简答题:
以下代码:
import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object JoinDemo { def main(args: Array[String]): Unit = { val conf = new SparkConf().setAppName(this.getClass.getCanonicalName.init).setMaster("local[*]") val sc = new SparkContext(conf) sc.setLogLevel("WARN") val random = scala.util.Random val col1 = Range(1, 50).map(idx = (random.nextInt(10), s"user$idx")) val col2 = Array((0, "BJ"), (1, "SH"), (2, "GZ"), (3, "SZ"), (4, "TJ"), (5, "CQ"), (6, "HZ"), (7, "NJ"), (8, "WH"), (0, "CD")) val rdd1: RDD[(Int, String)] = sc.makeRDD(col1) val rdd2: RDD[(Int, String)] = sc.makeRDD(col2) val rdd3: RDD[(Int, (String, String))] = rdd1.join(rdd2) println(rdd3.dependencies) val rdd4: RDD[(Int, (String, String))] = rdd1.partitionBy(new HashPartitioner(3)).join(rdd2.partitionBy(newHashPartitioner(3))) println(rdd4.dependencies) sc.stop() } }
问题:
两个打印语句的结果是什么,对应的依赖是宽依赖还是窄依赖,为什么会是这个结果;
join 操作何时是宽依赖,何时是窄依赖;
借助 join 相关源码,回答以上问题。
解答详情
代码样例
import org.apache.spark.rdd.RDD import org.apache.spark.{HashPartitioner, SparkConf, SparkContext} object JoinDemo { def main(args: Array[String]): Unit = { val conf = new SparkConf().setAppName(this.getClass.getCanonicalName.init).setMaster("local[*]") conf.set("spark.testing.memory", "2147480000") val sc = new SparkContext(conf) sc.setLogLevel("WARN") val random = scala.util.Random val col1 = Range(1, 50).map(idx => (random.nextInt(10), s"user$idx")) val col2 = Array((0, "BJ"), (1, "SH"), (2, "GZ"), (3, "SZ"), (4, "TJ"), (5, "CQ"), (6, "HZ"), (7, "NJ"), (8, "WH"), (0, "CD")) val rdd1: RDD[(Int, String)] = sc.makeRDD(col1) val rdd2: RDD[(Int, String)] = sc.makeRDD(col2) val rdd3: RDD[(Int, (String, String))] = rdd1.join(rdd2) println("join-rdd3:====================") println("rdd1:====================") println(rdd1.partitioner) println(rdd1.getNumPartitions) rdd1.glom.collect.foreach(x=>println(x.toBuffer)) println("rdd2:====================") println(rdd2.partitioner) println(rdd2.getNumPartitions) rdd2.glom.collect.foreach(x=>println(x.toBuffer)) val rdd1p: RDD[(Int, String)] = rdd1.partitionBy(new HashPartitioner(3)) val rdd2p: RDD[(Int, String)] = rdd2.partitionBy(new HashPartitioner(3)) val rdd4: RDD[(Int, (String, String))] = rdd1p.join(rdd2p) println("join-rdd4:====================") println("rdd1p:====================") println(rdd1p.partitioner) println(rdd1p.getNumPartitions) rdd1p.glom.collect.foreach(x=>println(x.toBuffer)) println("rdd2p:====================") println(rdd2p.partitioner) println(rdd2p.getNumPartitions) rdd2p.glom.collect.foreach(x=>println(x.toBuffer)) sc.stop() } }
打印结果
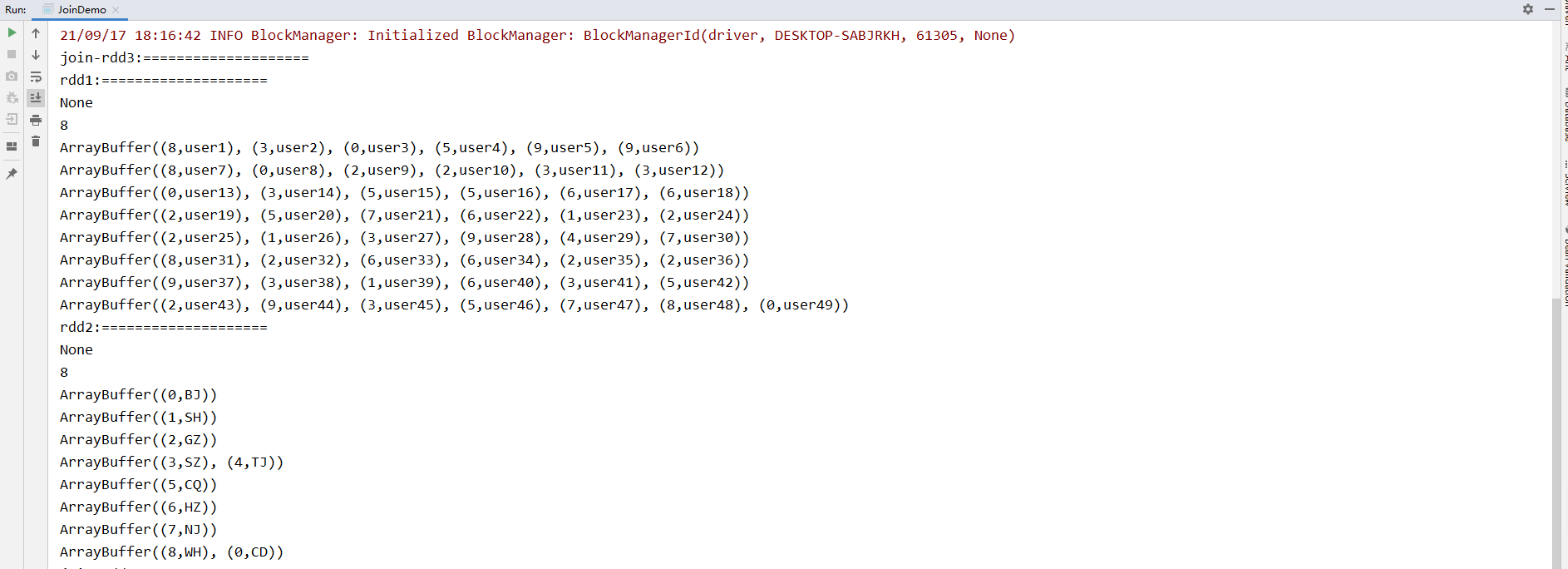

分析解释:
从打印数据看到,rdd1和rdd2本身都是没有分区器的,虽然默认都被分了16个分区,但从数据上看相同的key并没有落到相同的分区里,所有rdd1.join(rdd2)本身是需要对原始数据进行分区移动的,也就是rdd1,rdd2中本身分区中的数据可能去往rdd3的任何分区,这个操作是宽依赖。
但是,rdd4的产生,是rdd1和rdd2本身已经做了hash分区了,产生的rdd1p和rdd2p是有分区器,分区数相同,相同的key在相同分区。所以join的时候,rdd1p和rdd2p的数据并不会乱跑,会走向rdd4中的对应分区,这个操作是窄依赖 。