Ruby 101:行为驱动
Written by Allen Lee
写下你的期望
在上一篇文章里,我们创建了一个简易的插件系统,还为它写了一个YAML导出器,这次,我们将会尝试写个SQLite导出器,并探讨开发过程中的遇到的问题。
首先,我们的插件系统会自动装载插件,这意味着,当应用程序启动好后,插件就应该准备就绪了,这既是我们期望的效果,也是将来测试的时候需要覆盖到的内容,其重要性犹如航标灯塔,指引着正确的开发方向,既然如此,何不把它正式地记录下来:
当应用程序启动好后,SQLite导出器就应该准备就绪了。
不难预料,类似的描述还有很多很多,如果我们把这些描述收集起来,我们将会得到一份规范文档,如果这份规范文档还可以执行的话,我们就可以随时随地验证插件的行为了。噢,别误会,我不是在开玩笑,下面,我们来看看如何实现一份可执行的规范文档。
如果你和我一样都是使用NetBeans,那么你只需在Project窗口里右击RSpec Files文件夹,然后选择New\RSpec File菜单项:
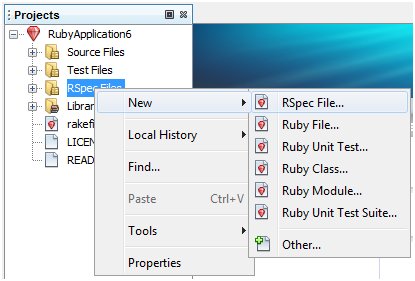
图 1
随后,你将会看到下面这个对话框:
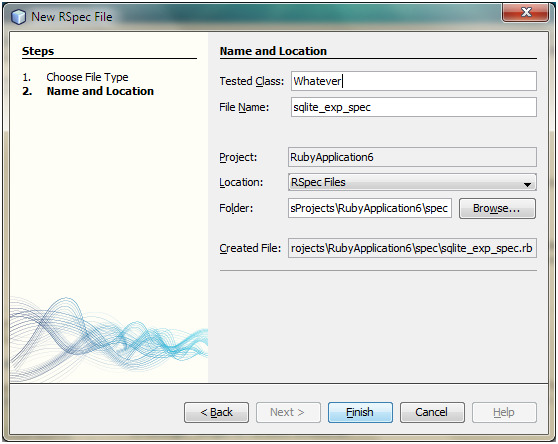
图 2
一般而言,每份规范文件都对应一个目标类,这点从上图也可以看出来,但是,我们要开发的SQLite导出器不是一个类,而是AddIn类的一个实例,那么,Tested Class文本框应该怎么填呢?随便填,只要规范文件的名字和路径没有问题就行了(规范文件的名字通常以spec结尾)。单击Finish按钮,NetBeans将会为你创建如下代码:

代码 1
从上面代码可以看到,NetBeans假定我们的目标类(我们随便填的Whatever类)是在whatever.rb文件里的,于是为我们加载这个文件,还为我们创建一个Whatever类的实例。当然,我们心知肚明,这些假设对于我们的情况并不适用,那么,我们应该如何修改这份规范文档呢?首先,插件是通过插件系统来访问的,为了访问插件系统,我们需要加载addins.rb这个文件;其次,我们要描述的不是一个类,而是一个实例,我们可以为describe方法提供一个字符串,用于标识我们的SQLite导出器;最后,我们不需要实例化什么,因为插件系统已经帮我们处理了,所以我们可以去掉before这块代码了。根据这些建议,我们可以把规范文件修改如下:

代码 2
接下来,我们可以实现前面提到那个描述了:

代码 3
我相信,这份代码已经很直观地阐明它要做的事了。如果我们现在执行这份规范文档,我们将会得到如下结果:

图 3
失败是正常的,毕竟我们还没有实现SQLite导出器嘛。现在,我们创建一个sqlite_exp.rb文件,并在里面写下这些代码:
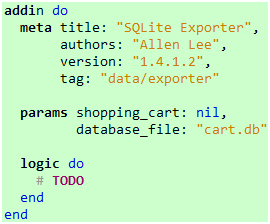
代码 4
然后在addins.rb文件里注册sqlite_exp.rb文件:

代码 5
再次执行规范文档:
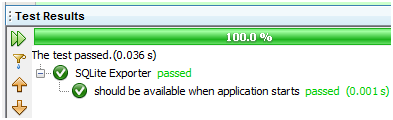
图 4
结果正如我们预料的那样,通过了!
回顾上面整个过程,有没有觉得它和TDD很像?如果有,那么你的感觉是对的,但它和TDD还是有一点儿不一样的,它也有自己的名字,叫做BDD,全名是行为驱动开发(Behavior-Driven Development),而RSpec则是Ruby的BDD框架。如果你有兴趣进一步了解BDD,可以读一读behaviour-driven.org上的介绍,这篇介绍也提到了TDD和BDD的关系。
噢,忘记说个事儿了,如果你发现规范文档无法执行,那么你很可能还没安装RSpec,你可以通过如下方式进行确认:

图 5
如果确认没有安装,可以通过gem install rspec命令进行安装(Linux平台需要在前面加上sudo)。
期望2:把数据写入数据库
毫无疑问,这个期望是最重要的,试想一下,如果SQLite输出器无法保存数据,我还要它来干什么呢?事不宜迟了,赶快在规范文档里写下这个期望吧:

代码 6
现在的问题是,里面的逻辑怎么办?别担心,我们可以先界定整体方向,然后逐步深入细节。
一般而言,每个期望都包含两个要点:执行预设操作和验证预期效果。在这里,预设操作包括查找并获取SQLite输出器、提供完整有效的测试数据以及执行输出器的主体逻辑,这些都不难实现:
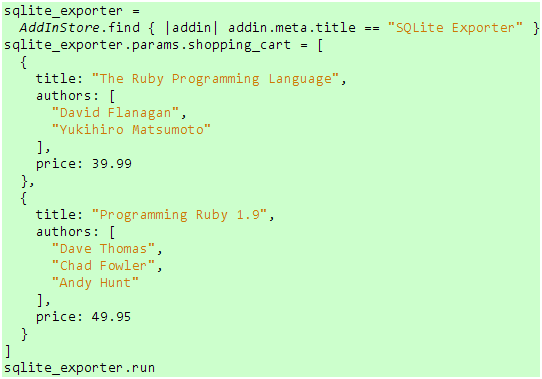
代码 7
接下来是验证预期效果,执行上述操作肯定会产生一个数据库文件,我们可以先验证这个文件是否存在:
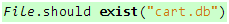
代码 8
我相信上面这句一点都不难理解,但你可能会好奇它是如何工作的。当RSpec执行规范文档时,它会在每个对象上定义should和should_not方法,这些方法接受Matcher对象作为参数,代码2的exist方法会返回一个使用File对象的exist?方法进行判断的Matcher对象,而我们传给exist方法的参数也会传给File对象的exist?方法。那么,如何验证数据是否写进去了呢?最直接的办法就是查一下数据库:

代码 9
我们首先创建一个Database对象,然后通过它的execute方法执行一条SQL语句,这将会返回cart表的所有数据。由于前面写入的是两本书,我们期望现在查到的也是两本书,需要说明的是,第三句最后的books是RSpec提供的语法糖,你可以把它换成items、elements或者其它你认为更加合适的单词,这样,当你把这句话的符号都去掉后,就会得到一个标准的英语句子了:cart should have 2 books,这句话也充分表达了我们的期望。最后是关闭数据库对象。当然,要让这些代码工作,你还需要加上require 'sqlite3'。
为了避免多个测试之间出现数据干扰,我们应该在完成每个测试之后删除产生的数据库文件,这项任务可以在after方法的代码块里完成:
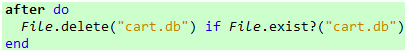
代码 10
此外,由于每个测试都需要使用SQLite输出器,我们不妨把查找并获取SQLite输出器的工作放到before方法的代码块里:

代码 11
当然,代码3和代码7都要做相应的调整,首先,它们不需要查找并获取SQLite输出器了,其次,对本地变量sqlite_exporter的引用要改为对实例变量@sqlite_exporter的引用。嗯?实例变量?谁的实例变量?事实上,describe方法会创建一个ExampleGroup对象,而我们在before方法的代码块里创建的实例变量则隶属于这个ExampleGroup对象。还有一点需要说明的,默认情况下,before方法的代码块会在每个测试执行之前执行,如果你想让它在所有测试执行之前执行,而且就执行一次,你可以通过参数来指定:

代码 12
这种做法也适用于于after方法。
噢,又忘记说了,在使用SQLite之前请先安装SQLite3数据库及其Ruby Gem。SQLite3数据库的安装极其简单,到官网下载sqlite-3_6_22.zip和sqlitedll-3_6_22.zip,解压至任意目录(比如C:\SQLite),然后在PATH环境变量里添加这个路径就行了;SQLite3的Ruby Gem也很容易安装,只需在命令行输入gem install sqlite3-ruby就行了。
实现2:把数据写入数据库
SQLite输出器的工作其实很简单,就三个事儿:创建数据库文件、创建表和把数据写入表。
第一个事儿好办,只需下面这句就搞定了:
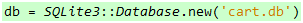
代码 13
嗯?这句好像哪里见过?是的,前面打开数据库文件时用的也是这句,事实上,当你执行这句时,它会试图打开指定的数据库文件,如果这个文件不存在,它就会创建一个新的。在继续之前,请允许我开个小差,试想一下,每次访问SQLite数据库时,我们要创建一个Database对象,访问完后我们要调用close方法释放相关的资源,如果Ruby有像C#的using语法就好了。天啊,难道这个想法只能是个想法吗?慢着!我记得F#就有using,但F#的using并不是语法的一部分,而是一个函数,我们可以这样使用using函数:

图 6
显然,这个做法完全可以借鉴过来:

代码 14
事实上,实现这个using方法一点都不难:

代码 15
这里的begin … ensure … end相当于C#的try … finally,由于begin … ensure … end以外没有其它代码,我们可以把using方法的实现进一步简化成:

代码 16
嗯,不错,但如果我随便拿个对象来用呢,比如这样:

代码 17
毫无疑问,ensure部分会抛出异常,因为没有close方法可以调用,对于这种情况,我期望using方法先看看有没有close方法调用,有就调用,没就拉倒,怎么做到呢?还记得respond_to?方法吗,我们可以通过它来检测close方法是否存在:

代码 18
前几天ruby-talk上也有人问Ruby是否有像C#的using语法,于是我把代码放上去,随即有人提出对象可以调用的方法和respond_to?方法了解的可能不同:
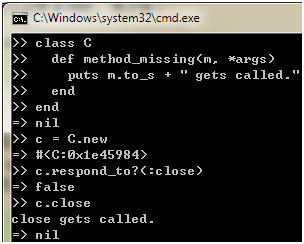
代码 19
并建议我们换用如下代码:

代码 20
我们可以这样理解ensure里面的那句:尝试调用close方法,忽略任何抛出的异常。相比之下,这种做法简洁有效,但是,它带来的风险也是不容忽视的,它可能会把close方法抛出的其它异常也吃掉,最保险的做法应该是只处理NoMethodError异常,但由于上面这种简化写法不能指定待处理的异常类型,于是我们只好换用完整的异常处理语法了:

代码 21
那么,如果目标资源是通过其它方法来释放的呢?这样的话,我们可以考虑让调用方配置用于释放资源的方法:

代码 22
这个不难做到,只需给using增加一个参数就行了:
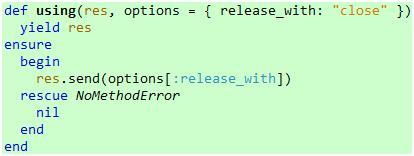
代码 23
默认情况下,我们使用close方法。此外,在使用using方法时,也不是一定要通过代码块的参数把资源传递给代码块的,事实上,我们完全可以写成这样:

代码 24
嗯,看起来和C#的几乎一样了,但有一点需要注意的,就是一定要把{和using放在同一行,否则不符合代码块的语法,毕竟这不是真货啊,哈哈~
回到正题,SQLite输出器要做的第二件事儿是创建一个cart表,这其实也是一句话的事儿:
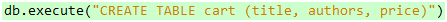
代码 25
嗯?奇怪了,类型呢?不如我们试一下存点东西,看看存进去的是什么:
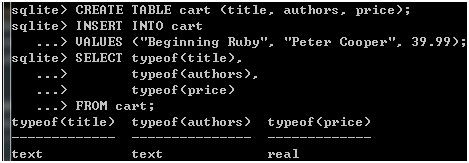
图 7
噢!我的类型啊!毫无疑问,SQLite理解我的期望,并按我期望的方式工作着。那么,如果我插入不同类型的数据呢,比如这样:
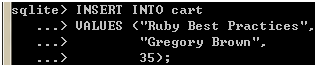
图 8
33.99是浮点数,并被正确地解析为REAL了,而35是整数,它会被"正确地"解析为整数还是被转换为REAL呢?我们查查看:

图 9
噢!数据的类型得到正确的解析了,但是,不可思议的事情也发生了,同一列存在不同类型的数据!由此可见,SQLite对列的处理更像动态语言对变量的处理,其类型取决于实际数据,那么,如果我希望把35处理成REAL呢?我们可以向SQLite建议,由于SQLite的ALTER TABLE只支持重命名和加字段,要添加类型建议只好重新建一个表了:
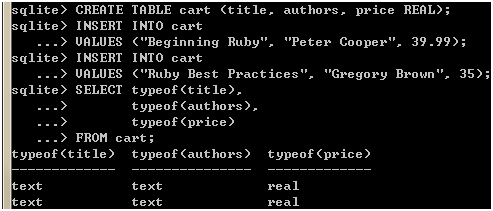
图 10
很好!如果我插入的既不是REAL也不是INTEGER,而是TEXT呢?我们试试看:

图 11
毫无疑问,我们得到了期望的结果,但是,如果SQLite发现你给的字符串无法转换,比如ABC,它会原样保留,而不是禁止你插入,这就是为什么我刚才说"向SQLite建议"而不是"命令SQLite"。现在,我想建议SQLite把title和authors处理成TEXT,排序时不区分大小写,并且组合起来是唯一的(即书名和作者都一样的书看作同一本书),此外,三个字段都不允许为NULL,那么,我们可以把代码24改成这样:

代码 26
你可能会奇怪为什么没有主键,事实上是有的,无论你是否创建你自己的主键,SQLite都会为你创建一个,你可以通过ROWID、_ROWID_或者OID来访问(注意,.width命令用于调整各列的显式宽度):

图 12
如果你创建了一个"类型"正好为INTEGER PRIMARY KEY的字段,SQLite将会把它看作ROWID的"分身";如果你创建的主键是其它类型甚至是组合主键,那么PRIMARY KEY的效果只是相当于UNIQUE,真正参与到B-Tree实现的是ROWID。
最后一个事儿是往表里插数据,最直接的做法是迭代shopping_cart,使用里面的数据拼接SQL语句,然后交给execute方法执行:

代码 27
此外,Database对象还提供了一个prepare方法,可以预先处理带有占位符的SQL语句,并返回一个Statement对象,你可以通过它的bind_param方法或者bind_params方法把数据绑定到占位符上(前者用于绑定单个数据,后者用于绑定多个数据),然后调用它的execute方法执行完整的SQL语句,你也可以直接调用它的execute方法,并提供待绑定的参数:

代码 28
那么,这两种做法的效率分别如何呢?我们可以用Ruby自带的Benchmark模块做个测试(需要添加require 'benchmark'):

代码 29
为了避免数据库文件的干扰,我分别为它们配置了独立的数据库文件(db1和db2),以下是它们分别插入1000条记录的测试结果:
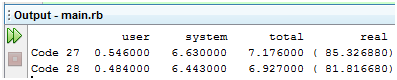
图 13
注意,这里的测试结果仅起示意作用,你不能把它看作判断基准,你应该使用这里介绍的办法在真实环境或仿真环境里实地测试一下才能下结论。值得提醒的是,参数是按顺序绑定的,你也可以使用命名绑定:

代码 30
命名绑定可以打乱顺序,只要Hash对象的键能和SQL语句的命名占位符对应起来就行了。
好了,不知不觉紧张时刻又到了!干什么?当然是执行规范文档啦:
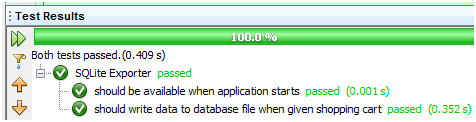
图 14
通过啦!哎,每当看到此番景象,我的心就会感到很踏实,不知道你会不会也是这样呢?
其它期望
我们知道,规范文档本身也是代码,里面的期望也是一个一个地完成的,对于那些还没完成的期望,我们希望它们能出现在规范文档而不是我们的脑子里,但要和已经完成的期望区分开来,怎么才能做到呢?非常简单,比如说我现在对SQLite输出器有两个期望:
- 如果shopping_cart是nil,SQLite输出器应该抛异常。
- 如果shopping_cart里面有重复的(即书名和作者都是一样的,但价钱可能不一样),那么后面的应该自动覆盖前面的。
我只需在规范文档里这样做就行了:
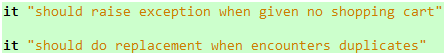
代码 31
如果我们此时执行规范文档,将会看到如下结果:

图 15
这意味着我们的规范文档还没完成,但不会妨碍已经完成的正常工作。
第三个期望很容易实现:

代码 32
我们把待执行的代码放在一个lambda里,然后断言执行这个lambda会抛异常,注意,我们既没直接执行目标代码,也没执行包含目标代码的lambda,这一切都是交给RSpec来完成的。现在转到SQLite输出器的代码,在logic do下面加上这句:

代码 33
好了,我们执行一下规范文档看看结果如何:
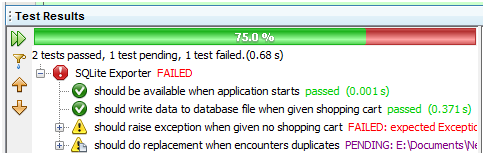
图 16
哎哟,奇怪了,我明明还没提供数据啊,SQLite输出器应该抛异常才对的呀,为什么会这样呢?一开始shopping_cart是nil的,现在我还没给它赋值就有数据了,显然是前面某个测试的遗留影响,为了排除这些影响,我们可以在after方法的代码块里把它清空:

代码 34
现在,再次执行规范文档:
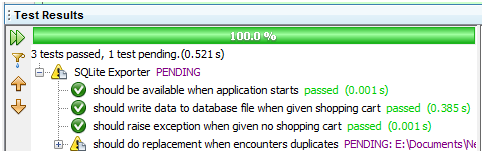
图 17
成功了!
第四个期望也很容易实现,它几乎和第二个期望一样,都包含了提供测试数据、执行输出器、验证数据库文件和验证插入数据的数目等几个步骤,唯一不同的是这里提供的数据包含重复:

代码 35
在第二个期望的实现里,我们通过SELECT * FROM cart把所有数据取出,然后验证插入数据的数目,显然,我们不必这样做,我们可以通过SELECT COUNT(*) FROM cart直接获取插入数据的数目,然后验证这个数目。Database对象提供了一个get_first_value方法,用于获取查询结果的第一行的第一个值,正好满足我们的需求:

代码 36
值得一提的是should eql "2"这部分代码,eql是一个方法,如果你有FP背景,你可能会想,Ruby啥时候支持把方法当做值传递啦,事实上,不是这么一回事儿的,对于任意的x y z,Ruby会把它理解成z是y方法的参数,y方法的返回值才是x方法的参数,即x(y(z)),换句话说,should eql "2"其实是should(eql("2"))。
现在的问题是,这部分功能如何实现?两个显而易见的做法是,要么先SELECT一下,没就INSERT,有就UPDATE,要么先SELECT一下,有就DELETE,然后INSERT,然而,无论哪种做法都不见得有多方便,怎么办?别担心,SQLite提供的冲突处理(conflict resolution)正好派上用场,INSERT的冲突处理语法是:
INSERT OR resolution INTO table (…) VALUES (…);
其中,resolution可以是ABORT、FAIL、IGNORE、REPLACE和ROLLBACK中的任何一个,不难猜测,REPLACE正是我们想要的,于是,我们只需把插入数据的SQL语句改成INSERT OR REPLACE INTO cart VALUES (?, ?, ?)就行了。噢,不知不觉紧张时刻又到了!最后的结果是:
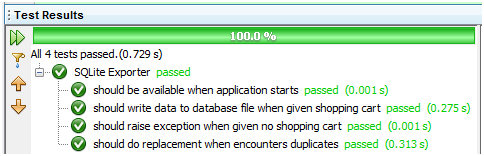
图 18
嗯,非常好!此外,值得一提的是,SQLite还特意为INSERT OR REPLACE提供了一个"外号"——REPLACE,使用这个"外号",上面那句SQL语句可以简化成REPLACE INTO cart VALUES (?, ?, ?)。
最后,我在想,有没有办法把这个结果输出成一份报告呢,比如说HTML格式的?可以的,这个时候就轮到RSpec的命令行工具出场了,打开cmd,切换到规范文档所在目录,然后执行下面这条命令:
spec sqlite_exp_spec.rb --format html:sqlite_exp_spec.html
完成之后你将会得到这样一份报告:
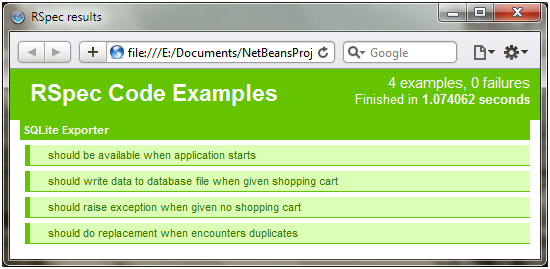
图 19
如果执行结果包含未通过和未完成的呢?我们不妨修改一下规范文档,让第三个失败,去掉第四个的实现,然后再执行上面那条命令,我们将会得到这样一份报告:

图 20
哎哟,不错哦,这份报告除了告诉你失败的原因,还把导致失败的那行代码给挑出来了。
还有啥事儿没做的吗,噢,差点忘记了,还有一个期望呢:
- it "应该能让你学到点儿什么 :)"
新的旅程
你喜欢向别人推荐自己喜欢的技术吗?第一次接触BDD的时候,第一个冲进我脑子的问题是:它和TDD有什么不同,它要取代TDD吗?你还记得,有过几次,你真诚地向别人推荐某个技术,最后却怎么也想不通局势为何会发展成你在强迫别人接受你的好意,而别人则厌恶地反驳你的建议。更糟糕的是,你甚至会把拒绝你的好意和拒绝你本人等同起来,而别人则把你向他推荐新技术的做法理解成你在暗示他现有的技术应该被淘汰,误会也因此产生了。你的出发点其实很简单,而且是善意的,你希望把自己认为最好的推荐给别人,并期望得到别人的认同,但是很不幸,意外常常悄然来袭,随后而来的可能是你的心灰意冷以及你和别人之间的紧张关系。
前一阵子,我和我表弟经常讨论电影,我们相互推荐各自喜欢的电影,与此同时,我们也发现双方的喜好竟然如此不同,我看过的很多电影他都没看过,而他看过的很多电影我也没看过,每到此时,气氛都会突然变得兴奋和激动,我们会和对方说:哇,这么多好看的电影你都没看,真希望自己也像你那样都没看过啊。一方面,我们为对方没有看过这些好电影感到惋惜,另一方面,我们也为对方能及早发现这些好电影感到高兴。那段时间我们经常一起看电影,有时找大家都喜欢看的,有时由他决定,有时由我决定,有时会找大家都未曾想过会看的,我们偶尔会发现,那些曾被认为不太可能会看的电影原来也别有一番风味,这不但开阔了我们的视野,也增进了我们的体验。
每个人的经历都不一样,有些经历甚至是相互矛盾的,你会把这种矛盾理解成非此即彼还是在某种程度上相互补充,很大程度上取决于你能否带着理解和包容来看待它。如果你把学习的过程看作从别人的经历或者你的新经历中吸取知识,那么理解和包容就是更好地学习的前提了。
《Ruby 101》从最初发布到现在已经4个月了,本文将会是这个系列的最后一篇,为了方便查阅,特意把前面文章的链接整理出来:
- 第一回:类和对象
- 第二回:重用、隐藏和多态
- 第三回:对象和方法
- 第四回:方法对象
- 第五回:动态编程
- 最终回:行为驱动(本文)
虽然《Ruby 101》要告一段落了,但Ruby的学习是不会停止的,往后我可能会关注的东西包括Silverlight + IronRuby、Google SketchUp + Ruby以及很久以前我就想玩的Ruby on Rails,这些内容都可能会出现在将来的文章里(也可能不)。