1. 序列数据
例如字符串、列表、字节序列、元组、XML元素、数据库查询结果等,在Python中用统一的风格去处理。例如,迭代、切片、排序、拼接等。
2. 容器序列与扁平序列
容器序列:容器对象包含任意类型对象的引用。如list、tuple和collections.deque. 但dict和set是容器但并非是序列。
扁平序列:存放的是同一种类型诸如字符、字节和数字而不是引用,是一段连续的内存空间。如str、bytes、bytearray、memoryview和array.array等。
3. 还可以按可变序列和不可变序列来分类
可变序列:list, bytearray, array.array, collections.deque, memoryview.
不可变序列:tuple, str, bytes.
4. 序列类型的通用功能
ABC为抽象基类(Abstract Base Class),虽然内置的序列类型不是直接从下图的Sequence和MutableSequence这两个ABC继承而来,但可以帮助我们了解序列数据包含了哪些通用的功能。
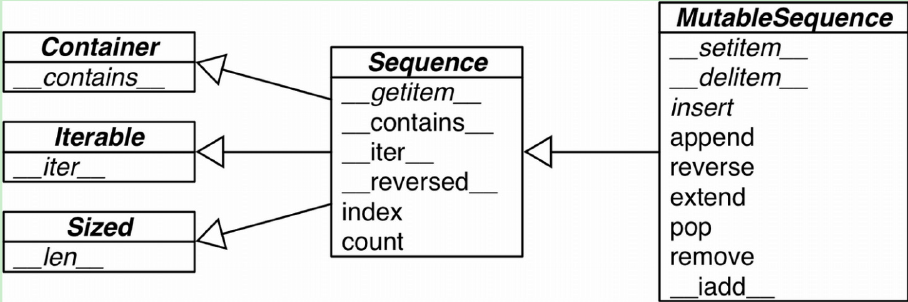
箭头从子类指向父类
from collections import abc
abc.Sequence
列表推导式和生成器表达式
5. 列表推导式(list comprehension)
列表推导把一个可迭代类型的序列过滤或者是加工,然后创建一个新的列表。可读性强。
"""
把字符串变成Unicode的一种写法
"""
symbols = 'AaBb'
codes = [ord(symbol) for symbol in symbols]
codes
注意:还有一个知识点,看博客园随笔中的“Python2中的列表推导式存在变量泄漏问题,在Python3中不存在”
6. filter+map+lambda与列表推导式比较
filter+map+lambda可以做的事,列表推导式也可以做,且可读性更好
symbols = '$&*@'
#列表推导式
within_ascii = [ord(symbol) for symbol in symbols if ord(symbol) < 127]
beyond_ascii
#filter+map+lambda
within_ascii = list(filter(lambda c: c < 127, map(ord, symbols)))
beyond_ascii
7.列表推导式与笛卡尔积
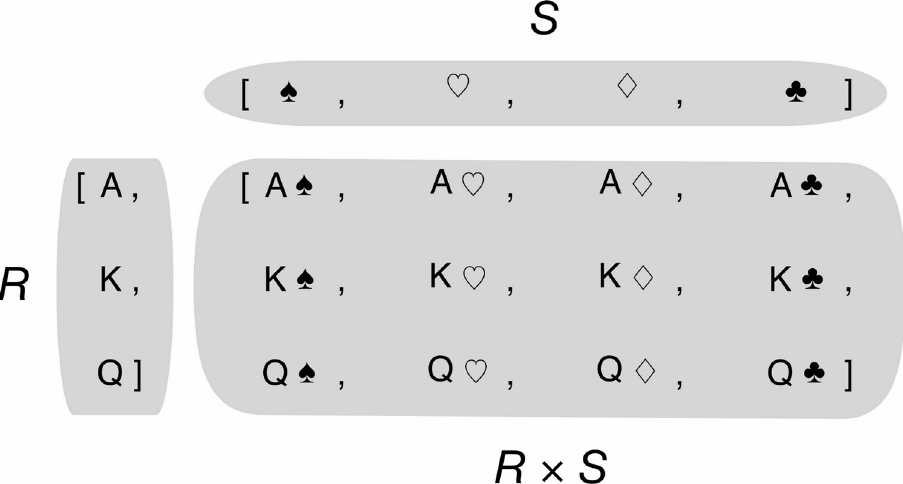
笛卡尔积是一个列表,长度(组合)为输入变量的乘积。此例为2 * 3 = 6
colors = ['black', 'white']
sizes = ['S', 'M', 'L']
tshirts = [(color, size) for size in sizes for color in colors]
print(tshirts)
8.生成器表达式(generator expression)
列表推导式唯一的作用是生成列表。如果想生成其他类型的序列,需要生成器表达式。
生成器表达式的语法跟列表推导式差不多,只不过把放括号换成圆括号。
#如果生成式表达是是一个函数调用过程中的唯一参数,不用括号括起来。
tuple(ord(symbol) for symbol in symbols)
#有两个参数,要用括号括起来
import array
array.array('I', (ord(symbol) for symbol in symbols))
和7.中的例子相比,生成器不会在内存中留下3*4长度的列表,每次在for循环时才生成一个组合。如果要计算各有100000个元素的列表的笛卡尔积,生成器表达式可以节省大量的内存空间。
把7.中的列表推导式的[]改成()即可变为生成器表达式
colors = ['black', 'white']
sizes = ['S', 'M', 'L']
tshirts = ((color, size) for size in sizes for color in colors)
print(tshirts)
使用生成器表达式生成笛卡尔积
colors = ['black', 'white']
sizes = ['S', 'M', 'L']
tshirts = ('Color: %s Size: %s' % (color, size) for color in colors for size in sizes)
for tshirt in tshirts:
print(tshirt)
#print()
#for tshirt in ('Color: %s, Size: %s' % (color,size) for color in colors for size in sizes):
#print(tshirt)
Python另一个重要的序列类型:元组(Tuple)
元组有两个作用:1.当作记录。 2.作为不可变的列表。
9.元组不仅仅是不可变的列表
元组还有记录作用,即它里面的元素的位置的信息是非常重要的
That is, 元组中的每个元素的位置是有关联的,提供信息。例如经纬度
#LAX:Los Angeles
lax_coordinates = (33.9416, -118.4085)
10. 拆包(Unpacking)
Unpacking works with any iterable object, called Iterable Unpacking.
10.1 平行赋值
#tuple(iterable)返回一个元组
#tuple((5,10))
t1 = tuple([5,10])
x, y = t1
x, y, z = t1 #Error
10.2优雅写法,不使用中间变量交换两个变量的值
a,b = b,a
#原理:a,b = b,a,右边进行Packing操作,返回元组
a = 1
b = 2
c = b, a # type(c):tuple
a,b = c #a==2, b==1
还可以用dis模块理解
https://stackoverflow.com/questions/27415205/how-pythons-a-b-b-a-works
未搞懂
10.3还可以用*运算符把一个可迭代对象拆开(Unpacking)作为函数的参数
t = (20, 8)
quotient, remainder = divmod(*t)
10.4 实现函数返回多个值。用元组返回,并Unpacking
os.path.split()返回(path, last_part)
import os
#_表示不需要使用的数据,不感兴趣的数据
#如果做的是国际化软件,_不是一个理想的占位符,因为它是gettext.gettext函数的别名。在其他情况下,_会是一个很好的占位符
#相关查阅:https://docs.python.org/3/library/gettext.html
_, filename = os.path.split('/home/allen/.ssh/idrsa.pub')
print(filename)
gettext.gettext
未搞懂
10.5Unpacking中,*可以帮助我们focus on可迭代类型的部分元素上,用来处理剩下的函数
函数用args来获取不确定数量的参数是一种classic的写法
在Python3中,被扩展到平行赋值中:
a, b, *rest = range(5)
#print(a, b, rest)
a, b, rest
a, b, *rest = range(2)
#print(a, b, rest)
a, b, rest
10.5具名元组(namedtuple)
factory function for creating tuple subclasses with named fields
此例的元组是当作记录来用的数据类型
from collections import namedtuple
#collections.namedtuple(typename, field_names, *, verbose=False, rename=False, module=None)
#field names可是是由数个字符组成的可迭代对象,或者是由空格分隔开的字段名组成的字符串。
City = namedtuple('City', 'name country popultaion coordinates')
#City = namedtuple('City', ['name', 'country', 'population', 'coordinates'])
tokyo = City('Tokyo', 'JP', '127M', (35.689722, 139.691667))
print(tokyo)
print(tokyo.country)
print(tokyo[2])
接上例,除了从普通元组继承来的属性外,namedtuple还有专有属性
最常用的:_fields类属性、类方法_make(iterable)和实例方法_asdict()
from collections import namedtuple
City = namedtuple('City', ['name', 'country', 'population', 'coordinates'])
tokyo = City('Tokyo', 'JP', '127M', (35.689722, 139.691667))
#类属性_fileds
print(City._fields)
Latlong = namedtuple('LatLong', 'lat long')
delhi_data = ('Delhi NCR', 'IN', 21.935, Latlong(28.613889, 77.208889))
#类方法_make(iterable)
delhi = City._make(delhi_data)
#实例方法_asdict()
print(delhi._asdict())
for key, value in delhi._asdict().items():
print(key + ':', value)
11. 列表与元组
如果把元组作为不可变的列表来用,在中文版电子书P84了解元组和列表的相似度。
切片
讨论切片的用法,实现的方法在第10章的一个自定义类里提到。Basically, 序列类型都支持切片操作。
12. 为什么切片和区间会忽略最后一个元素(左闭右开)
- 符合以0作为索引起始下标的传统。
- 当只有最后一个元素时,快速看出切片和区间里有几个元素: range(3)和my_list[:3]都返回3个元素。
- 快速计算起始和区间的长度 (stop - start), stop和start都是下标。l[5:7], 有7-5=2个元素。
- 利用任意一个下标把序列分割成不重叠的两部分,my_list[:x]和my_list[x:]
l = [10, 20, 30, 40, 50, 60]
#在下标2的地方分割
sub_l1 = l[:2]
sub_l2 = l[2:]
print(sub_l1, sub_l2)
13.对对象切片
seq[start:stop:step], step为步长,间隔取值,取负意味着反向。
s = 'bicycle'
s[::3]
s[::-1]
s[::-2]
14.多维切片和省略
中文版电子书P89
15.切片赋值
l = list(range(10))
print(l)
l[2:5] = [20, 30]
print(l)
del l[5:7]
print(l)
l[3::2] = [11, 22]
print(l)
l[2:5] = [1]
print(l)
#l[2:5] = 1
#如果赋值对象是一个切片,那么赋值语句的右侧必须是个可迭代对象。
#错误,就算只有一个值,都要转换为可迭代对象。
拼接序列
16.对序列使用+和*
+和*都会不修改原有的操作对象,而是构建一个全新的序列,所以会占用空间。
l1 = [1, 2, 3]
l2 = [4, 5, 6]
add_l = l1 + l2
print(l1, l2, add_l)
mul_l = l1 * 4
print(l1, l2, mul_l)
17. 使用*时,避免指向同一个引用
#错误示范,列表board包含3个指向同一个列表的引用。
row = ['_'] * 3
board = []
for i in range(3):
board.append(row)
board[1][0] = 'x'
print(board)
#正确示范
board = []
for i in range(3):
#每次迭代中都创建了一个新的列表
row = ['_'] * 3
board.append(row)
board[1][0] = 'x'
print(board)
18. 序列的+=和*=操作(增量操作)
+=对应的特殊方法是__iadd__, =对应的特殊方法是__imul__
例子:展示=在可变序列和不可变序列上的作用
#列表的*=操作
l1 = list(range(10))
print(id(l1))
l1 *=3
print(id(l1))
#元组的*=操作
t1 = tuple(range(10))
print(id(t1))
t1 *= 3
print(id(t1))
对可变序列例如列表进行增量乘法(原地乘法),列表的ID没变,新元素追加到列表上。
对不可变序列进行重复拼接操作的话,解释器把原来的对象中的元素先复制到新的对象里,然后追加新元素,所以ID改变了。
Note: str虽然是不可变序列,但CPython进行了优化。为str初始化内存时,程序为它留出额外的空间,在进行增量操作时,并不会涉及复制原有字符串到新位置这类操作。
19. 一个关于+=的谜题
t = (1, 2, [30, 40])
t[2] += [50, 60]
#原理:中文电子书P98
import dis
dis.dis('s[a] += b')
结果抛出异常,但是却赋值成功。用t[2].extend([50, 60])则没问题
得到两个教训:
- 不要把可变对象放在元组里。
- 增量赋值+=不是一个原子操作,虽然抛出异常,但完成了操作
序列排序
20. list.sort方法和built-in函数sorted
背后的排序算法是Timsort,它是一种自适应算法,会根据原始数据的顺序特点交替使用插入排序和归并排序,以达到最佳效率。
list.sort方法会原地排序,不会创建新对象,这就是为什么返回值是None。random.shuffle函数也遵循这个惯例。
返回None有个弊端就是不能形成Fluent interface(查wiki)
sorted(iterable)则返回一个列表。
演示sorted()常用的参数, key, reverse
fruits = ['grape', 'raspberry', 'apple', 'banana']
#1.
print('sorted(fruits): %s' % sorted(fruits))
#2.reverse
print('sorted(fruits, reverse=True): %s' % sorted(fruits, reverse=True))
#3.key=len
print('sorted(fruits, key=len): %s' % sorted(fruits, key=len))
sorted(fruits)
#4. key=len reverse=True
print('sorted(fruits, key=len, reverse=True): %s' % sorted(fruits, key=len, reverse=True))
#5. list.sorted()
print(fruits.sort())
key参数也能对一个混有数字和数值的列表进行排序。

用bisect模块管理已排序的序列
21. bisect包含两个主要函数,bisect和insort.
两个函数都利用二分查找在有序序列查找或者插入元素。
可以用bisect(haystack, needle)查找index, 再用haystack.insert(index, needle)来插入新值。但也可以用insort一步到位,并且后者速度更快。
例子1:根据一个分数,找到它所对应的成绩
import bisect
def grade(score, breakpoints=[60, 70, 80, 90], grades='FDCBA'):
#bisect(haystack, needle), 在haystack中找needle, needle前面的元素都小与或等于needle
index = bisect.bisect(breakpoints, score)
return grades[index]
#列表推导式
result_list = [grade(score) for score in [33, 99, 44, 66, 89, 70,100]]
print(result_list)
例子2. bisect.insort(a, x) 把x插入a,形成一个有序序列, 假设a已经有序
import bisect
import random
import time
SIZE = 10
#print(time.time())
random.seed(time.time())
my_list = []
for i in range(SIZE):
new_item = random.randrange(SIZE*2)
bisect.insort(my_list, new_item)
print('%2d ->' % new_item, my_list)
替换列表的数据类型
虽然列表广泛使用,但有些时候使用其他数据类型更好。
比如要存放1000万个浮点数的话,数组(array)的效率高,因为存的不是float对象,而是像C语言的数组一样,是字节。再比如,如果需要频繁地对序列做先进先出的操作,deque(双端队列)的速度应该更快。
Note; 虽然本章是讨论序列,但set不是序列,因为set是无序的。set专为检查元素是否存在做过优化。
22. 数组
- 若只需要一个包含数字的列表,array.array比list更高效。
- 数组支持所有可变序列的操作,如.pop, .insert, extend.
- 数组提供文件读取和存入文件的更快的方法,如.frombytes和.tofile.
例子1. 一个浮点型数组的创建,存入文件,从文件读取的程序
#1. 引入array类型
from array import array
from random import random
#2. 利用一个可迭代对象来建立一个双精度浮点型数组(类型码是'd'),这里的可迭代对象是一个生成器表达式
#Note: 生成器表达式与列表推导式的区别是,前者是(),后者是[]
floats_array1 = array('d', (random() for i in range(10**7)))
#3. 查看数组最后一个元素
print(floats_array1[-1])
#4. 打开文件流
fp = open('floats.bin', 'wb')
#5. 把数组存入一个二进制文件里
floats_array1.tofile(fp)
#6. 关闭文件流
fp.close()
#-----------------------------
#7. 创建一个双精度浮点空数组
floats_array2 = array('d')
fp = open('floats.bin', 'rb')
#8. 把浮点数从文件里读出来
floats_array2.fromfile(fp, 10**7)
fp.close()
#9. 查看最后一个元素
print(floats_array2[-1])
#10. 检查两个数组是否值相等
print(floats_array1 == floats_array2)
Note: 另一个快速序列化的模块是pickle. pickle.dump处理浮点数组的速度几乎和array.tofile一样快。不过前者可以处理几乎所有的内置数字类型,包含复数,嵌套集合,甚至用户自定义的类。
列表和数组属性和方法对比: 中文版电子书P110
从Python3.4开始,数组类型没有array.sort(),要给数组排序,得用sorted()重新新建一个数组:
a = array.array(a.typecode, sorted(a))
23. 内存视图(memory view) 未搞懂
中文版电子书P114
在不复制内容情况下,操作内存(二进制)。
24. NumPy和SciPy
上网学习
25. 队列
双向队列和其他形式的队列
我们可以把列表当作栈或者队列来用,把.append和.pop(0)合起来用,就能模拟Stack的“先进先出”的特点。但是增加或者删除列表第一个元素是很耗时的,要牵扯到列表里所有的元素。
collections.deque,中文电子书P118
列表和双向队列的方法对比,中文电子书P119
Python标准库也有对队列的实现 中文电子书P121
- queue,它提供的类适合用来控制活跃线程的数量。
- multiprocessing,实现了自己的Queue,跟queue.Queue类似,是给进程间通信用的。同时还有一个multiprocessing.JoinableQueue,让任务管理变得更方便。
- asyncio,里面的类受到queue和multiprocessing模块的影响,为异步编程的任务管理提供了便利。
- heapq,heapq没有队列类,而是提供了heappush和heappop方法,把可变序列当作堆队列或者优先队列使用。
- 序列类型str和二进制序列,在第4章专门介绍。
总结
中文电子书P123