I(v),发现即使在大(尺寸/人口密度)地区,I(v)的值依然很高,例如在美国(US)地区,I(v)=0.8(对于WBFS=50)。
Tuning CABaRet. The parameters DBFS ,WBFS can be tuned to achieve a desired performance, e.g., in terms of probability of recommending a cached or highly related video.
调整CABaRet。可以调整参数DBFS和WBFS以取得期望的性能,例如,推荐已缓存或高度相关视频的概率。
For large DBFS , the similarity between v and the videos at the end of the list L is expected to weaken, while for small DBFS the list L is shorter and it is less probable that a cached content is contained in it. Hence, the parameter DBFS can be used to achieve a trade-off between quality of recommendations (small DBFS ) and probability of recommending a cached video (large DBFS). The number of related videos requested per content WBFS, can be interpreted similarly to DBFS. A small WBFS leads to considering only top recommendations per video, while a large WBFS leads to a larger list L.
对于大的DBFS,v和L末端视频的相似度较低;对于小的DBFS,列表L较短,且其包含已缓存内容的概率较小。因此,参数DBFS用于取得推荐质量(小的DBFS)和推荐已缓存视频(大的DBFS)可能性之间的权衡。每次请求的相关视频的数量WBFS的解释类似于DBFS。小的WBFS导致只考虑每个视频的顶部推荐,而大的WBFS导致大的列表L。
Remark: YouTube imposes quotas on the API requests per application per day, which prevents API users from setting the parameters WBFS and DBFS to arbitrarily large values.
说明:YouTube限制每个应用每天API请求的数量,这限制API用户设置较大的WBFS和DBFS的值为任意大的值。
In practice, CABaRet can be fine-tuned through experimentation with real users, e.g., A/B testing iterations, which is a common approach for tuning recommendation systems [3] .
实践中,CABaRet可以通过真实用户的实验精调,例如A/B测试迭代(这是推荐系统中通用的调整策略[3])。
4 MEASUREMENTS AND EVALUATION (测量和评估)
We conduct measurements and experiments over the YouTube service, to investigate the performance (in terms of cache hit ratios) of our approach in MEC scenarios. The setup of the scenarios is presented in Sec. 4.1, and the results in Sec. 4.2.
我们在YouTube服务上进行测量和实验,以研究MEC场景下我们方法的性能(缓存命中率)。4.1节介绍场景设置,4.2节给出结果。
4.1 Setup (设置)
The YouTube API provides a number of functions to retrieve information about videos, channels, user ratings, etc. In our measurements, we request the following information:
YouTube API提供了一系列函数用来查询视频、通道和用户打分等信息。实验中,我们请求如下信息:
- the most popular videos in a region (max. 50)
- 某一地区最流行的视频(最大50)
- the list of related videos (max. 50) for a given video
- 某个给定视频的相关视频列表(最大50)
Remark: In the remainder, we present results collected during March 2018, for the region of Greece (GR). Nevertheless, our insights hold also in the other regions we tested (e.g., US).
说明:本文后续,我们收集了希腊(GR)地区2018年3月份的结果。然而,在我们测试的其它地区,我们的观察仍然成立(如美国US)。
Caching. We assume a MEC cache storing the most popular videos in a region. We populate the list of cached contents with the top C video IDs returned from the YouTube API.
缓存。我们假设一个存储某一地区最流行视频的MEC。我们使用YouTube API返回的顶部C个视频ID填充缓存内容列表。
Recommendations. We consider two classes of scenarios with (i) YouTube and (ii) CABaRet recommendations. In both cases, when a user enters the UI, the 50 most popular videos in her region are recommended to her (as in YouTube’s front page). Upon watching a video v, a list of N = 20 videos is recommended to the user; the list is (i) composed of the top N directly related videos returned from the YouTube API (YouTube scenarios), or (ii) generated by CABaRet with parameters N, WBFS and DBFS (CABaRet scenarios).
推荐内容。我们考虑两种场景:(i)使用YouTube推荐,(ii)使用CABaRet推荐。两种情形下,当用户进入UI,用户所在地区的50个最流行视频推荐给用户(如YouTube的首页)。一旦观看视频v,N=20的列表被推荐给用户;该列表是(i)YouTube API返回的前N个直接相关视频(YouTube场景),或者(ii)使用参数N、WBFS和DBFS的CABaRet产生(CABaRet场景)。
Video Demand. In each experiment, we assume a user that enters the UI and watches one of the initially recommended (i.e., 50 most popular) videos at random. Then, the system recommends a list of N videos (r1,r2, ...,rN ), and the user selects with probability pi to watch ri next. We set the probabilities pi to depend on the order of appearance –and not the content– and consider uniform (pi = N1 ) and Zipf (pi ∼ i1α ) scenarios; the higher the exponent α of the Zipf distribution, the more preference is given by the user to the top recommendations (user preference to top recommendations has been observed in YouTube traffic [9]).
视频需求。每个实验中,我们假设用户进入UI,并随机观看某个初始推荐视频(即,50个最流行视频)。然后,系统推荐包含N个视频的列表 (r1,r2, ...,rN ),用户以概率pi选择观看ri。我们根据出现的位置确定pi的概率,而不是内容;我们考虑平均分布(pi=1/N)和Zipf分布(pi∼ 1/iα)场景;指数α越高,用户越偏爱顶部推荐(YouTube数据流[9]中已经观察到用户偏爱顶部推荐)。
4.2 Results (结果)
4.2.1 Single Requests (单一请求)
We frst consider scenarios of single requests (similarly to [2, 13]). In each experiment i (i = 1, ..., M) a user watches one of the top popular videos, let v1(i), and then follows a recommendation and watches a video v2(i). We measure the Cache Hit Ratio (CHR), which we define as the fraction of the second requests of a user that are for a cached video (since the frst request is always for a cached–top popular– video):
我们首先考虑单一请求的场景(类似于[2,13])。每次实验i中(i = 1, ..., M) ,用户观看某个流行视频v1(i),然后观看某个推荐视频v2(i)。我们测量缓存命中率(CHR),其定义为用户第二次请求的视频是已缓存视频的比例(因为第一个请求总是缓存的流行视频):
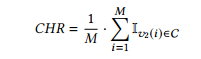
这里,Iv2(i)=1,如果v2(i)∈ C;否则,其值为0;M为实验的次数。
CHR vs. BFS parameters. Fig. 3 shows the CHR achieved by CABaRet under various parameters, along with the CHR under regular YouTube recommendations, when caching all the most popular videos (|C|=50). The efficiency of caching signifcantly increases with CABaRet, even when only directly related contents are recommended (DBFS=1), i.e., without loss in recommendation quality. Just reordering the list of YouTube recommendations (as suggested in [9]), brings gains when pi is not uniformly distributed. However, the added gains by our approach are signifcantly higher. As expected, the CHR increases for larger WBFS and/or DBFS; e.g., CABaRet for WBF S=50 and DBF S=2, achieves 8-10 times higher CHR than regular YouTube recommendations. Also, the CHR increases for more skewed pi distributions, since top recommendations are preferred and CABaRet places cached contents at the top of the recommendation list.
CHR和BFS参数。图3给出不同参数下CABaRet取得的CHR,以及常规YouTube推荐下的CHR(缓存所有的最流行视频,即|C|=50)。CABaRet中缓存效率显著提升,即使在只推荐直接相关内容是(DBFS=1),即不损失推荐质量。仅仅重排序YouTube推荐列表(如[9]所暗示的),在pi不是均为分布时也可以再带增益。然而,我们的方法带来的增益更加显著。正如期望的,对于更大的WBFS和/或DBFS,CHR增加;例如,WBFS=50和DBFS=2的CABaRet比常规YouTube推荐取得8-10倍的更高CHR。同时,对于更加偏斜的pi分布,CHR增加,这是因为偏爱顶部推荐,且CABaRet将缓存的内容放置在推荐列表的顶部。
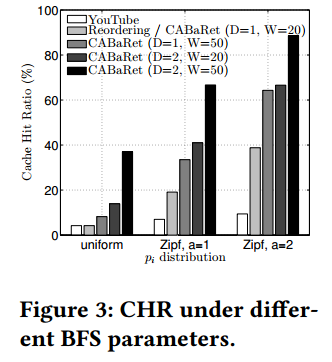
图3:不同BFS参数下的CHR。
In experiments concerning the –larger– US region, the CHR values are lower for both regular YouTube (< 0.5%) and CABaRet (1% - 43%) recommendations, due to the fact that the top popular videos appear with lower frequency in the related lists. However, the relative gains from CABaRet are consistent with (or even higher than) the presented results.
在US地区(更大),实验中CHR的值对常规YouTube(小于0.5%)和CABaRet(1%-43%)推荐都较低,因为流行视频出现在相关列表的频度较低。然而,CABaRet的相对收益与呈现的结果一致(甚至更高)。
CHR vs. number of cached videos. We further consider scenarios with varying number of cached contents C = |C|. In each scenario, we assume that the C most popular contents are cached. Fig. 4 shows the CHR achieved by CABaRet, in comparison to scenarios under regular YouTube recommendations. The results are consistent for all considered values of C; the CHR under CABaRet is signifcantly higher than in the YouTube case. Moreover, even when caching a small subset of the most popular videos, CABaRet brings signifcant gains. E.g., by caching C = 10 out of the 50 top related contents CABaRet increases the CHR from 2% and 3.2% to 17% and 50%, for the uniform and Zipf(α=1) scenarios, respectively.
CHR和已缓存视频的数量。我们进一步考虑已缓存内容数量C = |C|变化的场景。在每个场景中,我们假设C个最流行内容被缓存。图4给出CABaRet取得的CHR,与常规YouTube推荐对比。对于所有的C值,结果是一致的;CABaRet情形下的CHR显著高于YouTube情形。此外,即使只缓存一小部分最流行视频,CABaRet带来显著收益。例如,通过缓存50个相关内容中的C=10个,CABaRet增加了CHR的值,由2%和3.2%增加到17%和50%(分别在均匀分布和Zipf分布(α=1)情景下)。
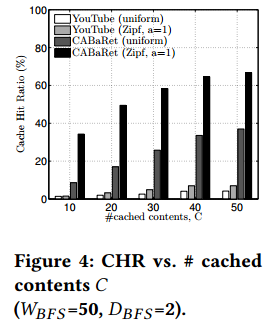
图4: CHR和缓存的内容C(WBFS=50,DBFS=2)
4.2.2 Sequential Requests (顺序请求)
We now test the performance of our approach in scenarios where users enter the system and watch a sequence of K, K > 2, videos (similarly to [4], and in contrast to the previous case, where they watch only two videos, i.e., K = 2). At each step, the system recommends a list of videos to the user by applying CABaRet on the currently watched video. We denote as vk (i) the kth video requested/watched by a user in experiment i. We measure the CHR, which is now defned as
现在,我们测试如下场景下我们方法的性能:用户进入系统,并顺序观看K(K>2)个视频(类似于[4],与前面的情形相比,它们只观看两个视频,即K=2)。在每一步,系统根据当前观看的视频使用CABaRet给用户推荐视频列表。我们以vk (i) 表示在i次实验中用户请求/观看的第k个视频。我们测量CHR,定义如下:
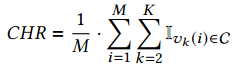
Ivk (i)∈C = 1,如果 vk (i) ∈ C ,否则其值为0。在每个场景下,进行M=100次试验。
Moving “farther” from the initially requested video (which belongs to the list of most popular and cached videos) through a sequence of requests, we expect the CHR to decrease, due to lower similarity of the requested and cached videos. However, as Fig. 5 shows, the decrease in the CHR (under CABaRet recommendations) is not large. The CHR remains close to the case of single requests (i.e., for K=2 in the x-axis), indicating that our approach performs well even when we are several steps far from the cached videos. In fact, caching more than the top most popular videos appearing on the front page, would further reduce the CHR decrease.
通过顺序请求,从初始请求视频(属于最流行视频和已缓存视频列表)移动的越远,我们期望CHR降低,因为请求的和缓存的视频的低相似性。然而,如图5所示,CHR的减少值不大(在CABaRet推荐下)。CHR仍然和单一请求情景下接近(即,x轴上的K=2),表明我们的方法表现良好,即使我们和已缓存视频有多步远。事实上,缓存多于首页显示的最流行视频可以进一步减少CHR的减少。
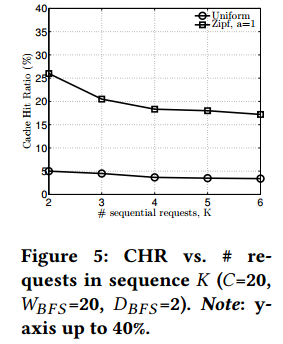
图5: CHR和顺序请求数量K对比(C=20,WBFS=20,DBFS=2)。注意:y轴高达40%。
5 CACHING OPTIMIZATION (缓存优化)
In this section, we extend our study by considering the scenario where CABaRet and the caches are controlled by the same entity, e.g., the network operator. Network operator-controlled caching is the most commonly considered scenario in related work for MEC; although in most of today’s architectures the caches are actually controlled by the CP.
本节,我们通过考虑如下场景扩展我们的研究:CABaRet和缓存由同一实体控制,如网络操作者。网络操作者控制的缓存是MEC相关工作考虑的最通用场景;即使在今天的架构下,缓存由CP控制。
In this scenario, the network operator can optimize caching decisions, thus further increasing the efficiency of CABaRet recommendations. Note that still there is no need for collaboration between the operator and the CP (e.g., possessing full knowledge of the RS), assumed in previous works [2, 4, 13].
这种场景下,网络操作者可以优化缓存决策,以进一步增加CABaRet推荐的效率。注意,操作者和CP之间没有协作的必要(例如,拥有RS的所有知识),如前期工作[2,4,13]中假设的。
In the following, we first analytically formulate and study the problem of optimizing the caching policy, and propose an approximation algorithm with provable performance guarantees (Sec. 5.1). We then evaluate the performance of this joint caching and recommendation approach (Sec. 5.2).
下面,我们首先研究缓存策略优化问题,并提出一种近似算法(具有性能保证的,见5.1节)。我们然后评估这种联合缓存和推荐方法的性能(5.2节)。
5.1 Optimization Problem & Algorithm (优化问题和算法)
Let a content catalog V, V = |V|, and a content popularity vector q = [q1, ...,qV ]T . Let L(v) ⊆ V be the set of contents that are explored by CABaRet (at line 1) for a content v ∈ V, and denote L = Uv ∈V L(v).
以V表示内容目录,V = |V|表示内容目录的大小,以q= [q1, ...,qV ]T表示内容流行度向量。以L(v) ⊆ V表示(对v∈ V)CABaRet探索的内容集合(行1),定义L= Uv ∈V L(v) 。
For some set of cached contents C ⊆ V, and a content v, CABaRet returns a list of recommendations R(v) (|R(v)| = N), in which at most N contents c ∈ C ∩ L(v) appear at the top of the list. Therefore, CHR can be expressed as:
对于某个缓存的内容集合C ⊆ V,和内容v,CABaRet返回推荐列表R(v) (|R(v)| = N),其中最多N个内容c ∈ C ∩ L(v) 出现在列表顶部。因此,CHR定义如下:
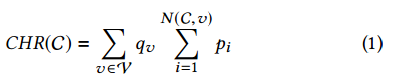
where N (C,v) = min{|C ∩ L(v)|, N }, and pi is the probability for a user to select the ith recommended content.
这里,N (C,v) = min{|C ∩ L(v)|, N },pi表示用户选择第i个推荐内容的概率。
Then, the problem of optimizing the caching policy (to be jointly used with CABaRet), is formulated as follows:
那么,缓存策略优化问题(和CABaRet联合使用)可以形式化表示如下:
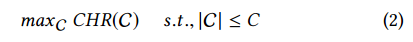
whereC is the capacity of the –MEC– cache. We prove the following for the optimization problem of Eq. (2).
这里C是MEC缓存的容量。我们接下来证明公式(2)的优化问题。
Lemma 1. The optimization problem of Eq. (2): (i) is NP-hard, (ii) cannot be approximated within 1 - e1 + o(1) in polynomial time, and (iii) has a monotone (non-decreasing) submodular objective function, and is subject to a cardinality constraint.
定理1:公式(2)的优化问题:(i)是NP难的,(ii)在1 - 1/e + o(1)多项式时间内无法近似,和(iii)具有单调(非减)目标函数,并且受限于基数限制。
Proof. Items (i) and (ii) of the above lemma, are proven by reduction to the maximum set coverage problem, and we prove item (iii) using standard methods (see, e.g., [5, 13]). The detailed proof is omitted due to space limitations.
证明。上述定理中的项(i)和(ii)通过约简为最大集合覆盖问题证明,我们使用标准方法证明项(iii)(见[5,13])。由于篇幅所限,省略详细的证明。
If we design a greedy algorithm that starts from an empty set of cached contents Cд = ∅, and at each iteration it augments the set Cд (until |Cд | = C) as follows:
如果我们设计一个贪心算法,该算法由空的缓存内容集合Cд = ∅开始,在每一次迭代中,我们如下增强结合Cд,知道|Cд|=C:
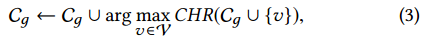
then the properties stated in item (iii) satisfy that it holds [8]
那么,项(iii)中阐述的属性满足他所保持的[8]。
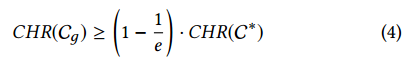
where C∗ the optimal solution of the problem of Eq. (2).
这里, C∗是公式(2)中问题的最优解。
Remark: While Eq. (4) gives a lower bound for the performance of the greedy algorithm, in practice greedy algorithms have been shown to perform often very close to the optimal.
说明:尽管公式(4)给出贪心算法性能的下界,实践中贪心算法被证明常常非常接近最优解。
5.2 Evaluation of Greedy Caching (贪心缓存评估)
Calculating the CHR from Eq. (1) requires running a BFS (CABaRet, line 1) and generating the lists L(v), for every content v ∈ V. In practice, for scalability reasons, the most popular contents (i.e., with high qi) can be considered by the greedy algorithm in the calculation of the objective function Eq. (1), since those contribute more to the objective function. However, any video in the catalog is still candidate to be cached, e.g., a video with low qi can bring a large increase in the CHR through its association with many popular contents.
由公式(1)计算CHR需要运行BFS(CABaRet,行1)并为每个内容v∈ V产生列表L(v)。实践中,为了可扩展,最流行内容(即高qi)可有由贪心算法在计算公式(1)中目标函数时考虑,因为那些内容对目标函数的贡献更多。然而,目录中的任意视频仍然是被缓存的候选者,例如,低qi的视频可以带来CHR的大的增加(通过其与许多流行内容的关联)。
In fact, in our experiments, for the calculation of Eq. (1), we consider only the 50 most popular videos, for which we set qi = 1/50. Nevertheless, in the different scenarios we tested, only 10% to 30% of the cached videos (selected by the greedy algorithm) were also in the top 50 most popular.
事实上,我们的实验中,为了计算公式(1),我们只考虑50个最流行视频,并且设置qi=1/50。然而,在我们测试的不同场景下,只有10%到30%的已缓存视频(贪心算法选择)同时在50个最流行视频中。
In Fig. 6, we compare the achieved CHR when the cache is populated according to the greedy algorithm of Eq. (3) (Greedy Caching), and with the top most popular videos (Top Caching). Greedy caching always outperforms top caching, with an increase in the CHR of around a factor of 2 for uniform video selection (for the Zipf(a=1) scenarios we tested, the CHR values are even higher, and the relative performance is 1.5 times higher). This clearly demonstrates that the gains from joint recommendation and caching [2, 13], are applicable even in simple practical scenarios (e.g., CABaRet & greedy caching). Finally, while greedy caching increases the CHR even with regular YouTube recommendations, the CHR is still less than 50% of the CABaRet case with top caching. This further stresses the benefts from CABaRet’s cache-aware recommendations.
图6中,我们比较了当缓存由公式(3)表示的贪心算法填充(贪心缓存)情形下和最流行视频(Top缓存)情形下的CHR。贪心缓存总是优于top缓存:对于均匀分布视频选择来说,CHR约增加了2倍(对于Zipf(a=1),CHR的值更高,且相对性能高1.5倍)。这清晰地表明:联合推荐和缓存[2,13]带来的增益在简单场景下也适用(例如,CABaRet和贪心缓存)。最后,尽管使用常规YouTube推荐贪心缓存可以增加CHR,CHR比使用top缓存的CABaRet低50%。这进一步强调了CABaRet的缓存感知的推荐的好处。
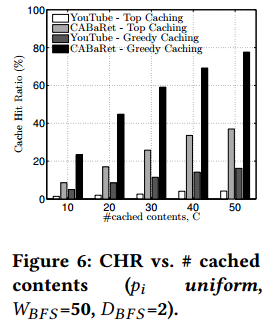
图6:CHR与已缓存内容的对比(pi均匀分布,WBFS=50,DBFS=2)