https://zhuanlan.zhihu.com/p/24996631
众所周知,zookeeper与分布式有着千丝万缕的联系。它虽然源自于hadoop,但目前zookeeper脱离hadoop的范畴开发分布式应用越来越普遍,想到这里,不禁为hadoop扼腕叹息。
那么Zookeeper究竟是什么呢?
从他的名字就可以看出来 ------ 动物园管理员,就相当于是把集群中的客户端当作许多小动物,管理员的作用就是维持他们的秩序,提供他们食物,当某小动物出现状况,如生病、脱毛等一系列现象,管理员自然会知道,并传达给其他动物这个消息,其他动物就不会再拉着这个小动物玩,会让它好好休息。
好吧,这个例子十分生硬。
简单来说,zookeeper = 通知机制 + 文件系统。
- 通知机制
相当于上面那个例子,客户端注册监听它关心的目录节点,当目录节点发生变化,如数据改变、被删除、子目录节点增加删除时,zookeeper会通知客户端。 这时客户端就可以根据传过来的信息采取一系列的操作。
- 文件系统
zookeeper维护一个如下图的文件结构
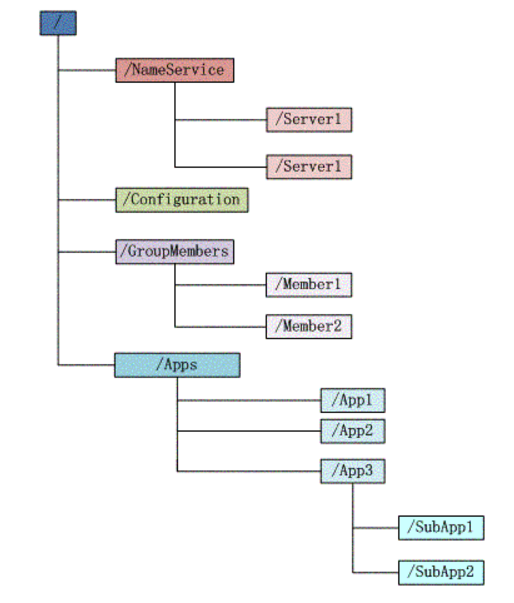
- 每个子目录项如 NameService 都被称作为 znode,有如下四种类型:
- PERSISTENT - 持久化目录节点:客户端与zookeeper断开连接后,该节点依旧存在
- PERSISTENT_SEQUENTIAL - 持久化顺序编号目录节点:客户端与zookeeper断开连接后,该节点依旧存在,只是Zookeeper给该节点名称进行顺序编号
- EPHEMERAL - 临时目录节点:客户端与zookeeper断开连接后,该节点被删除
- EPHEMERAL_SEQUENTIAL - 临时顺序编号目录节点:客户端与zookeeper断开连接后,该节点被删除,只是Zookeeper给该节点名称进行顺序编号
2. znode 可以有子节点目录 (临时节点除外),并且每个 znode 可以存储数据zookeeper 的客户端和服务器通信采用长连接方式,每个客户端和服务器通过心跳来保持连接,这个连接状态称为 session,如果 znode 是临时节点,这个 session 失效时,znode 也就删除了znode可以被监控,实现上述通知机制
我们能用Zookeeper做什么?
- 统一命名服务:说白了,zookeeper会帮我们的文件起名,起的名字还挺好听,还不会重复,便于识别跟记忆,是不是很棒
- 配置管理:简单点,改变一台机器的配置,其他机器也会跟着改变
- 集群管理:监听是否有机器退出和加入、动态选举Master(最小节点法,最大数据法)
-
队列管理
1、同步队列,当一个队列的成员都聚齐时,这个队列才可用,否则一直等待所有成员到达,本文最后将实现此队列demo
2、队列按照 FIFO 方式进行入队和出队操作。
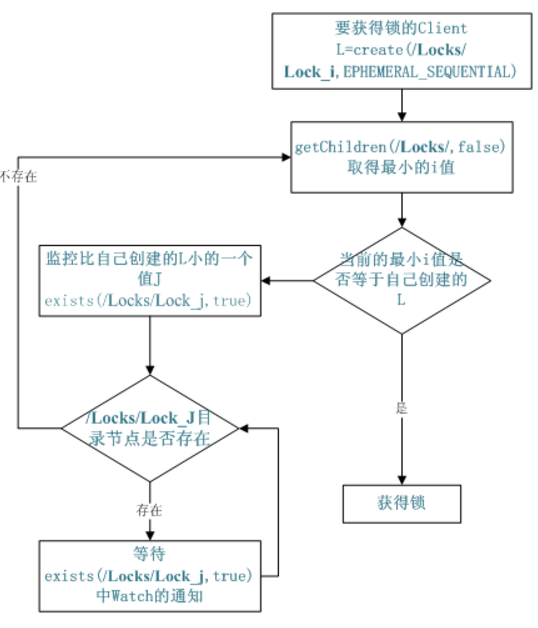
- 实现分布式锁,流程如下
Zookeeper的基本概念
角色
1.领导者(Leader):进行投票的发起和决议,更新系统状态
2.学习者(Learner)
- 跟随者(Follower):接受客户端请求并向客户端返回结果,在选主过程中参与投票
- 观察者(Observer):接收客户端的连接,将写请求转发给leader节点。但Observer不参加投票,只同步leader状态。Observer的目的是为了扩展系统,提高读取速度
3.客户端(Client):请求发起方
session
zookeeper会为每个client分配一个session,类似于web服务器一样。针对session可以有保存一些关联数据
- Global session 全局session,在每个server上都存在
- local session 只在当前请求的server上存在,但只能进行读操作,要是要进行写操作,就得升级为全局session
Zookeeper的工作原理
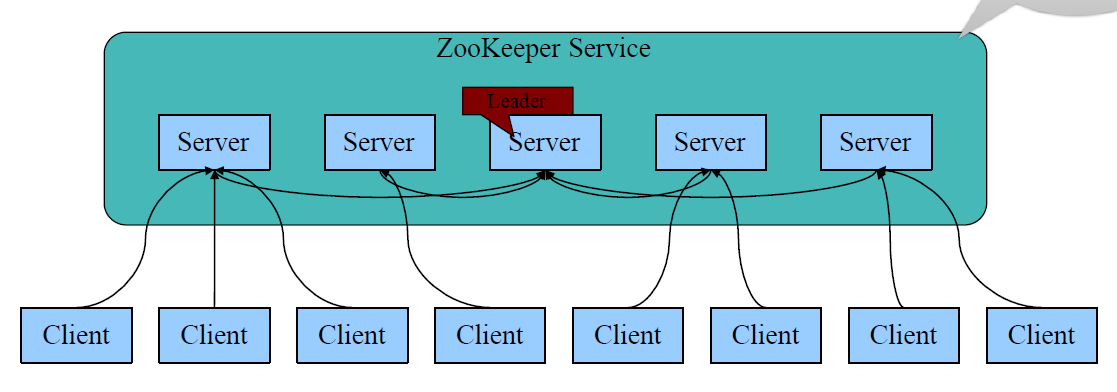
- zookeeper集群上每个server数据一致,leader在集群启动时选举,如图
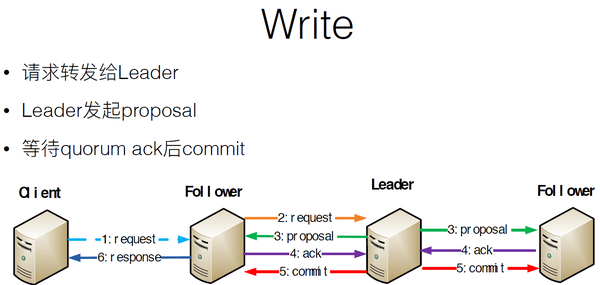
- 写操作时,请求发给某server,再由server转发给leader,leader给每个server发送投票消息,每个server把投票结果传给leader,要是有半数server同意此请求,leader就会commit到每个服务器执行写操作,流程如下:
- 写操作流程中,observer角色只负责转发请求,不参与投票,如图:
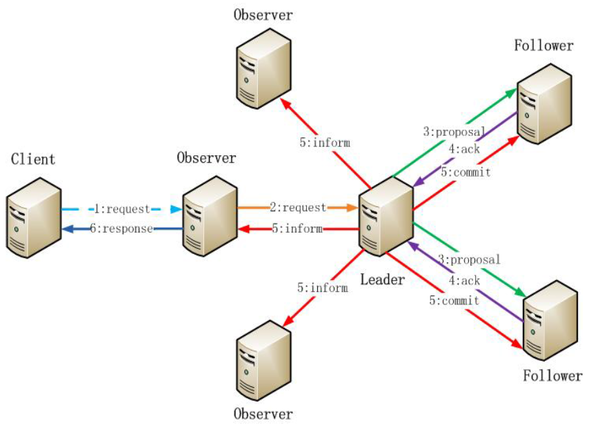
- 一个follower挂了,修复好之后会和leader通过一致性协议修复follower数据,达到每个server上数据最终一致
- 存储数据时,过一段时间,zookeeper就会把所有server的数据镜像写出,然后把每个server上的数据删除,保证了每个server的容量
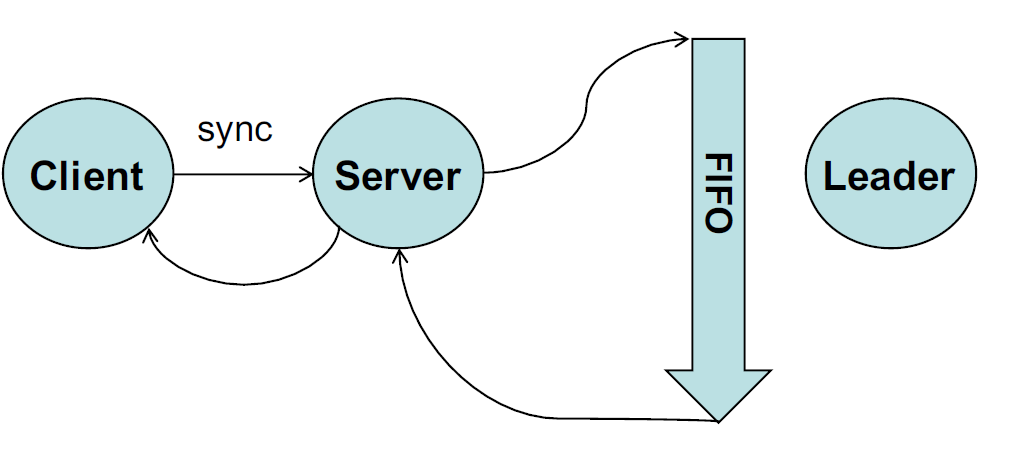
- 在某一台follower写入了某数据的同时,读另一台follower刚刚写入的信息不一定成功,因为每台server数据同步会有少许间隔,所以说是最终一致性。不过session肯定是强一致性,通过修改数据后传回lastZxid来判断。若要实现强一致读,sync读两次实现实现,原理如下:
- Watcher的特性:只通知改变事一次性、触发后失效、session内有效
Zookeeper实现同步队列Demo
Demo现实一种同步的分步式队列,当定义的队列成员都聚齐时,这个队列才可用,否则一直等待所有成员到达。
实现思路
创建一个父目录 /queue,每个成员都监控(Watch)标志位目录/queue/start 是否存在,然后每个成员都加入这个队列,加入队列的方式就是创建 /queue/x(i)的临时目录节点,然后每个成员获取 /queue 目录的所有目录节点,也就是 x(i)。判断 i 的值是否已经是成员的个数,如果小于成员个数等待 /queue/start 的出现,如果已经相等就创建 /queue/start。
public static void main(String[] args) throws Exception {
//模拟app1通过zk1提交x1,app2通过zk2提交x2,app3通过zk3提交x3
doAction(1);
doAction(2);
doAction(3);
}
//以此集群的3台机器上加入某成员
public static void doAction(int client) throws Exception {
String host1 = "zookeeperServer1:2181";
String host2 = "zookeeperServer2:2181";
String host3 = "zookeeperServer3:2181";
ZooKeeper zk = null;
switch (client) {
case 1:
zk = connection(host1);
initQueue(zk);
joinQueue(zk, 1);
break;
case 2:
zk = connection(host2);
initQueue(zk);
joinQueue(zk, 2);
break;
case 3:
zk = connection(host3);
initQueue(zk);
joinQueue(zk, 3);
break;
}
}
// 创建一个与服务器的连接
public static ZooKeeper connection(String host) throws IOException {
ZooKeeper zk = new ZooKeeper(host, 60000, new Watcher() {
// 监控所有被触发的事件
public void process(WatchedEvent event) {
if (event.getType() == Event.EventType.NodeCreated && event.getPath().equals("/queue/start")) {
System.out.println("Queue has Completed.Finish testing!!!");
}
}
});
return zk;
}
//初始化队列
public static void initQueue(ZooKeeper zk) throws KeeperException, InterruptedException {
System.out.println("WATCH => /queue/start");
//当这个znode节点被改变时,将会触发当前Watcher
zk.exists("/queue/start", true);
//如果/queue目录为空,创建此节点
if (zk.exists("/queue", false) == null) {
System.out.println("create /queue task-queue");
zk.create("/queue", "task-queue".getBytes(), Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
} else {
System.out.println("/queue is exist!");
}
}
//成员加入队列
public static void joinQueue(ZooKeeper zk, int x) throws KeeperException, InterruptedException {
System.out.println("create /queue/x" + x + " x" + x);
zk.create("/queue/x" + x, ("x" + x).getBytes(), Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL);
isCompleted(zk);
}
//判断队列是否已满
public static void isCompleted(ZooKeeper zk) throws KeeperException, InterruptedException {
//规定队列大小
int size = 3;
//查询成员数
int length = zk.getChildren("/queue", true).size();
System.out.println("Queue Complete:" + length + "/" + size);
if (length >= size) {
System.out.println("create /queue/start start");
zk.create("/queue/start", "start".getBytes(), Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
}
}
控制台打印: 在linux上查看queue节点:
在linux上查看queue节点:
因为我们创建的任务节点是临时节点,而start节点是持久节点,所以最终我们查看queue节点时,仅有start节点存在,临时节点已经被zookeeper自动删除。